* 舊版 [[Andrej Karpathy's Intro to Large Language Models]]
# New 3h31m video on YouTube: Deep Dive into LLMs like ChatGPT
https://www.youtube.com/watch?v=dWr1eTeK6p4
https://x.com/karpathy/status/1887211193099825254
## Part 1: Pre-training 得到 Base model "internet document simulator"
* Pretraining 00:01:00
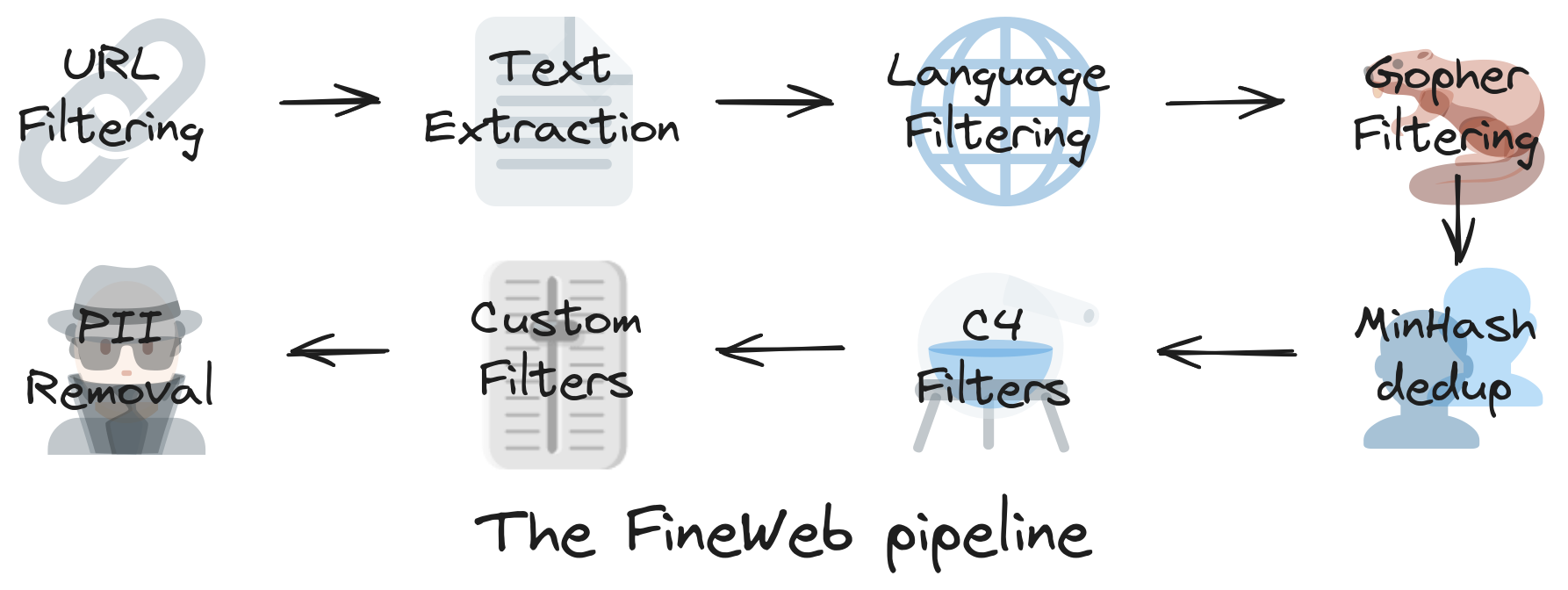
* Step 1: download and preprocess the internet
* FineWeb https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
* CommonCrawl
* 
* Step 2: tokenization 00:07:47
* Convert between raw text into sequences of symbols(tokens)
* 文字 -> utf-8 -> bits -> bytes -> tokens (用 BPE 算法,例如 cl100k_base 有 100,277 種 tokens)
* examples:
* ~5000 unicode characters
* ~= 40000 bits (2 possible tokens)
* ~= 5000 bytes (256 possible tokens)
* 1300 GPT-4 tokens (100,277 possible tokens)
* https://tiktokenizer.vercel.app/
* Step 3: neural network training 00:14:27
* 從 dataset 中一直挑 4k or 8k or 16k 的 context 來訓練 (看你有多少運算資源),不斷訓練去調整 weights
* 調整 weights 就會得到不同的 output 機率預測
* ![[Pasted image 20250305222435.png]]
* ![[Pasted image 20250305222853.png]]
* 視覺化 https://bbycroft.net/llm
* 這種結構叫做 Transformer
* inference 推論階段 00:26:01
* to generate data, just predict one token at a time
* 本質上有隨機性,最後得到的重組版本,和原本訓練資料不會完全一樣
* 推論就是不斷從機率分佈中,預測下一個詞
* ![[Pasted image 20250305224240.png]]
* 和 ChatGPT 對話時,是和已經訓練好參數已經固定的模型做對話,讓模型做推論
* 案例 GPT-2: training and inference 00:31:09
* GPT: generative pre-trained transformer
* 很中意,因為這是首個整合現代 stack 的 LLM
* GPT-2 was published by OpenAI in 2019
* Paper: "Language Models are Unsupervised Multitask Learners"
* Transformer neural network with:
* 1.6 billion parameters
* maxium context length of 1024 tokens
* trained on about 100 billion tokens
* My reproduction with llm.c: https://github.com/karpathy/llm.c/discussions/677
* 為何現在做可以把訓練成本降到 100 美金
* 因為 dataset 的品質提升了
* 主要是硬體變更快了
* 軟體也更有效率了
* demo 訓練過程
* ![[Pasted image 20250305234325.png]]
* 租雲端 8 x H100 在 https://lambdalabs.com/ 跑
* 到此產出 **Base model 是 internet text token simulator**
* 這還不好用,不是 AI 助理
* 目前只會重新拼揍網路上的內容
* Llama 3.1 base model inference 00:45:45
* "Base" models in the wild
* OpenAI GPT-2 (2019): 1.6 billion parameters trained on 100 billion tokens
* Llama 3 (2024): 405 billion parameters trained on 15 trillion tokens
* What is release of a model?
* The code for running the Transformer (e.g. 200 lines of code in Python)
* The paramsters of the Transformer (e.g. 1.6 billion numbers)
* 有釋出了 Base 和 Instruct 版本
* https://hyperbolic.xyz/ 這家公司有提供 llama 3.1 base model
* https://app.hyperbolic.xyz/models/llama31-405b-base-bf-16
* base model 還不是人工助理,只是 token autocomplete
* 但 base model 已經學習到許多世界知識,儲存在參數之中,壓縮在權重裡面,就像是一個 zip 有損檔案
* 透過適當的提示,可以把知識引出來。若是網路上常出現的資料,會比較準確。因為知識不是完整儲存的,而是模糊的,而是透過統計機率來描述的。
* 例如直接複製 wikipedia 的一個段落,會開頭直接引出一模一樣的內容,但輸出一段後才會偏離
* 針對wikipedia 這種優質資料,訓練時會讓他更多次反覆學習,導致會記憶的更好更完整
* 如果是完全沒學過的知識,就是用猜的了,叫做幻覺,只是用機率去做猜測
* base model 透過 prompt design 還是可以有用,例如用 few-shot prompt
* in-context learning
* 需要模擬對話當作 few-shot prompt,就可以做出 AI assistant 對話
* ![[Pasted image 20250306003247.png]]
* The "'psychology" of a base model
- It is a token-level internet document simulator
- It is stochastic / probabilistic - you're going to get something else each time you run
- It "dreams" internet documents
- It can also recite some training documents verbatim from memory ("regurgitation")
- The parameters of the model are kind of like a lossy zip file of the internet
- => a lot of useful world knowledge is stored in the parameters of the network
- You can already use it for applications (e.g. translation) by being clever with your prompts
- e.g. English:Korean translator app by constructing a "few-shot" prompt and leveraging "in-context learning" ability
- e.g. an Assistant that answers questions using a prompt that looks like a conversation
- But we can do better...
- Base 模型的「心理學」
- 它是一個以 Token 為單位的網路文件模擬器
- 它具有隨機性/機率性,每次執行都可能生成不一樣的結果
- 它會「夢想」出網路上的文件內容
- 它也能直接背誦出部份訓練文件的原文(「反芻」)
- 這個模型的參數有點像互聯網的有損壓縮檔
- 也就是說,許多有用的世界知識都存放在網路的參數之中
- 其實,光靠聰明地撰寫 Prompt,你已經可以把它應用在各種情境(例如翻譯)
- 舉例來說,可以用「少量範例教學」(few-shot)以及「上下文學習」(in-context learning)的能力,打造一個英-韓翻譯應用
- 再比如,透過看起來像一段對話的 Prompt,做成一個能回答問題的助理
- 不過,我們還能做得更好……
## Part 2: Post-training: Supervised Finetuning 得到 SFT 模型 (An assistant)
https://www.youtube.com/watch?v=dWr1eTeK6p4
- [ ] Part 2: post-training
* 00:59:23 pretraining to post-training
* 訓練成本會比 pre-training 低得多,因為 dataset 小得多
* 基本上訓練流程跟算法是很類似的
* base model 要訓練好幾個月,微調只需要幾個小時
* 1:01:06 post-training data (conversations)
* 建立對話資料集,數十萬筆,人工標記準備
* ![[Pasted image 20250315135821.png]]
* 格式 ![[Pasted image 20250315173119.png]]
* **重點是所有對話內容都會變成單一的 one-dimensional token 序列**
* Training language models to follow instructions with human feedback https://arxiv.org/abs/2203.02155
* 首次用對話來訓練微調 LLM,全靠人類準備訓練資料
* paper 裡面有寫人類應該如何標記回答: Be helpful, Be truthful, Be harmless 並因此模型有此特質
* OpenAI 沒開發 dataset,這另有人做的開源版本 https://huggingface.co/datasets/OpenAssistant/oasst1
* 現在可以靠現成的 LLM 模型來合成對話資料後,人類再修改調整
* https://github.com/thunlp/UltraChat 對話資料庫,大部分是合成資料的
* ![[Pasted image 20250315173050.png]]
* 跟 AI 對話,是模型根據訓練資料的統計匹配結果,去模仿人類標記資料,這些資料由公司制定規則所指導人類寫出的
* 如果你的問題在 dataset,那麼 AI 的輸出有可能會一模一樣
* 01:20:32 hallucinations, tool use, knowledge/working memory
* 模型心理學,特殊的認知現象
* 幻覺: 憑空編造沒有根據的資訊
* 原因: 人類標注的 dataset 裡面都是肯定的答案,因此模型會模仿這樣的回答行為: 給你最有可能的正確答案,而不會回答不知道
* 每次問,還會給不一樣的答案
* 最新的模型有改善
* ![[Pasted image 20250315192508.png]]
* 解決方式一: Meta 3 的改善方式 https://arxiv.org/abs/2407.21783
* 有個驗證流程,反覆測試模型知道哪些事實和知識範圍
* 然後針對模型不知道的問題,增加 dataset 要回答不知道
* 這招很有效,因為模型本身其實已經有自我認知,只是需要被教可以回答不知道
* 解決方式二: 可以 search
* 模型對接觸過的訓練資料,如果看得不夠多遍,會只是模糊的印象
* 訓練模型產生 <SEARCH_START>search query<SEARCH_END> 來啟動搜尋功能
* 看到此 tokens 時,就會暫停生成,先去搜尋
* 搜尋結果塞回來 context window,然後模型再繼續生成
* context window 就是 working memory,也會一起進到模型的神經網路被看見,喚起模糊的記憶
* 需要數千筆就可以在訓練模型學會這個工具的運作
* ![[Pasted image 20250315192518.png]]
* Vague recollection vs. working memory
* Knowledge in the parameters == Vague recollection (e.g. something you read 1 month ago)
* Knowledge in the tokens of the context window == Working memory
* 「模糊的回憶」與「工作記憶」
- 存在於模型參數中的知識 == 模糊的回憶(例如:你在一個月前讀到的資料)
- 存在於對話上下文視窗中的知識 == 工作記憶
![[Pasted image 20250315194317.png]]
* 01:41:46 knowledge of self 自我認知
* 例如有人問AI說: What model are you? Who build you? Who are you?
* 對模型來說,這是沒有意義的問題
* 例如有些模型會回答 build by OpenAI,但這不表示就是 OpenAI 做的
* 只是因為模型被訓練過回答這種問題,而網路上已經很多這種 OpenAI 對話資料
* 如何修正? 需要人為設計:
* 在開源模型 https://huggingface.co/datasets/allenai/tulu-3-sft-olmo-2-mixture 完全開源
* 在 SFT 資料中,有個 https://huggingface.co/datasets/allenai/olmo-2-hard-coded 有準備自我認知資料 240組
* 或是在 system prompt 中,先寫死自我認知,寫死模型的簡要資訊,可以介紹自己
* 01:46:56 models need tokens to think 模型需要 tokens 來思考解題
* ![[Pasted image 20250315205147.png]]
* 以上兩種訓練資料,左邊會很糟,右邊比較好
* 因為左邊答案 3 太早出來了,變成你在訓練模型一步就猜出答案
* 右邊將計算過程分散在整個輸出,讓模型一步一步推導出來答案,每一步都是簡單的推測
* 也因此模型學會一步一步處理,這些中間步驟是模型需要的,不然就無法算出最後答案
* 無論是訓練或實際運作,模型都是從左到右依序處理一串符號 tokens
* ![[Pasted image 20250315205927.png]]
* 預測每一個 token 的運算量是大致固定的 (只會隨著輸入 tokens 長度增加會微幅增加)
* 不會有為了解決困難問題而讓單一 token 增加運算量
* 因此複雜問題需要的運算量,需要透過分配到多個 tokens
* 如何刁難?
* 難一點的問題,要求不要思考(answer the question in a single token. i.e. immediately just give me the answer and nothing else)
* 這樣就會答錯
* 不過中間步驟也可能出現數學計算,就像用腦子心算
* 推薦 Use Code,使用 Python 來算比較精準
* 這也是一種工具
* 02:01:11 tokenization revisited: models struggle with spelling
* 計數問題,也是模型不太會的事情
* 例如: How many dots are below? .................................................................................................................................................................................
* 因為模型看的是 tokens !!!
* 如果改用 Code Interpreter 就可以
* 還有很多認知層面問題,技術盲點
* 拼字相關 spelling tasks 問題都不會有好表現,因為模型看到的是 tokens
* 例如: Print back the following string, but only print every 3rd character, starting with the first one. "Ubiquitous"
* e.g. 請重複以下文字,但只印出每第三個字母: abcabcabcabc
* 若 Use Code 就可以解答正確是 cccc
* 用 tokens 是為了提升效率。很多人想拋棄 tokens 設計,只用 chacter 或 bytes 層級來做模型。不過這樣會變沒有效率..... 還不知道怎麼辦
* 例如熱門問題: How many 'r' are there in 'strawberry' ?
* 人們覺得 AI 模型連奧數都可以,為啥這會算錯
![[Pasted image 20250315220207.png]]
* 02:04:53 jagged intelligence 一些很簡單卻答錯的問題
* 例如 What is bigger 9.11 or 9.9?
* 讓人搞不懂
* 有 paper 研究認為是因為 "聖經章節"
* 因為 9.11 節的確排在 9.9 之後
* 因此模型混亂了
* 仍無法被完全理解原因
* LLM 是個神奇的機率系統: 這是瑞士起司
![[Pasted image 20250315220930.png]]
## Part 3: Post-Training: Reinforcement Learning 得到 RL 模型
* 02:07:28 supervised finetuning to reinforcement learning
* ![[Pasted image 20250316011152.png]]
* 讓大型語言模型 (LLMs) 去上學 https://ihower.tw/blog/archives/12633
* 練習題,你要自己動手做,自己找出解題方法,只有正確答案可以驗證
* 02:14:42 reinforcement learning 強化學習
* ![[Pasted image 20250316020747.png]]
* 這裡有四種解法,human labeler 到底要用哪一種做訓練?
* 設法得到正確答案,但也希望過程容易理解
* 每一個 token 預測不應該跳太快,例如 解法4,直接從 = 號就接答案 3,太快了
* 但還是很難判斷 1,2,3 到底哪些步驟對 LLM 難度適中? 畢竟人類跟 LLM 思考方式不同
* 假設先不管過程是否人類容易了解,那麼中間步驟應該讓 LLM 自己找出最適合的方式
* https://huggingface.co/playground
* 強化學習原理
* 不斷輸出不同的解法,保留那些正確答案的解法
* ![[Pasted image 20250316021956.png]]
* 用不同 prompt 產生不同過程 15 次,正確答案有 4。拿挑正確的解法過程來訓練
* 注意: 這些解法是模型自己想的,不是人類標注的
* 有目標,模型善用自己的知識自己找解法,不斷測試和驗證
* 另外,SFT 仍是很有幫助,能讓解法一開始就接近正確的,是一種初始設定
* 做 pre-training 跟 SFT 已經很多年了,是業界標準流程
* RL 則還很新還在發展中的階段,很多細節沒公開
* 怎麼挑最佳解答
* 要花多久時間訓練
* prompt 如何分配
* 訓練的流程等等
* 02:27:47 DeepSeek-R1
* 第一家完整公開強化學習細節的公司,可以重現,大幅提升模型的推理能力
* https://arxiv.org/abs/2501.12948
* AIME 準確率隨著迭代次數增加而提升
* 平均回答的長度也增加了,透過不斷重新審視思考過程,例如圖中的 Wait, wait....
* 自己學會解題策略、處理問題的方式、用不同角度去嘗試、舉一反三,試出解法,驗證
* ![[Pasted image 20250316135211.png]]
* 比較 gpt-4o 和 deepseek r1 解題: 前者像模仿專家,後者則像人在思考一直blahblahblah,輸出文字量很大
* 推薦 together.ai 跑 DeepSeek R1
* 需要複雜的推理,推薦用思考模型
* 簡單的一般知識性問題,若用思考模型會 overkill,這種還是推薦用非推理模型
* Google Gemini flash thinking
* 這是最新的研發方向
* 02:42:07 AlphaGo
* 強化學習不是新鮮事了
* DeepMind AlphaGo 還有紀錄片
* AlphaGo 自我對弈
* paper: https://discovery.ucl.ac.uk/id/eprint/10045895/1/agz_unformatted_nature.pdf
* ![[Pasted image 20250316151436.png]]
* 一樣有 RL 超越 Supervised Learning 的時刻
* SFT 有個極限達不到,單純只是模仿人類專家,是無法超越的
* 不會受限於人類的極限
* 展現 RL 的能力
* RL 可能會發展出完全不同於人類的思維,人類都想不到的
* Move 37 https://www.youtube.com/watch?v=HT-UZkiOLv8&t=181s
* 未來 LLM 甚至不需要受限於英語來做思考
* 這裡訓練出來的思維,是否可以知識 transfer 到不可驗證的創作問題,還是未知數
* 02:48:26 reinforcement learning from human feedback (RLHF)
* 上述的 RL 是在可驗證的領域 verifiable domains,有標準答案可以評分
* 有標準答案可以比對
* 或用 LLM judge 可以打分的
* 可以自動化,不用人工介入
* 如何在無法驗證的領域中進行學習,沒有標準答案的
* 例如: 笑話、寫詩、摘要。幽默很難
* 你可以找人類專家來評分,但是每次迭代要看上千個 prompt 產生出來的上千的結果: 沒辦法大規模訓練啊
* RLHF paper: https://arxiv.org/abs/1909.08593
* 很多作者現在去 Anthropic co-founders 惹
* 針對無法驗證的領域,提出強化學習方法
* 採取間接的方式,我們訓練一個完全獨立的獎勵模型,模仿人類評分的方式
* 只需要少數人評分用來訓練出獎勵模型,就可以用這個模型跑強化學習了
* 標記員只需要排序結果,這樣比較簡單,因為人類排序比打分簡單
* 模擬人類喜歡的工具
* ![[Pasted image 20250316153056.png]]
* 優點:
* 任意領域都可以用
* 比起要創造內容,人類做判斷比較簡單
* 有些需要創意的任務,標注者也不知道怎麼寫
* 標注者不需要創作,只需要比較排序就好了
* 缺點:
* 並不是真的人類,會有誤差
* 但真正無法 scale 的問題: RL 很會鑽模型漏洞、操縱模擬結果
* reward model 也是 transformer model 類神經網路
* 可以莫名其妙得到高分: 一開始迭代會逐漸變好,然後突然莫行其妙變很爛,因為獎勵模型給很高分
* 叫做對抗性樣本 Adversarial Examples
* 有數不清的對抗性樣本,就算一直去調獎勵模型,只要 RL 跑夠久,總是會冒出來漏洞,用無意義內容騙到高分
* 因此目前 RL 只能跑幾百次迭代,就要喊停了
* RLHF 不是真正能夠創造神奇的 RL,因為他不能一直跑超越人類
* 真正的 RL 沒辦法作弊,可以一直迭代
* RLHF 這比較像是微調的方式而已,可以小幅度提升性能
* gpt-4o 有用 RLHF
* ![[Pasted image 20250316153112.png]]
## Part 4: 未來展望
* 03:09:39 preview of things to come
* 多模態: 圖片跟聲音都轉成 tokens 來訓練
* Agents: 串連多個任務,長期穩定執行,搭配人類去監督AI行為
* AI 更普遍的背後執行
* Computer Use
* 研究在 test-time 的訓練
* 例如處理影片,單靠 long context-window 不行,需要更多技術突破
* 03:15:15 keeping track of LLMs
* https://lmarena.ai/
* 最近幾個月開始被鑽漏洞操縱了: 例如 Sonnet 比預期偏後面、Gemini 則偏前面
* https://buttondown.com/ainews
* X / Twitter
* 03:18:34 where to find LLMs
* 開源可以去 together.ai 使用
* base model 得去 hyperbolic
* 本機跑 LMStudio
* 03:21:46 grand summary
![[Pasted image 20250316153125.png]]
# New 2h11m YouTube video: How I Use LLMs
https://x.com/karpathy/status/1895242932095209667
https://www.youtube.com/watch?v=IrByFa_E8s8
這是更入門的影片,主要是 demo AI app 功能
* 挺入門的從 ChatGPT 開始介紹
* 你在跟一個 壓縮檔 對話
* 簡介 thinking 模型
* tools use 示範使用
* web search
* deep research
* 大神定義是 thinking + web search
* file upload
* python interpreter
* 可惜的是,目前你必須知道這些模型有具備哪些工具
* 例如 grok3 沒有 code interpreter
* 所以算數會錯
* 例如 claude 沒有 web search
* advanced data analytics
* claude artifact
* app
* mermaid 圖表
* Cursor demo
* fake audio
* 語音辨識、語音合成 demo
* superwhisper, wisprflow, macwhisper
* true audio input/output
* advanced voice mode
* grok 3 也有 voice mode,而且限制較少。openai 很保守。
* notebooklm 產生 podcast
* 上傳 image 解讀
* 例如先要求做 OCR,然後再提問
* 產生圖片
* DALL-E
* 這是用另外獨立的模型
* 解讀 video
* 手機用視訊對話
* AI video 生成
* Google Veo-2
* OpenAI Sora
* ChatGPT memory
* ChatGPT customize
* custom GPT