最近在上 Hamel + Shreya 的 AI Evals For Engineers & PMs 課程,這應該是市面上最深入探討 AI 應用評估的課程了。以下根據網上有公開的內容,整理一篇精華內容(大約是課程的前1/4內容)。
如果你正在開發 AI 應用,應該都遇過這種情況:產品做出來了,看起來還行,但總覺得哪裡怪怪的。使用者抱怨一些奇怪的問題,但你不知道從何改起。這篇文章要介紹的就是評估和錯誤分析 Error Analysis 系統性方法。
為什麼 LLM 評估這麼難?
傳統的機器學習評估方法在 LLM 時代面臨全新挑戰:
- 輸出的非結構化特性:不像傳統 ML 有明確的數值指標(如準確率、召回率),LLM 輸出的是開放式文本,難以用簡單的指標衡量
- 主觀性問題:什麼是「好的」回應往往高度依賴具體情境和使用者期望
- 邊緣案例層出不窮:你測試了 100 種情況,使用者偏偏會用第 101 種方式來問
- 持續對話的複雜性:不像一問一答就結束,真實對話可能持續幾天甚至幾個月
三大鴻溝難關
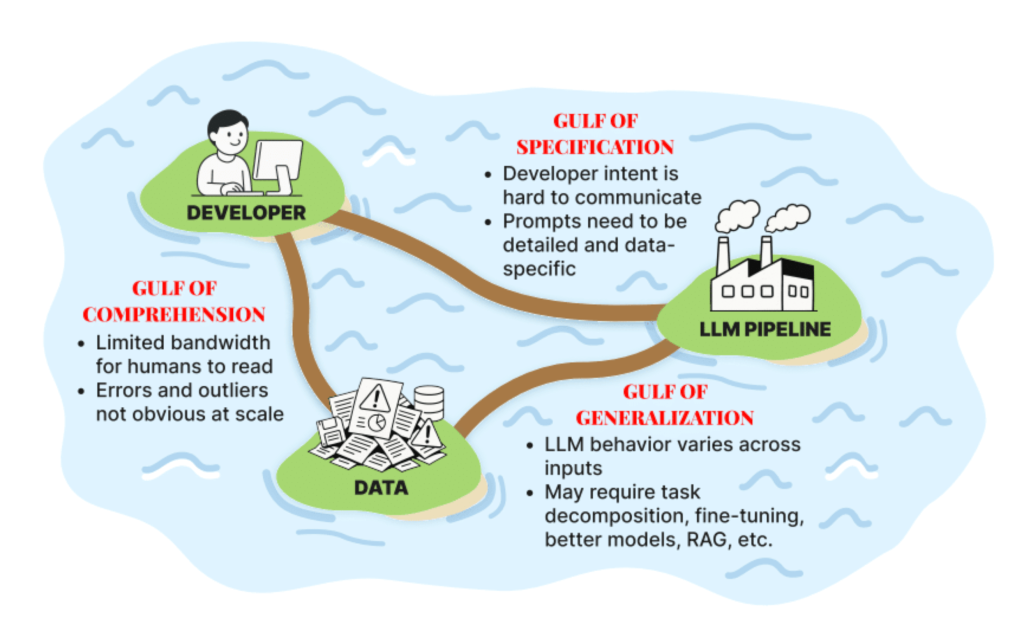
Shreya Shankar 提出了一個很有洞察力的比喻,開發 AI 應用就像要跨越三個大鴻溝:
1. 理解鴻溝: 搞懂到底發生什麼事
理解鴻溝是關於理解數據。當我們說「看數據」時,產生的成果是你腦中對數據內容和失敗模式的知識。這就像偵探辦案,你需要:
- 真正去看使用者如何使用你的產品,理解他們實際如何與系統互動
- 觀察人們每天向你的產品提出什麼問題,識別他們想要解決的痛點
- 找出 AI 在哪些地方會出錯,識別數據中的模式和異常
- 發現隱藏的失敗模式
- 理解不同數據群集的特徵
- 挖掘使用者真正的需求
NurtureBoss 的 Jacob Carter 對此深有體會:「當我們發布產品時,對於正在發生的事情來說,這對我們來說是一個巨大的黑盒子。」但在查看了數千次對話後,他發現:「能夠實際看到人們每天向你的產品詢問什麼,識別出他們尋求解決哪些問題,這將為你建立產品路線圖。」
2. 規範鴻溝: 把話說清楚
這是最多人栽跟頭的地方。你以為你的指令很清楚,但 AI 的理解可能完全不一樣。如何成為一個好的溝通者?因為我們必須以極其詳細的方式向 LLM 指定所有內容,使其理解必須明確無歧義,這非常困難。
常見的錯誤:
- 只給一個例子:很多人學會 few-shot prompting 後,只給一個例子。模型可能會過度關注該舉例,導致所有回答都長得很像
- 指令過度規範:例如寫「請當一個值得信任的顧問」,結果 AI 變得太直白,甚至開始批評使用者!
- Prompt 越寫越長:最後變成落落長的作文。其實很多時候,刪掉一半反而更好用。因為我們不斷嘗試解決規範鴻溝,試圖讓它越來越具體,實際上忘記了重構我們的 prompts
Jacob 分享了一個 AI 時間感混亂的普遍問題,客戶說『我想安排兩週後看房』,AI 會回答『好的,那是2月29日』但根本不是兩週後!或者有人說要安排3月1日看房,AI 卻去找2020年3月1日的空檔。
3. 泛化鴻溝: 確保到處都能用
這是傳統的機器學習問題:「我已經寫好了 pipeline,但它能泛化到我的數據嗎?它能泛化到其他人的數據嗎?如果我在實際環境中部署它,它會工作嗎?」
在你的測試環境跑得好好的,一上線就各種出包。總是有些邊邊角角的情況你沒想到。在實際使用中,這些奇怪的情況一定會出現。
什麼是改進循環? 分析、測量、改進
LLM 應用改進的核心是一個三步驟循環:
- 分析(Analyze):進行錯誤分析
- 測量(Measure):大規模測量
- 改進(Improve):基於測量結果進行改進
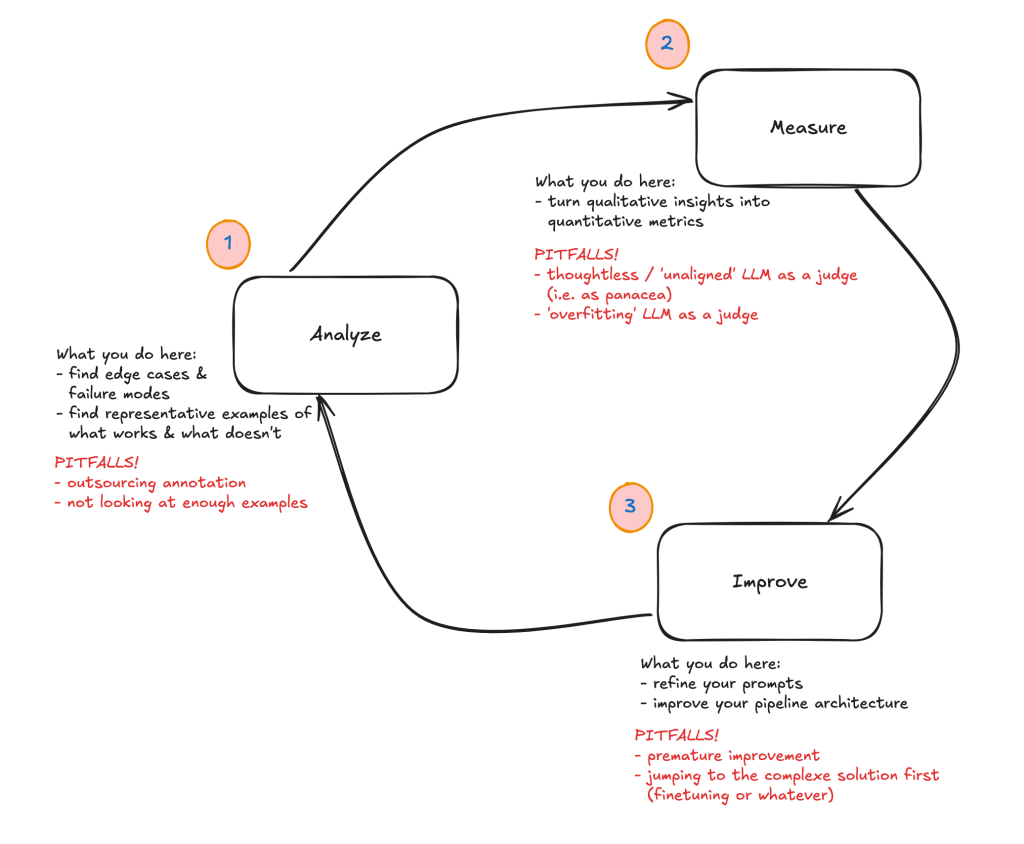
什麼是錯誤分析 Error Analysis ?
第一步的錯誤分析是整個流程的關鍵。重點就是透過分析找到有哪些失敗模式,後續步驟直接針對這些失敗模式來進行量測及改進。
編按: 針對沒有標準答案(指單選、多選等有固定答案)的評估,這裏不同於常見的 G-Eval 評估方式採用正面表列,根據你的 Criteria 做評估量測打分(例如1~5分有多符合)。這裏教的方法是先做錯誤分析,拿到具體的負面表列後,後續再針對 “每一種” 失敗模式都來做評估量測和改進。
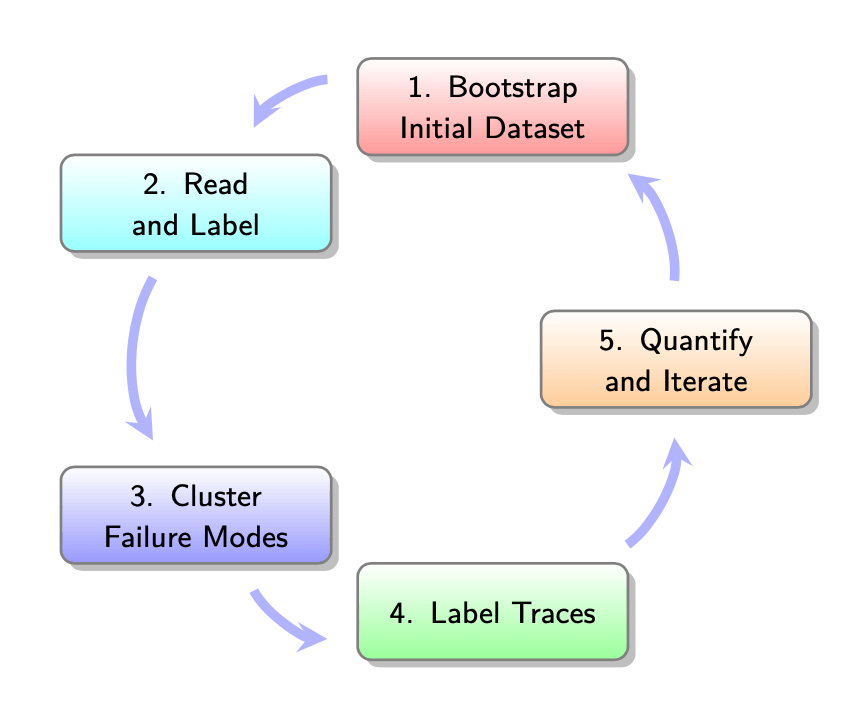
1. 創建初始數據集:100 個樣本
目標是得到 100 個跨越不同使用維度的輸入。為什麼是 100 個?「沒什麼特別原因,就是個不多不少的數字,足夠讓你開始了。」
具體執行步驟:
- 維度思考:在你的應用可能期望經歷的維度進行採樣,想出至少三個維度。可以從功能、角色、查詢複雜性或使用場景的角度來思考
- 組合生成:生成這三個維度的 50 個組合,過濾掉不合理的
- 查詢生成:手寫或使用 LLM 幫助生成完整的 100 個現實查詢
2. 檢視資料
查看追蹤記錄,並在記錄上寫筆記。查看 100 個數據項目中的每一個,並對你在數據中觀察到的失敗模式進行觀察。
關鍵原則:
- 讓類別從數據中自然浮現,而不是帶著預設想法
- 不需要做根本原因分析(why 發生),只需關注觀察到的行為和模式
- 預計花費時間:「這是你將花費 80% 時間的地方,對於 100 個追蹤記錄可能需要大約一個小時」
另外,NurtureBoss 的經驗顯示,如果自己開發的檢視工具更能大幅提升效率:
- 能清楚顯示對話全貌:用戶說了這個,AI 說了那個,AI 呼叫了工具。這是 AI 從工具得到的回應
- 快速標記和註解:標記這個對話是好是壞,然後快速輸入註解解釋原因
- 快速分類失敗模式:分類這是 看房安排錯誤、未觸發轉接、重複詢問…,然後系統統計哪類錯誤最常發生
3. 分群歸類
看完所有案例後,把類似的問題放在一起。你可以用 AI 幫忙,但最後一定要自己檢查。Eugene 說「我把所有東西都先讓 AI 跑一遍當草稿。AI 會給出不錯的分類,但最後總是需要 5-10% 的人工調整。」
通過將相似的失敗模式分組,建構和合併出你應用的失敗分類法。
實用建議:
- 嘗試創建二元的失敗模式(可觀察到的 True 或 False ),這樣更容易有明確的定義,比較簡單
- 始終手動審查、改進和自行定義這些失敗模式
4. 標記更多追蹤記錄並迭代
在這個過程中,不要擔心你的失敗模式命名或定義可能會演變。這是標註數據時常見的現象,隨著你檢查新的輸出,標準會漂移。實際上你應該更高興,因為這反映了你對數據理解的加深。
總結
不要迷信通用的評估指標,例如簡潔性評分、幻覺評分等通用指標,那些都是無意義的學術練習。Jacob 的經驗證實了這點,他們透過錯誤分析,將日期處理的成功率從 33% 提升到 100%,這種具體、可測量的改進才是真正有價值的。 你的系統有其獨特性,通用工具和指標往往無法完美適用。專注於你的實際痛點,而不是追求漂亮的通用分數。
LLM 應用的評估和錯誤分析不僅是技術問題,更是一種思維方式的轉變。成功的關鍵不在於使用什麼工具或框架,而在於建立一個持續學習和改進的文化。透過系統化的方法、正確的心態和持續的努力,可以將你的 LLM 應用從概念驗證推進到真正改變用戶生活的產品。
參考和推薦內容
課程學員 Alex S. 的心得文章:
兩場 Hamel 的 Youtube 錄影:
- Nurture Boss 訪談案例,這是我整理逐字稿後的文章
- Hamel + Shreya 和 Eugene 的訪談,這是我整理逐字稿後的文章
另外推薦 Hamel 的文章:
- A Field Guide to Rapidly Improving AI Products,重點包括:
- 錯誤分析才是王道,別沈迷漂亮的 dashboard 通用指標
- 最重要的投資:客製化的數據檢視介面
- 讓領域專家直接寫 Prompt
- 用合成數據起步
- 保持評估系統的可信度,用二元判斷取代模糊分數
- 路線圖要數實驗,不是數功能
- AI Evals 課程 FAQ,重點包括:
- 錯誤分析 (Error Analysis) 是王道
- 自建評估介面比現成工具好
- 二元評估 > 李克特量表(1-5分)
- RAG 沒死,只是要用對方法
- 別用現成的通用指標,這些指標對大部分 AI 應用都沒用