* 本條目專注在 RAG 層面的評估
* 相關條目
* [[RAG 開發知識庫]]
* [[LLM Evaluation]]
* [[Prompt Evaluation]]
* [[Agent Evaluation]]
* 用 LLM 評估的 Best Practices https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG
* Evaluation Metrics for LLM Applications In Production 介紹各種方式
* https://docs.parea.ai/blog/eval-metrics-for-llm-apps-in-prod
* RAG 任務
* Agent 任務 e.g 達到目標和訊息量
* 摘要任務
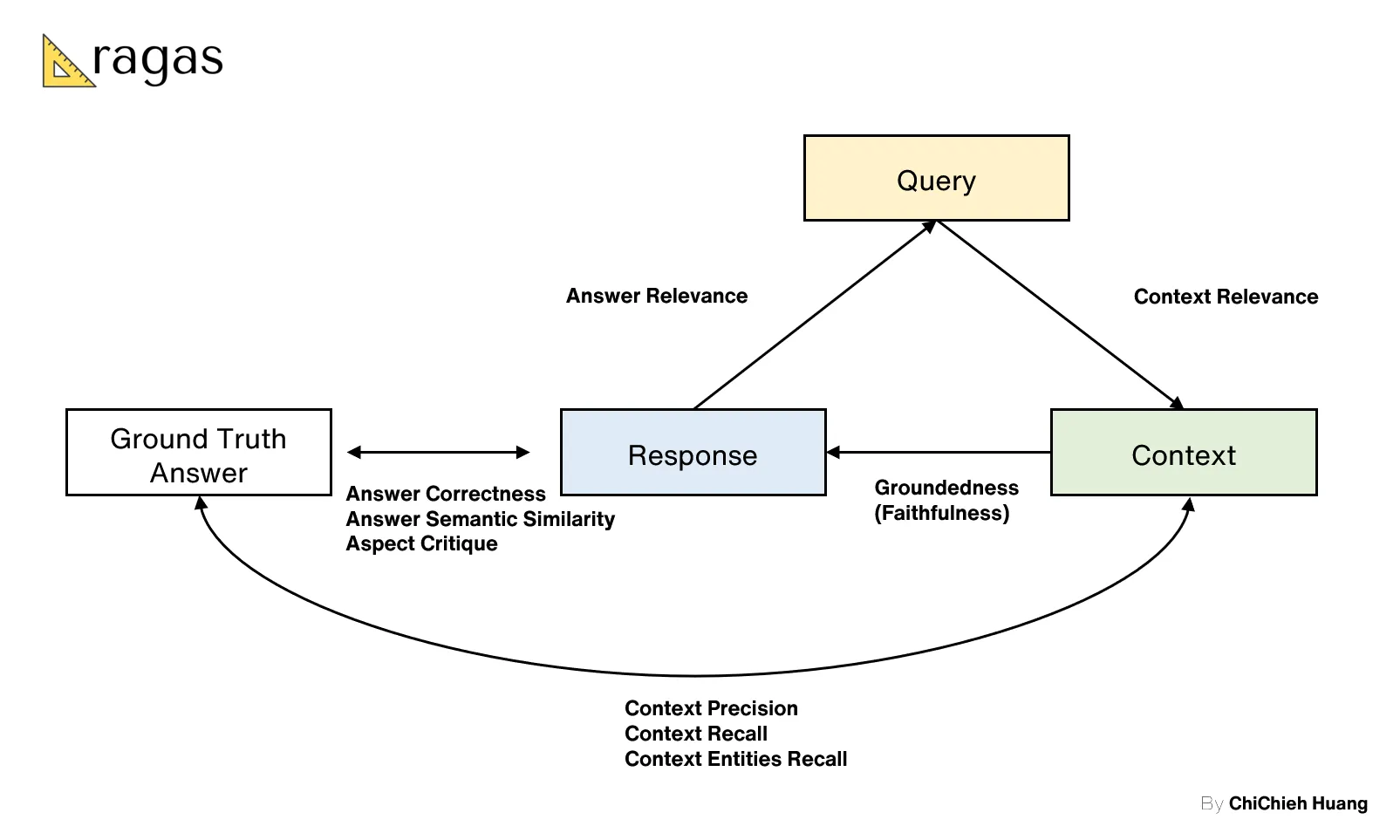
* Ragas
* https://docs.ragas.io/en/stable/
* paper: https://arxiv.org/abs/2309.15217 (2023/9)
* 特色 automated reference-free evaluation
* https://twitter.com/helloiamleonie/status/1747252654047142351 (2024/1/16)
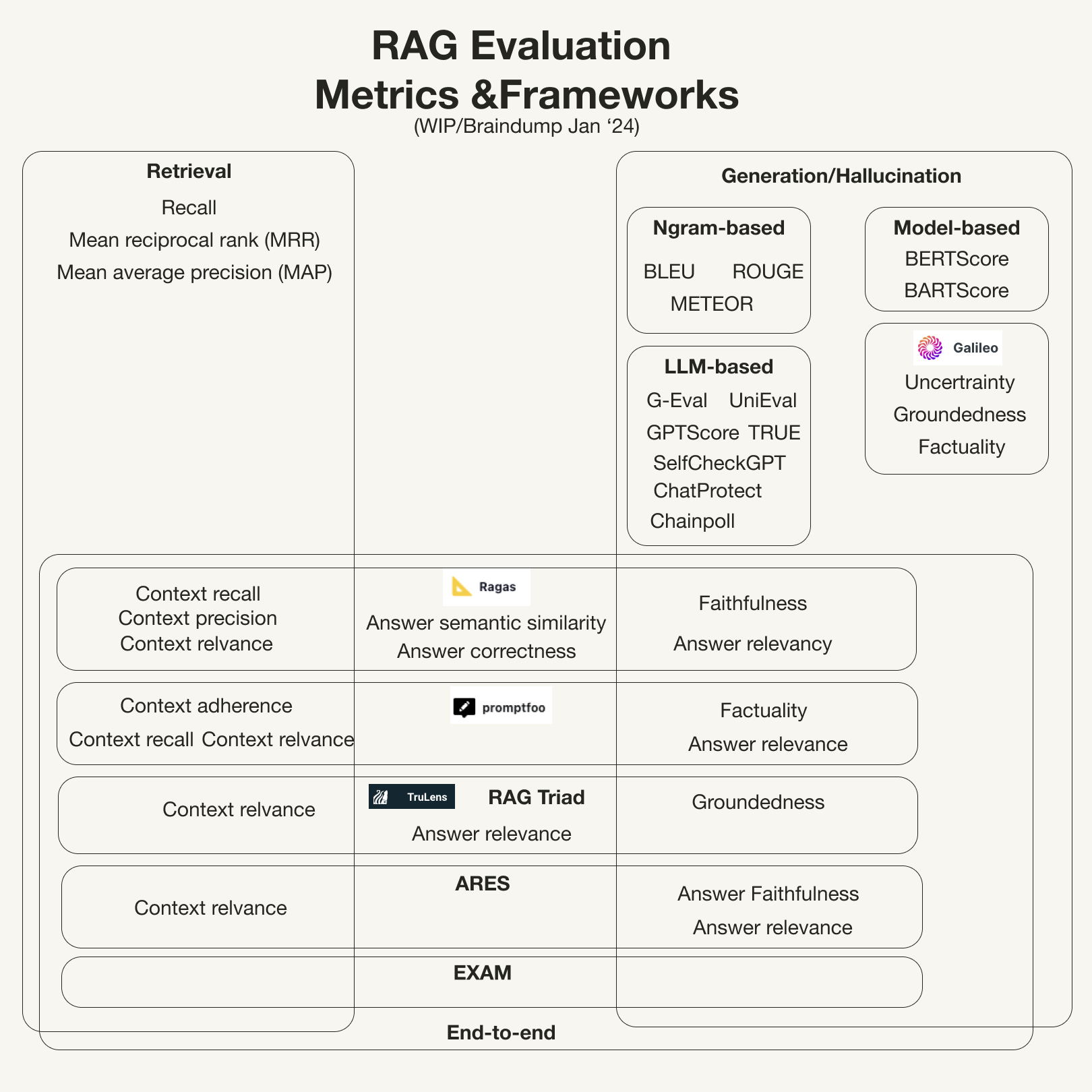
> 這表格真棒!! Ragas 有做 Context recall 還有 precision,而 RAG Triad 做的比較少。
RAG survey paper 裡面也有講到但是好像講錯了,還不如這張表。
* Troubleshoot RAG https://towardsdatascience.com/top-evaluation-metrics-for-rag-failures-acb27d2a5485 (2024/2/3)
* 這篇不錯,有個流程圖講解 Troubleshoot 思路
* 關於 recall 跟 precision 的解釋,以期一些思路 https://jxnl.github.io/blog/writing/2024/02/05/when-to-lgtm-at-k/#mean-average-precision-map-k
* 評估 LLM 處理 RAG 的能力
* https://twitter.com/bindureddy/status/1758178055405912386 (2024/1/16)
* https://arxiv.org/abs/2309.01431v2
* 能抗噪、能整合資訊、能回答不知道、能辨識不對的事實
* 延伸 paper
* How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior
* https://arxiv.org/abs/2404.10198 (2024/4/16)
* Advanced RAG Series: Generation and Evaluation (2024/3/15)
* https://div.beehiiv.com/p/advanced-rag-series-generation-evaluation
* ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems (2024/3)
* https://arxiv.org/abs/2311.09476
* https://arxiv.org/abs/2311.09476v2
* Answer Faithfulness
* Answer Relevance
* RAG Evaluation Tools https://generativeai.pub/llamaindex-and-rag-evaluation-tools-59bae2944bb3 (2024/4/25)
* 介紹四種框架
* Evaluation Metrics for Search and Recommendation Systems
* 介紹指標
* https://weaviate.io/blog/retrieval-evaluation-metrics
* Retrieval evaluation 也是介紹指標
* https://medium.com/@rossashman/the-art-of-rag-part-4-retrieval-evaluation-427bb5db0475
* First Principles in Evaluating LLM Systems (2024/5/22)
* https://leehanchung.github.io/blogs/blog/2024/05/22/first-principles-eval/
* 深入解析 RAG 評估框架:TruLens, RGAR, 與 RAGAs 的比較 (2024/6/5)
* https://medium.com/@cch.chichieh/%E6%B7%B1%E5%85%A5%E8%A7%A3%E6%9E%90-rag-%E8%A9%95%E4%BC%B0%E6%A1%86%E6%9E%B6-trulens-rgar-%E8%88%87-ragas-%E7%9A%84%E6%AF%94%E8%BC%83-ab70d7117480


* Improving retrieval with LLM-as-a-judge (2024/7/3)
* https://blog.vespa.ai/improving-retrieval-with-llm-as-a-judge/
* paper: Evaluation of Retrieval-Augmented Generation: A Survey (2024/7)
* https://arxiv.org/abs/2405.07437
* Generative Benchmarking (2025/4/7)
* https://research.trychroma.com/generative-benchmarking
* https://github.com/chroma-core/generative-benchmarking/tree/main
* Generative Evals 是 Chroma 發明的一套 建立評估資料集的方式
* 過濾出哪些高品質文件適合生成查詢
* 用 LLM 做 Query 生成
* 跑 Benchmark 測試檢索系統
* There Are Only 6 RAG Evals (2025/5/19)
* https://jxnl.co/writing/2025/05/19/there-are-only-6-rag-evals/
## Benchmark & Dataset
[[RAG Benchmark]]
## Evaluating Verifiability in Generative Search Engines
https://twitter.com/Tisoga/status/1736544319199478175
https://arxiv.org/abs/2304.09848
## TruLens RAG Triad
* https://www.trulens.org/trulens_eval/core_concepts_rag_triad/
* [[Building and Evaluating Advanced RAG Applications]]
## Open RAG Eval
https://github.com/vectara/open-rag-eval
## RAGChecker
A Fine-grained Framework For Diagnosing RAG
* https://github.com/amazon-science/RAGChecker
* https://x.com/omarsar0/status/1824460245051081216 (2024/8/16)
* https://arxiv.org/abs/2408.08067
## Prometheus 專門的評估模型
https://blog.llamaindex.ai/llamaindex-rag-evaluation-showdown-with-gpt-4-vs-open-source-prometheus-model-14cdca608277
比 GPT-4 便宜十倍,不過還是 GPT-4 比較厲害
這篇 blog 有評估 prompt 可以參考: **Correctness**, **Faithfulness**, **Relevancy**
這需要有 context 跟參考答案
Prometheus 2 一个专门用于评估大语言模型质量的模型
https://twitter.com/op7418/status/1786299950147788837 (2024/5/3)
https://twitter.com/omarsar0/status/1786380398966014423
https://x.com/llama_index/status/1798454426904244588 (2024/6/6)
## [[Building and Evaluating Advanced RAG Applications]]
Trulens 的 evaluation metrics 有
* context relevance
* groundedness
* answer relevance
不需要參考答案,因此也沒算 recall 分數
https://www.trulens.org/trulens_eval/core_concepts_rag_triad/
## dataset
https://blog.llamaindex.ai/two-new-llama-datasets-and-a-gemini-vs-gpt-showdown-9770302c91a5 (2023/12/20)