* [[LangSmith]]
- youtube https://www.youtube.com/playlist?list=PLfaIDFEXuae0um8Fj0V4dHG37fGFU8Q5S
- https://docs.smith.langchain.com/evaluation
- https://docs.smith.langchain.com/concepts/evaluation
- https://twitter.com/virattt/status/1783246736946762027
## 1. Why Evals Matters
* https://docs.smith.langchain.com/old/evaluation
* https://docs.google.com/presentation/d/1y_dYspY8odgVvE4OfimCLmw9QHz7QPkYNMvK8wyg9bY/edit#slide=id.p
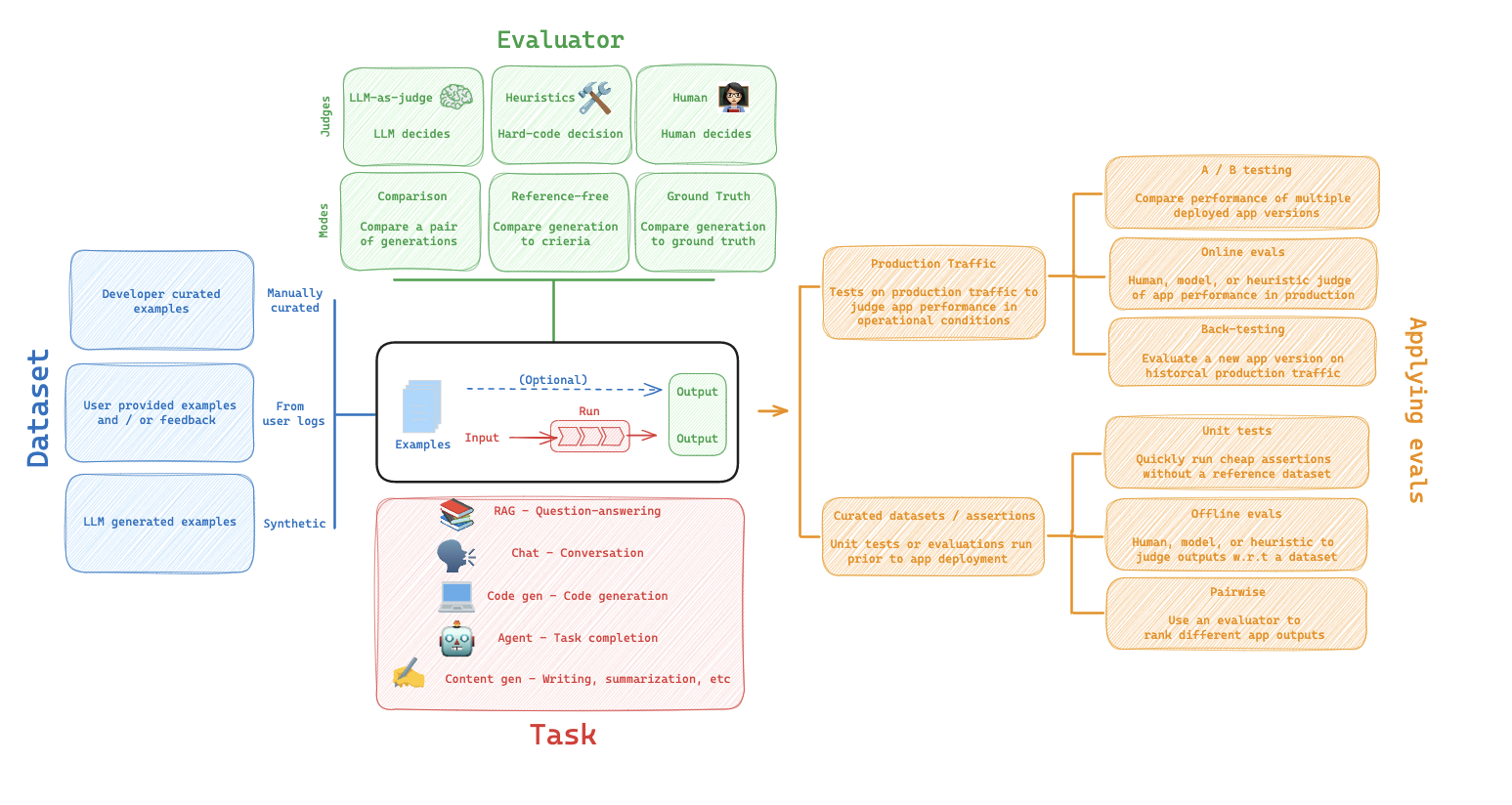
## 2. Primitives
* https://docs.smith.langchain.com/concepts
* https://docs.smith.langchain.com/old/tracing/concepts
* app 結構是 project > traces > runs
* dataset 結構是 dataset > examples > input&output
* evaluator 有各種不同方式
* 將 example 的 output 跟預測結果進行評估
* 得到 {"key": "metric_name", "score": metric value }
* https://docs.google.com/presentation/d/1N1JKe_7qLIuiY2M40gKFGGYTb37t6F_oqGLUpw5oXy4/edit#slide=id.p
## 3. 手動建立 Datasets
* [ ] https://docs.smith.langchain.com/old/evaluation/faq/manage-datasets
* colab: https://github.com/langchain-ai/langsmith-cookbook/blob/main/introduction/langsmith_introduction.ipynb
(這集講 1~3)
## 4. 從 user logs 轉 datasets
(這集講 4)
* 用了 wrap_openai 將 user log 送到 langsmith 的 dataset
* 後台可以挑選 traces 然後 Add to Dataset,但這裡 Type 會是 Chat
* 可以編輯修正 Answer,如此來收集用戶真實資料
## 5. 內建的 LLM-as-Judge: Evaluators
(這集講 5)
* 內建的 https://docs.smith.langchain.com/old/evaluation/faq/evaluator-implementations
* 這裡用 LangChainStringEvaluator("cot_qa"),有推理步驟然後回覆 CORRECT or INCORRECT
* 實際 prompt 在 langchain repo 找 eval_prompt.py
## 6. 自訂 Evaluators
(這集講 6)
* 實作 hard-code 一個 evaluator,就像 unit test
## 7. Eval Comparisons 介面
* Q: 如何比較 Mistral-7b 本地跟 gpt-3.5-turbo 的效能?
* 用相同的 dataset,在後台可以點兩個 Tests 做 Comparsion 介面
* 作者講這是 a/b testing,我覺得不算是吧
- [ ] 我目前 colab 的 prompt engineering 可以做一個這個版本
## 8. Evaluations in the prompt playground (no code)
* https://docs.smith.langchain.com/old/evaluation/faq/experiments-app
* 就跟 https://spellbook.scale.com/ 是 類似的功能
* 從後台就可做快速的 prompt 測試,拿現成的 dataset 來跑
## 9. Attach evaluators to datasets (no code)
* 承上,可以在後台設定 Evaluator,就會一起跑
## 10. Unit Tests
* https://docs.smith.langchain.com/old/evaluation/faq/unit-testing
* 使用 pytest,然後搭配 langsmith 的 @unit 裝飾器,就會在 langsmith 紀錄起來統計 Pass%
* 單元測試其實只會有 pass 跟 fail 兩種結果
## 11. Summary Evaluators
* https://docs.smith.langchain.com/old/evaluation/faq/custom-evaluators#summary-evaluators
* 自訂 summary metric 針對 dataset 層級的評估,傳入 summary_evaluators 參數
* 例如算出 F1 score
## 12. RAG Evaluation (Answer Correctness)
* Guide https://docs.smith.langchain.com/old/cookbook/testing-examples/rag_eval
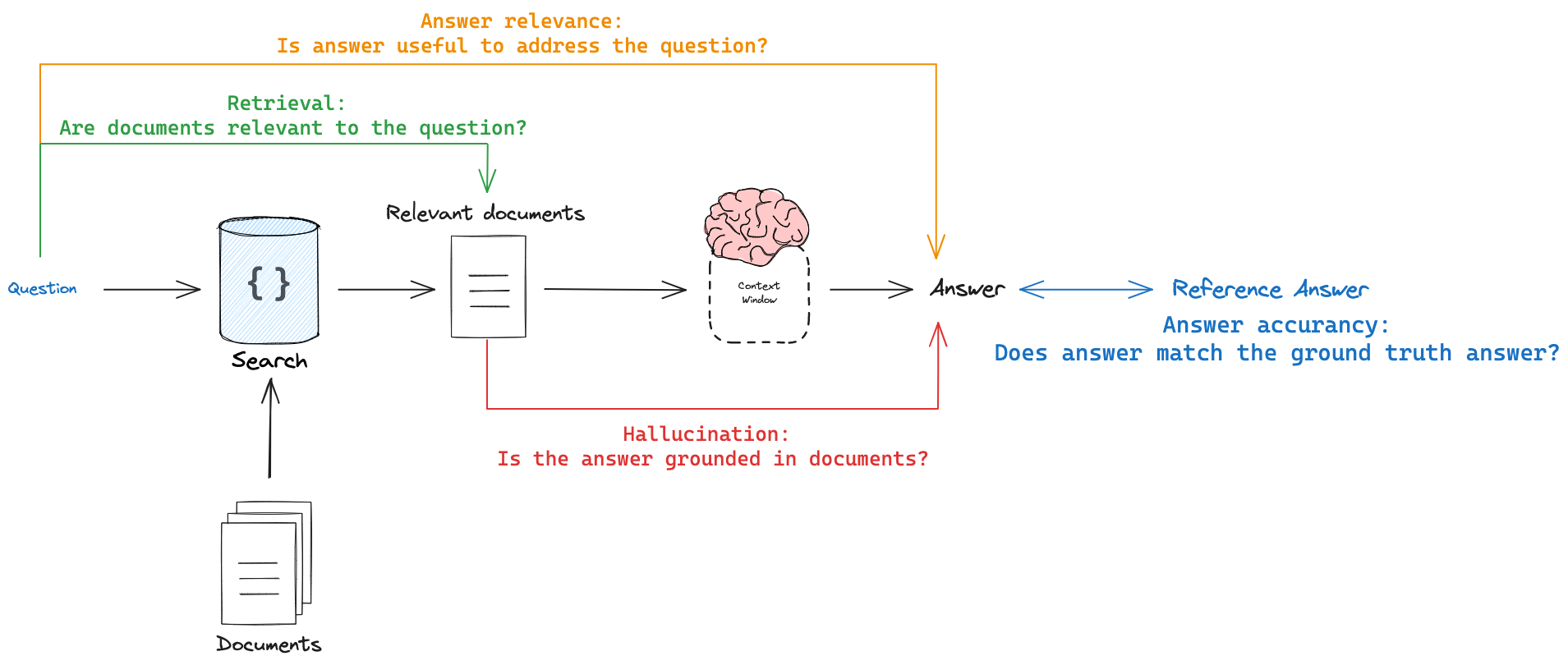
* LangChainStringEvaluator 用 cot_qa
* 有段 prepare_data lambda 要注意
## 13. RAG Evaluation (Answer Hallucinations)
* 根據 context 跟 answer 來判斷
* 用 LangChainStringEvaluator 的 labeled_score_string 並給 criteria
> langchain 系列的圖表真不錯,可是 code API 設計的不好啊.... XD
> 這個 labeled_score_string 好醜
## 14. RAG Evaluation (Document Relevance)
* 判斷 question 跟 context 相關性
* 判斷 question 跟 answer 相關性
* 用 LangChainStringEvaluator 的 score_string,因為沒有標準答案(無 reference 參數)
## 15. Regression Testing
https://docs.smith.langchain.com/old/evaluation/faq/regression-testing
* Q: 做了個 RAG chain 想換個 LLM 試試,需要評估是否換了成效有差?
* 這裡影片跟最新的 code 不一定
* 影片用 labeded_score_string
* 但最新 code 用自訂的 answer_evaluator https://smith.langchain.com/hub/langchain-ai/rag-answer-accuracy/?organizationId=f54ed48d-ff0b-44e1-9515-21e55b192f29
* 後台有個 Comparing Experiments 功能,這個介面可以選 baseline 做比較
## 16. RAG (evaluate intermediate steps)
* 若 RAG pipeline 不會回傳 context
* 我們可以 hack 這個 evaluator 從中抓出 context
## 17. Pairwise Evaluation
colab code 是 18. Pairwise evaluations
* chatbot arena https://lmsys.org/blog/2023-05-03-arena/
* https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge
* 這有 judge prompt 可以抄 https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/data/judge_prompts.jsonl
* 相同輸入,評測哪一個模型結果比較好
* 一開始先用了 text_summary_grader 做,發現大家分數都 5 分,看不出差異
* 用 pairwise 可以更突出比較出兩者誰優誰劣
* 自訂 evaluate_pairwise 方法,然後使用 evaluate_comparative 來做評估
* https://smith.langchain.com/hub/rlm/pairwise-evaluation-tweet-summary?organizationId=f54ed48d-ff0b-44e1-9515-21e55b192f29
* 這個 prompt 要根據你的場景來改,效果更好
* 後台會有單獨的 Pairwise Experiments tab 介面
## 18. How to evaluate upgrading your app to GPT-4o
* 又講了一次 Regression Testing
* 除了 accuracy 還有 latency 也要觀察
## 19. Backtesting 回測
colab code 是 17. Back-testing
* 評估不同的 app 變形
* convert_runs_to_test 從特定時間區間的 user log 轉成 dataset
* 用不同 app 跑預測
* 然後用 evaluate_pairwise 跑評估
## 20. Online Evaluation (RAG 幻覺)
colab code 是 16. Online Evaluators
* rag-answer-hallucination prompt https://smith.langchain.com/hub/rlm/rag-answer-hallucination?organizationId=1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8
* https://smith.langchain.com/hub/rlm/rag-document-relevance/playground?organizationId=1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8&type=structured
* 可以在 online production 跑檢測,但注意這場景是沒有標準答案的,但 RAG 仍可以做三種不需要標準答案的評估
* 後台 Project 可以設定 Add Rule
* 觸發條件
* Sampling rate
* 選擇檢測的 prompt,例如檢測幻覺
* 如此後台就有 Feedback 可以看輸出
## 21. Online Evaluation (Guardrails)
https://docs.smith.langchain.com/how_to_guides/monitoring/online_evaluations
* 檢測是否有毒、是否有個人隱私資訊
* Add Rule -> Online evaluation -> Try a suggested Evaluator Prompt -> Tagging
* 根據 criteria 進行標記
## 22. Dataset Splits
* https://docs.smith.langchain.com/how_to_guides/datasets/manage_datasets_in_application#create-and-manage-dataset-splits
* https://docs.smith.langchain.com/how_to_guides/evaluation/evaluate_llm_application#evaluate-on-a-dataset-split
* 作者想測試 RAG 更換 0.1 到 0.2 文件時,exaemples 其中 0.1 和 0.2 的 QA 結果
* 後台在 dataset 可以選 examples 點 Add to Split
* 可以切開不同 split 看結果
* 呼叫 evaluate 方法時,也可以傳參數指定跑哪一些 split
* 這招也可以用到微調場景,分割訓練和測試數據
## 23. Repetitions
有 colab
* https://docs.smith.langchain.com/how_to_guides/evaluation/evaluate_llm_application#evaluate-on-a-dataset-with-repetitions
* 重複執行 eval 多次執行來獲得更可靠的結果
* evaluate 方法有 num_repetitions 參數
* 後台就有 Repetitions 顯示執行次數
# Agent Evaluation
https://www.youtube.com/watch?v=NbQKDfSw3gM&list=PLfaIDFEXuae0um8Fj0V4dHG37fGFU8Q5S&index=24
## 24. Agent Response
* https://docs.smith.langchain.com/concepts/evaluation#agents
* 影片 https://www.youtube.com/watch?v=NbQKDfSw3gM&list=PLfaIDFEXuae0um8Fj0V4dHG37fGFU8Q5S&index=25
* Agent 有 tools, memory, planning
* 3:50 秒才進入 eval 主題
* 三種 types
* Final Response 不看過程,只看最後結果
* Single step 評估單一步驟
* Trajectory 評估是否按照預期的步驟執行
* sql agent v1 版 https://docs.smith.langchain.com/tutorials/Developers/agents
* https://python.langchain.com/v0.2/docs/tutorials/sql_qa/#agents
* 每個問題都判斷要用哪個工具
* sql agent v2 版更強 https://langchain-ai.github.io/langgraph/tutorials/sql-agent/
* 有明確的工具路徑
## 25. Agent Single Step
* 評估單一步驟是否能挑選到正確的工具
* 寫了一個 check_specific_tool_call 的方法來檢查
## 26. Agent Trajectory
* 檢查工具呼叫的順序
* 範例 https://langchain-ai.github.io/langgraph/tutorials/sql-agent/
* 定義 expected_trajectory = ['sql_db_list_tables', 'sql_db_schema', 'db_query_tool', 'SubmitFinalAnswer']
* 寫了一個 contains_all_tool_calls_in_order_exact_match
* 從整個 messages 中抓出 tools 跟 expected_trajectory 一樣
* 另一個版本是 contains_all_tool_calls_in_order
* (3:10秒) 順序一樣就好,中間有別的工具呼叫沒關係
* 實際評估,發現模型有時會幻覺 db_db_query 這個不存在的工具名稱,然後模型需要 retry 才能成功
## 27. Corrections + Few Shot Examples (Part 1) | LangSmith Evaluations
* evaluator 不一定能補抓到人類偏好,這裡教如何 correction
* langsmith 有 online evaluation 功能
* 在 eval prompt 中加入 人類糾正的 few-shot example。格式是
* fact
* question
* reasoning
* score
* langsmith 上可以糾正分數!! 這筆就會被加進 few-show dataset
![[Pasted image 20240901000049.png]]
## 28. Corrections + Few Shot Examples (Part 2) | LangSmith Evaluations
跟 27 集一樣啊,重錄版本而已...XD