對複雜的文件和影像進行 QA
* https://medium.aiplanet.com/multimodal-rag-using-langchain-expression-language-and-gpt4-vision-8a94c8b02d21 (2023/12)
* 三種作法:
* 圖像embedding(OpenCLIP)
* 圖像摘要成文字,生成時用摘要文本
* 圖像摘要成文字,生成時用原圖像
* 用 Unstructured 從 PDF 中提取文字和圖像
* https://levelup.gitconnected.com/multimodal-rag-pipeline-three-ways-to-build-it-169782cffaca (2024/11)
* paper: Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
* https://arxiv.org/abs/2410.21943
* https://x.com/omarsar0/status/1851479149690642456 (2024/10/30)
* https://huggingface.co/blog/Kseniase/html-multimodal-agentic-rag
## 直接針對整頁 PDF 圖片做檢索
* [[Colpali]]
* https://x.com/_avichawla/status/1921454252209443323 (2025/5/11)
- 多模態的 embedding model
- From Text-RAG to Vision-RAG
- https://maven.com/p/77ddb8/from-text-rag-to-vision-rag-w-vp-search-cohere
- 投影片 https://drive.google.com/file/d/1ZrHmg3iCMMqPQ126OblO0X3YbCWLAjyO/view?ck_subscriber_id=2949928052&sh_kit=742502b08a729db6a9caedc255e17147cf415d18dac03dd5e30bb5707280912d
- 用 Cohere Embed 4 https://cohere.com/blog/embed-4
- https://colab.research.google.com/drive/1RdkYOTpx41WNLCA8BJoh3egQRMX8fpJZ?authuser=0&pli=1#scrollTo=hpJ5XpwjsKXa
## langchain
https://twitter.com/RLanceMartin/status/1713638963255366091
https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
https://www.analyticsvidhya.com/blog/2024/09/guide-to-building-multimodal-rag-systems/ (2024/9/30)
## 投影片實驗
* 2023/12/8
* https://twitter.com/rlancemartin/status/1732862263026135197
* https://blog.langchain.dev/multi-modal-rag-template/
* 圖片 OpenCLIP embedding
* GPT-4V 圖片摘要 ([[Multi-Vector Retriever]]),推薦這種效果最好,只是需要先生成摘要有成本
## llamaindex
- [ ] https://docs.llamaindex.ai/en/latest/module_guides/models/multi_modal.html# 最下方有一些資料整理
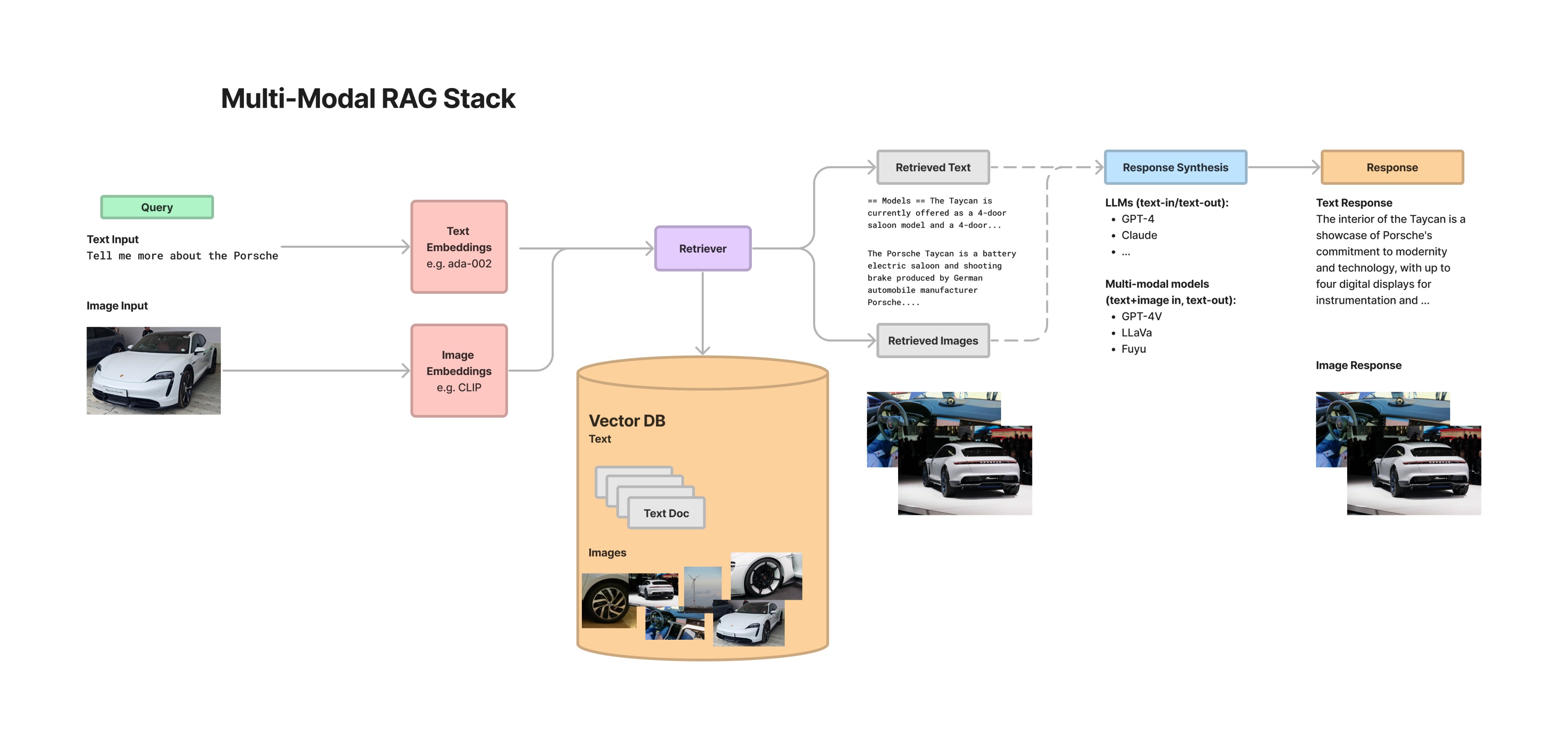
https://twitter.com/jerryjliu0/status/1723076174698672417
* blog https://blog.llamaindex.ai/multi-modal-rag-621de7525fea
* 教學 tweet https://twitter.com/clusteredbytes/status/1727741878970314964 (2023/11/24)
* 
* 一個 MultimodalQueryEngine 範例 https://x.com/llama_index/status/1835813824005583313 (2024/9/17)
* https://levelup.gitconnected.com/exploring-multimodal-rag-with-llamaindex-and-gpt-4-or-the-new-anthropic-sonnet-model-96705c877dbb
* llamaparse 就處理了圖片轉成 md 文字
* 生成階段是 文字+圖片 一起給模型
* 做成 LlamaCloud 服務了 https://www.llamaindex.ai/blog/multimodal-rag-in-llamacloud