https://www.facebook.com/ihower/posts/10160974050143971
https://twitter.com/ihower/status/1763746152846163972
* Please Stop Saying Long Context Windows Will Replace RAG (2024/3/18)
* https://cobusgreyling.medium.com/please-stop-saying-long-context-windows-will-replace-rag-3cd111cfb247
https://blog.orangesai.com/p/technological-ripple-effect-rag-and-long-context-cognitive-conflict
https://twitter.com/RLanceMartin/status/1770559065955205302 (2024/3/21)
Need to balance system complexity vs latency & token usage
* 大模型超长上下文对 RAG 是降维打击 (2024/2/29)
* https://twitter.com/iheycc/status/1763194137531298300
* https://heycc.notion.site/RAG-e0c30da6c2904c3599b582b978c31de1
* 技术的涟漪效应:RAG与Long Context的认知冲突 (2024/4/7)
* https://quail.ink/orange/p/technological-ripple-effect-rag-and-long-context-cognitive-conflict
* https://twitter.com/bindureddy/status/1788684124863303709 2024/5/10
* Infinite context in LLMs is close to largely useless.
* LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs (2024/6/30)
* https://arxiv.org/abs/2406.15319
* https://x.com/llama_index/status/1818802688274100578
* https://github.com/run-llama/llama_index/blob/main/llama-index-packs/llama-index-packs-longrag/examples/longrag.ipynb
* 把 chunk 提高到 4k,top-k 減少,也蠻有用的
* 但是 embedding model 無法吃這麼長,還是要拆小 chunk,但是取最相似分數的當作那一整個大 chunk 的分數
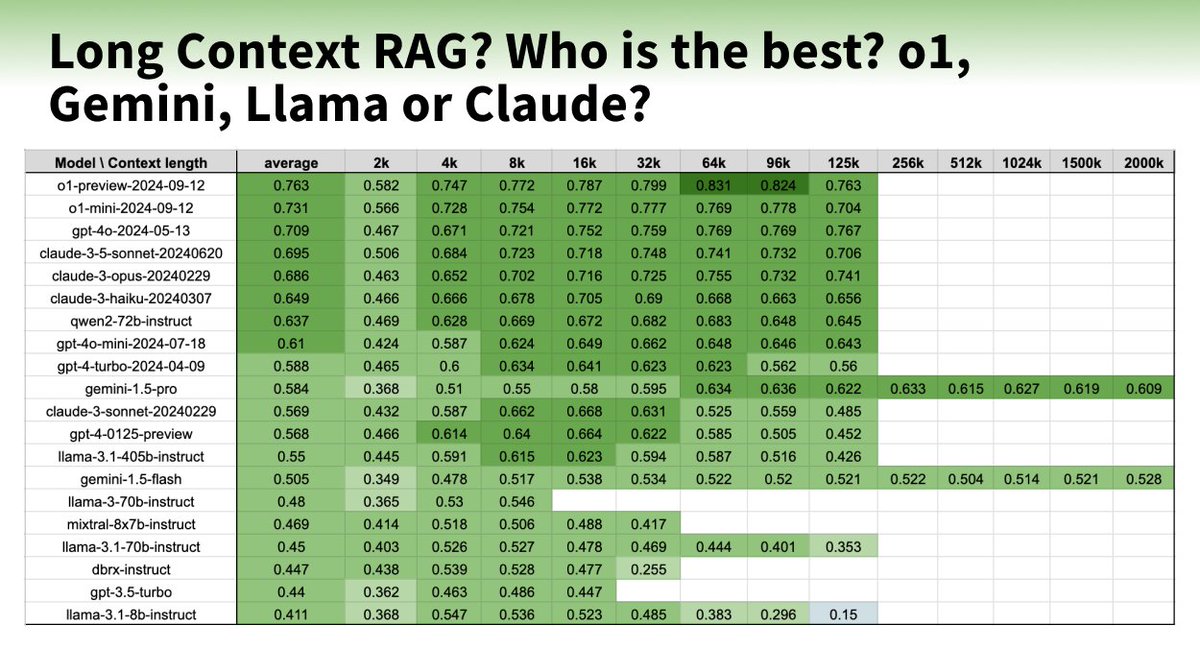
* Long Context RAG Performance of LLMs (2024/8/12)
* https://www.databricks.com/blog/long-context-rag-performance-llms
* 對於大多數模型來說,存在一個飽和點,超過該點後性能會下降
* Why RAG 的論述 (2024/10/30)
* https://unstructured.io/blog/rag-vs-long-context-models-do-we-still-need-rag
* How Long Contexts Fail and How to Fix (2025/6)
* https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
* https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html
* Context Rot: How Increasing Input Tokens Impacts LLM Performance (2025/7/14)
* https://research.trychroma.com/context-rot
* https://x.com/omarsar0/status/1946607725796045287 (2025/7/20)
* https://maven.com/p/f7ea13/context-rot-with-chroma-db
* https://maven.com/p/37bdf2/context-rot-when-long-context-fails
## Papers
* Benchmarking Large Language Models in Retrieval-Augmented Generation (2023/12)
* 探針測試只是基本,LLM 模型本身在 RAG 應用上還應該有以下能力
* 能抗噪、能整合資訊、能回答不知道、能辨識不對的事實
* https://arxiv.org/abs/2309.01431v2
* Long-context LLMs Struggle with Long In-context Learning https://arxiv.org/abs/2404.02060 (2024/4/2)
* LongICLBench 評測
* https://twitter.com/omarsar0/status/1775638933377786076 2024/4/4
* 除了 GPT-4,其他家超過 20k 時效能都急遽下降
* ihower: 細看 paper 包括 Gemini-1.0-Pro, Gemma-7B, Llama-2-7B, Mistral-7B 以及一眾開源,感覺對手太弱
* 模型也傾向於預測序列末尾出現的標籤
* RULER: What's the Real Context Size of Your Long-Context Language Models? (2024/4/9)
* https://arxiv.org/abs/2404.06654
* Nvidia 的新合成基準 RULER,包括四個類別的任務:檢索、多跳追踪、聚合和問答,所有任務都可配置為不同長度和複雜度
* https://twitter.com/GregKamradt/status/1778427541461852439
* https://github.com/hsiehjackson/RULER 有最新分數和結論
* Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach (2024/7)
* https://arxiv.org/abs/2407.16833
* https://x.com/omarsar0/status/1816495687984709940
* https://x.com/bindureddy/status/1816912246146318806
* Long-Context 表現較好,但 RAG 成本顯著較低
* 混合方案 Self-Route 方法的思路不錯,可以參考學習:
* 一律先用檢索找出最相關的 chunks
* 用例如這個 prompt 判斷 chunks 是否可以回答用戶問題: You are given some text chunks retrieved based on a query. Based only on these chunks: 1. Determine if the query can be answered using the provided information. 2. If answerable, provide a concise answer, preferably in a single phrase or sentence. 3. If not answerable based solely on the given chunks, write "unanswerable". Retrieved text chunks: {retrieved_chunks} Query: {user_query} Answer:
* 如果是 unanswerable,則改用 Long-Context 放全文。如果可以回答則只用 chunks
* 使用 Gemini-1.5-Pro 时,約 82% 可以用這招就解決,只有 18% 需要改用 Long-Context。如此大大減少了需要處理的 tokens 數量,降低成本。
* Long Context RAG Performance of LLMs
* https://www.databricks.com/blog/long-context-rag-performance-llms
* https://ihey.cc/rag/long-context-rag-performance-llms/
* 對於大多數模型來說,存在一個飽和點,超過該點後性能會下降,例如:gpt-4-turbo 和 claude-3-sonnet 為 16k,mixtral-instruct 為 4k,dbrx-instruct 為 8k
* 最近的模型,如 gpt-4o、claude-3.5-sonnet 和 gpt-4o-mini,已改善長上下文行為,隨著上下文長度增加,表現幾乎沒有下降。
* In Defense of RAG in the Era of Long-Context Language Models (2024/9)
* https://arxiv.org/abs/2409.01666
* https://ihey.cc/rag/in-defense-of-rag-in-the-era-of-long-context-language-models/
* 用 Llama3.1-8B & Llama3.1-70B
* Inference Scaling for Long-Context Retrieval Augmented Generation (2024/10)
* 用 Gemini 1.5 Flash
* 整理在 [[RAG 開發知識庫]]
* Long Context vs. RAG for LLMs: An Evaluation and Revisits (2024/12)
* https://arxiv.org/abs/2501.01880
* 整理有關長文本的 papers
* 推薦 [[RAPTOR]]
* BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack (2024/11)
* https://arxiv.org/abs/2406.10149
* https://x.com/cwolferesearch/status/1869409312239415696 (2024/12/18)
* LLMs 只能有效利用了 10-20% 的上下文,且隨著推理複雜性的增加,其表現急劇下降
* 大多數 LLMS 在回答超過 10,000 個詞元的文本中的事實問題時都很困難
* Fiction.LiveBench https://fiction.live/stories/Fiction-liveBench-Mar-25-2025/oQdzQvKHw8JyXbN87
## Needles 測試
Arize 的 The Needle In a Haystack Test
https://arize.com/blog-course/the-needle-in-a-haystack-test-evaluating-the-performance-of-llm-rag-systems/
Two needles 測試
https://twitter.com/mosh_levy/status/1762027624434401314 2024/2/26
paper: Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models (2024/2/19)
https://arxiv.org/abs/2402.14848
https://twitter.com/LangChainAI/status/1769072214878650377
Multi Needle in a Haystack https://blog.langchain.dev/multi-needle-in-a-haystack/ (2024/3/13)
https://twitter.com/RLanceMartin/status/1769439202008060098 2024/3/18
paper: https://arxiv.org/abs/2310.01427 (2023/9/28)
https://twitter.com/aparnadhinak/status/1757073620612923785 (2024/2/23)
https://twitter.com/aparnadhinak/status/1766161976529711298 (2024/3/9)
另一個測試,但沒看懂重點
數星星測試 https://twitter.com/9hills/status/1775353958472794391
https://twitter.com/LouisKnightWebb/status/1778105204941988244 (2024/4/11)
## 其他評測
* LOFT: Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More? (2024/6)
* https://arxiv.org/abs/2406.13121v1
* Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries (2024/9)
* https://arxiv.org/abs/2409.12640
* https://x.com/oran_ge/status/1837691213597888774
* 這是 Google 做的評測,分數是 Gemini 排第一
* https://x.com/_philschmid/status/1845388446354792813 (2024/10/13)
* 
* Oolong: Evaluating Long Context Reasoning and Aggregation Capabilities
* https://oolongbench.github.io/
* https://x.com/abertsch72/status/1986842177692180497 (2025/11/8)
## 分析 RAG noise 噪音
* The power of noise (2024/1)
* https://arxiv.org/abs/2401.14887
* 將隨機文件添加到提示中可以將 LLM 的準確性提高多達 35%
* 噪音也有用
* Pandora's Box or Aladdin's Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models (2024/8/24)
* https://arxiv.org/abs/2408.13533
* https://x.com/omarsar0/status/1830984315326660617
* 雖然有害噪音通常會損害性能,但有益噪音可能會增強模型功能和整體性能的多個方面
* 有益噪音(語義、數據類型和非法句子)
* 語義噪音: 與查詢的語義相關性低的內容,通常是偏題或偏離預期意義
* 資料類型噪音 (DN) 這種類型的噪音指的是在網路上不同資料類型的混合
* 非法句子噪音 (ISN) 網頁內容可能包括不形成語法正確句子的片段,例如「歷史 轉換 蓋子 管理 那隻 黑色 的 手」。
* 有害噪音
* 反事實噪音: 虛假資訊,包括假新聞和過時的知識
* 支持性噪音: 高語義相關性但缺乏相應答案信息的文件
* 正字法噪音: 指書寫錯誤,例如拼寫錯誤和單詞延長
* 先前知識噪音: 基於錯誤假設或前提的問題
* 為什麼有益的噪音對 RAG 系統產生正面影響?
* H1: 更清晰且更明確的推理過程
* H2: 更標準化的回應格式
* H3: 在黃金背景下增強信心
* Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG (2024/10/8)
* 對於強大的檢索器,性能呈現「倒 U 型模式」
* 性能最初有所改善,但隨著更多段落的加入而下降。這一現象歸因於檢索到的「困難負樣本」的有害影響
* https://arxiv.org/abs/2410.05983
* https://www.threads.net/@u8621011/post/DA9sBxWSRqg
* https://x.com/LargitData1/status/1844396363460771841
* https://x.com/BowenJin13/status/1844399090747994613
* 困難負樣本: 與問題相關但不包含正確答案的文本段落。這些段落會誤導模型,導致效能下降
* 解法: 檢索重排序 和 微調
* LLMs 顯示出優先考慮輸入序列開頭和結尾所呈現的信息,而對中間部分的關注較少。
* Toward Optimal Search and Retrieval for RAG (2024/11/11)
* https://arxiv.org/abs/2411.07396
* 較低的搜索準確性對 RAG 性能的影響較小,同時可能提高檢索速度和記憶效率