RL
- https://openai.com/o1/
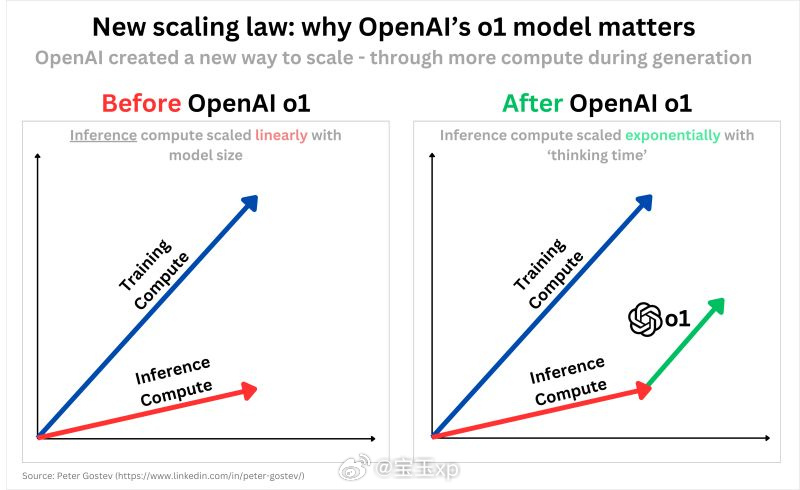
* https://x.com/dotey/status/1865890371722440734 (2024/12/9)
* 一樣是 cot, 但不是同一個檔次的東西,一個是用 prompt 去引導的,一個是先天用強化學習練過的 cot
* 前者靠人下 prompt 的能力
* 後者靠模型本身能力
* https://openai.com/index/introducing-openai-o1-preview/
* o1 系列的寫作能力比較不討人喜
* https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
* mini 的推理性能其實更好,而且只比 4o 貴一點
* inference 也可以 scale
* https://x.com/DrJimFan/status/1834279865933332752 這篇讚
* [ ] 有兩個 papers 要看一下
* search 解法空間,例如
* using each number but only once, how would you make the numbers 6,0,1,3 equal 10 without using addition.
* 這題的 CoT 就很長........ 不斷在找答案,雖然最後還是沒答對,但你花很多錢...... orz
* https://x.com/DrJimFan/status/1834279865933332752
* 這可能是自 2022 年 OG Chinchilla 縮放定律以來 LLM 研究中最重要的數字
* 沒有任何自我改進的 LLM 演算法能夠獲得超過 3 輪的成績
* 3 rounds of self-improvement seem to be a saturation limit for LLMs
* https://x.com/dotey/status/1835487640444932570 寶玉的整理
* https://openai.com/index/learning-to-reason-with-llms/
* 有個圖很重要,增加 test-time 可以提升準確率
* 但是 log scale 誤導啊
* [ ] 有 CoT 對比範例
* Jason Wei
* https://x.com/_jasonwei/status/1834278706522849788
* 不要純粹透過提示來進行思考鏈,使用強化學習訓練模式以更好地進行思考鏈。
* API 文件
* https://platform.openai.com/docs/guides/reasoning
* 有個看不到也摸不到 internal reasoning tokens 要算錢,OpenAI 建議至少保留 25,000 個詞元用於推理和輸出.....
* 而 o1-preview 的輸出價格是 60 per 1M tokens
* 所以一個複雜問題可能要花掉 USD 1.5
* 限制
* https://x.com/dotey/status/1834421234592882762 團隊影片
* [ ] system card https://openai.com/index/openai-o1-system-card/
https://x.com/lukaszkaiser/status/1834281403829375168
https://x.com/pfau/status/1834362105811915184
https://x.com/Justin_Halford_/status/1834478613913031166
https://x.com/WilliamBryk/status/1834614138955526440
https://x.com/voooooogel/status/1834569673712754805 XD 如果你過多次詢問 o1 的推理,OpenAI 會發送給你的電子郵件
https://x.com/dotey/status/1834695750493540372
https://x.com/oran_ge/status/1835137420016468451 不只是 CoT
https://x.com/oran_ge/status/1835490443548827889
https://x.com/oran_ge/status/1835525836608610481
https://x.com/oran_ge/status/1835579652016132449 AK:当模型发明了自己的语言,不再说英语,强化学习就算做对了
OpenAI o1,AI 的 L2 时刻到来 https://orangeai.notion.site/OpenAI-o1-AI-L2-0ff1efa6dac880e8bc01c59466a04647
2024/9/13 的 AINews o1: OpenAI's new general reasoning models
https://buttondown.com/ainews/archive/ainews-o1-openais-new-general-reasoning-models/
OpenAI o1 传说中的strawberry终于来了
https://quail.ink/op7418/p/openai-o1-strawberry-finally-arrived
OpenAI o1的价值及意义
https://zhuanlan.zhihu.com/p/720078255
陶哲轩对 o1 的点评
https://x.com/dotey/status/1834809048845156575
擴展 LLM 推理時的效能限制是多少? 已經從數學上證明,只要允許變壓器根據需要產生盡可能多的中間推理標記,變壓器就可以解決任何問題。值得注意的是,恆定的深度就足夠了。
https://x.com/denny_zhou/status/1835761801453306089
更聰明不一定更有用 經過更多測試後,o1 和 o1-preview 唯一有用的地方是硬程式碼問題。
https://x.com/bindureddy/status/1836858876907450407
有沒有人弄清楚如何理解 OpenAI 的 o1 中的思考步驟?
https://x.com/omarsar0/status/1837157178248950173
我越是實驗 OpenAI 的 o1-preview,越是意識到這個模型並不適合用於聊天介面
在代理人工作流程中,你可以用它建造的東西真是瘋狂
https://x.com/omarsar0/status/1839472825700430085
张俊林拆解o1:OpenAI o1原理逆向工程图解
https://mp.weixin.qq.com/s/fGfQLMeRsv01Z6ouZt3TOA
全网最全 OpenAI o1 万字综述:创新、原理和团队
https://www.woshipm.com/aigc/6118783.html
paper: https://arxiv.org/abs/2409.18486
paper: https://arxiv.org/abs/2410.01792
paper: https://github.com/hijkzzz/Awesome-LLM-Strawberry
O1 Replication Journey: A Strategic Progress Report:
https://github.com/GAIR-NLP/O1-Journey
https://arxiv.org/abs/2411.16489
paper: https://arxiv.org/abs/2410.13639
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
paper 收集: https://github.com/srush/awesome-o1/
## OpebAI forum
https://community.openai.com/t/new-reasoning-models-openai-o1-preview-and-o1-mini/938081
https://community.openai.com/t/o1-tips-tricks-share-your-best-practices-here/937923/4
```
This is from the writeup that cognition did on using o1:
"Prompting o1 is noticeably different from prompting most other models. In particular:
Chain-of-thought and approaches that ask the model to “think out loud” are very common in previous generations of models. On the contrary, we find that asking o1 to only give the final answer often performs better, since it will think before answering regardless.
o1 requires denser context and is more sensitive to clutter and unnecessary tokens. Traditional prompting approaches often involve redundancy in giving instructions, which we found negatively impacted performance with o1.
```
## AMA 9/14 am2 整理
- AMA https://x.com/OpenAIDevs/status/1834608585151594537
- https://x.com/simonw/status/1834630686734426504 mini 就是正式版
- https://x.com/swyx/status/1834637226199933160 無論你多麼努力地提示 GPT-4o,你可能都不會得到 IOI 金牌!
- 思考時間 之後會可以設置! https://x.com/ahelkky/status/1834646730941645073
- https://x.com/actualrealyorth/status/1834614449593880654
- FC, system prompt, batch api, streaming, structured outputs, multimodality
- cot summary in api https://x.com/YellowKoan/status/1834631883985969492
- few shot 還是有用的! https://x.com/alex_j_lach/status/1834646660183736355
- Providing edge cases and potential reasoning styles can be helpful. As a reasoning model, OpenAI o1 does better at taking the cues from the examples provided. 提供邊緣案例和潛在的推理風格是有幫助的。作為一個推理模型,OpenAI o1 在從提供的範例中獲取線索方面表現更佳。
- RAG https://x.com/itsurboyevan/status/1834620907572105352
- https://x.com/dotey/status/1834693904626581888
- https://x.com/btibor91/status/1834686946846597281
- https://x.com/swyx/status/1834719880949780689
- https://x.com/op7418/status/1835153295855567356
### 取自 AIGC Weekly 電子報 #89
Open AI 举办了一个关于 Open AI o1 的 AMA。回答了非常多用户和开发者关注的o1 问题:
- 强调 o1 不是一个“系统”而是一个经过系统训练的模型。
- mini 在某些方面确实更好,只是世界知识不够多
- o1 模型即将支持更大的输入上下文
- o1 本身是有多模态能力的
- CoT token 不会被公开
- 提示可以影响模型思考问题方式
- 强化学习 (RL) 用于改善 o1 中的 CoT,GPT-4o 无法仅通过提示匹配其 CoT 性能
- 正在为模型添加广泛的世界知识
## 一些整理
https://orangeai.notion.site/OpenAI-01-L2-0ff1efa6dac880e8bc01c59466a04647
https://simonwillison.net/2024/Sep/12/openai-o1/ Notes on OpenAI’s new o1 chain-of-thought models
https://x.com/simonw/status/1834286442971103468
Some favorite posts about OpenAI o1, as selected by researchers who worked on the model
https://x.com/OpenAI/status/1836846202182131776
## Use case
* planning 感覺是對開發者最有用的
* https://x.com/alliekmiller/status/1834344336080658858
* https://x.com/JefferyTatsuya/status/1834520001954648250
* 其實 cookbook 那個就是拆解 planning 能力
* [ ] 做成 ReAct 看看?
* [ ] 給他 code interpreter 工具? 可以執行任何 python code????
* https://github.com/OpenInterpreter/open-interpreter
* https://github.com/FanaHOVA/openai-o1-code-interpreter
* 複雜問題合成
最佳化
https://x.com/Joshverd/status/1834332742806634918
難題
https://www.facebook.com/watch/?v=1544458756157805
https://x.com/GregKamradt/status/1834286346938225048
https://x.com/jesselaunz/status/1834532702814695499
求方程y^2 + 2y = x^4 + 20x^3 + 104x^2 + 40x + 2003 所有的整数解
爱因斯坦谜题
https://x.com/jesselaunz/status/1834351603878678717
解读密文
https://x.com/oran_ge/status/1834793970314141993
## 第三方評測
* Bindu 在跑 https://x.com/bindureddy/status/1834388208467280132
* https://livebench.ai/
* https://x.com/crwhite_ml/status/1834599935079268591
* https://x.com/rohanpaul_ai/status/1834583713721581758
海龟汤 好像蠻適合的
https://mazzzystar.github.io/2024/08/09/turtle-benchmark-zh/
https://x.com/oran_ge/status/1834958653922984307
## 科普類
https://x.com/GPTDAOCN/status/1834292532798521791
https://x.com/tuturetom/status/1834407333113524699
https://x.com/Gorden_Sun/status/1834532784528101702
o1系列模型毫无疑问是做题家,解决数学题的能力超级强,尤其适合AI助教,例如可汗学院的Khanmigo。
## 簡中資料
https://mp.weixin.qq.com/s/fGfQLMeRsv01Z6ouZt3TOA
https://www.woshipm.com/aigc/6118783.html
## Prompt
4o prompt: 給詳細指令
o1 prompt: 給目標期望、如何評量、什麼是成功什麼是失敗
## 課程
Reasoning with o1
https://www.deeplearning.ai/short-courses/reasoning-with-o1/
## o3
* https://x.com/OpenAI/status/1870186518230511844
* https://x.com/__nmca__/status/1870170098989674833
* https://x.com/__nmca__/status/1870170101091008860 it’s “just” an LLM trained with RL
* https://x.com/DrJimFan/status/1870542485023584334
* https://x.com/rhythmrg/status/1870602244103766258
* https://x.com/leloykun/status/1871184229369004291
* https://x.com/paul_cal/status/1871105026774736956
* https://x.com/brhydon/status/1870934943586533574 o3 is an LLM
* https://www.interconnects.ai/p/openais-o3-the-2024-finale-of-ai
* https://aiguide.substack.com/p/did-openai-just-solve-abstract-reasoning
* https://medium.com/aiguys/openai-achieved-agi-with-its-new-o3-model-ef2b2ab4d974