想系統性學習如何打造 LLM、RAG 和 Agents 應用嗎? 歡迎報名我的課程 大語言模型 LLM 應用開發工作坊
Updated(2024/5/14) 更新上 GPT-4o (o200k_base),這次 OpenAI 有更換 Tokenizer 進步非常非常多。
Updated(2024/4/21) 更新上 Llama 3,這次 Meta 有更換 Tokenizer 進步非常非常多。
話說大語言模型 LLM 的運算和推論成本都是用 Tokens 數量來計算的,輸入的內容都得轉成 Tokens 序列來運算,輸出則轉回來。
但是呢,其實每一家用的 Tokenizer (分詞器)都不太一樣,因此相同的文本,拆出來的 tokens 數量是不一樣的。因此很多模型的推論成本比較、Context window 長度限制比較等等,實際應用時都不太準確,特別是非英文的語言,各家差異非常大。
一樣的文本,若能用比較少的 Tokens 數來運算,推論速度會比較快、成本(運算資源)也會比較划算,畢竟計價也是用 tokens 數計算的,先予敘明。
具體會差多少,以下是我的測試結果,使用了繁體中文約八萬多個字(政府報告和管理學講義)做出來的實驗結果。另外也做了英文也是約八萬字(兩篇部落格文章)。
繁體中文
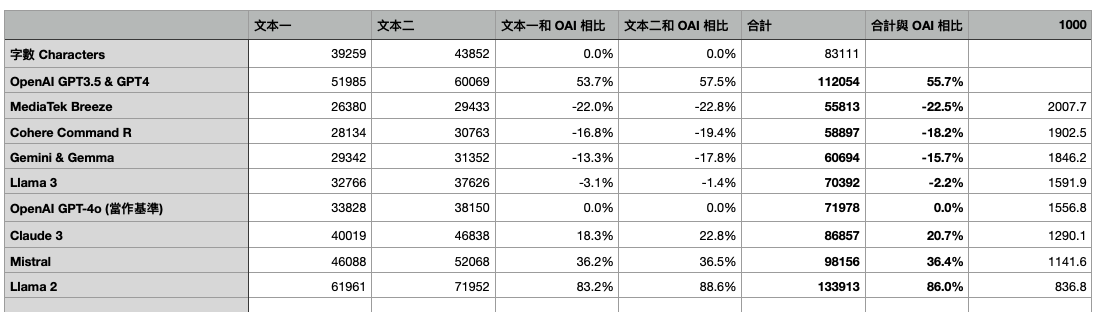
先看大家關心的繁體中文結果,以 OpenAI GPT3.5 (cl100k_base)為基準來比較的話:
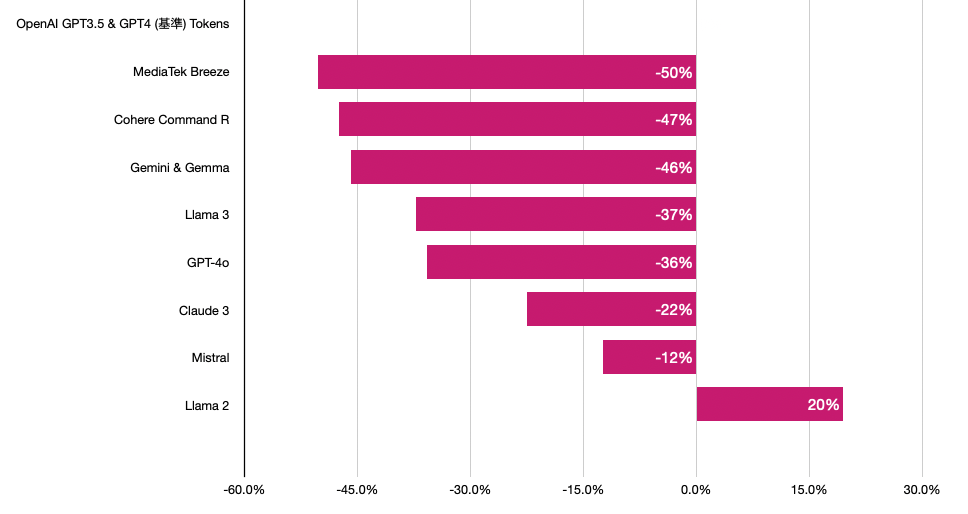
沒想到差距竟然可以達到兩倍這麼多,除了 Llama 2 之外都比 GPT3.5 & GPT-4 還要節省 Tokens 數,GPT3.5 和 GPT-4 的 Tokenizer 對繁體中文真的很不友善啊! 直到最新的 GPT-4o 有大幅改進!
- 表現最好的是聯發科 Breeze 約節省 50% 的 tokens 數 👍👍👍 果然是針對繁體中文最佳化
- Cohere Command R+ 約節省 47% 👍👍👍
- Google Gemini 約節省 46% 👍👍👍
- Llama 3 比 gpt-3.5 約節省了 37% 👍👍
- 新的 gpt-4o (o200k_base)比 gpt-3.5 約節省 36% 👍👍
- Claude 3 約節省 22% 👍👍
- Mistral 約節省 12% 👍
- Llama 2 比 gpt-3.5 還差,還增加了 20% 😱
讓我換句話說:
- 1K MediaTek Breeze Tokens 約等於 2K GPT-3.5 Tokens
- 1K Command-R Tokens 約等於 1.9K GPT-3.5 Tokens
- 1K Gemini Tokens 約等於 1.8K GPT-3.5 Tokens
- 1K Llama 3 Tokens 約等於 1.6K GPT-3.5 Tokens
- 1K GPT-4o Tokens 約等於 1.6K GPT-3.5 Tokens
- 1K Claude 3 Tokens 約等於 1.3K GPT-3.5 Tokens
- 1K Mistral Tokens 約等於 1.1K GPT-3.5 Tokens
- 1K Llama 2 Tokens 約等於 837 gpt-3.5 Tokens (表現比 OpenAI 還差)
總之,以後看各家模型的 Token 成本和 Context Window 限制時,都得分別心底換算一下了。
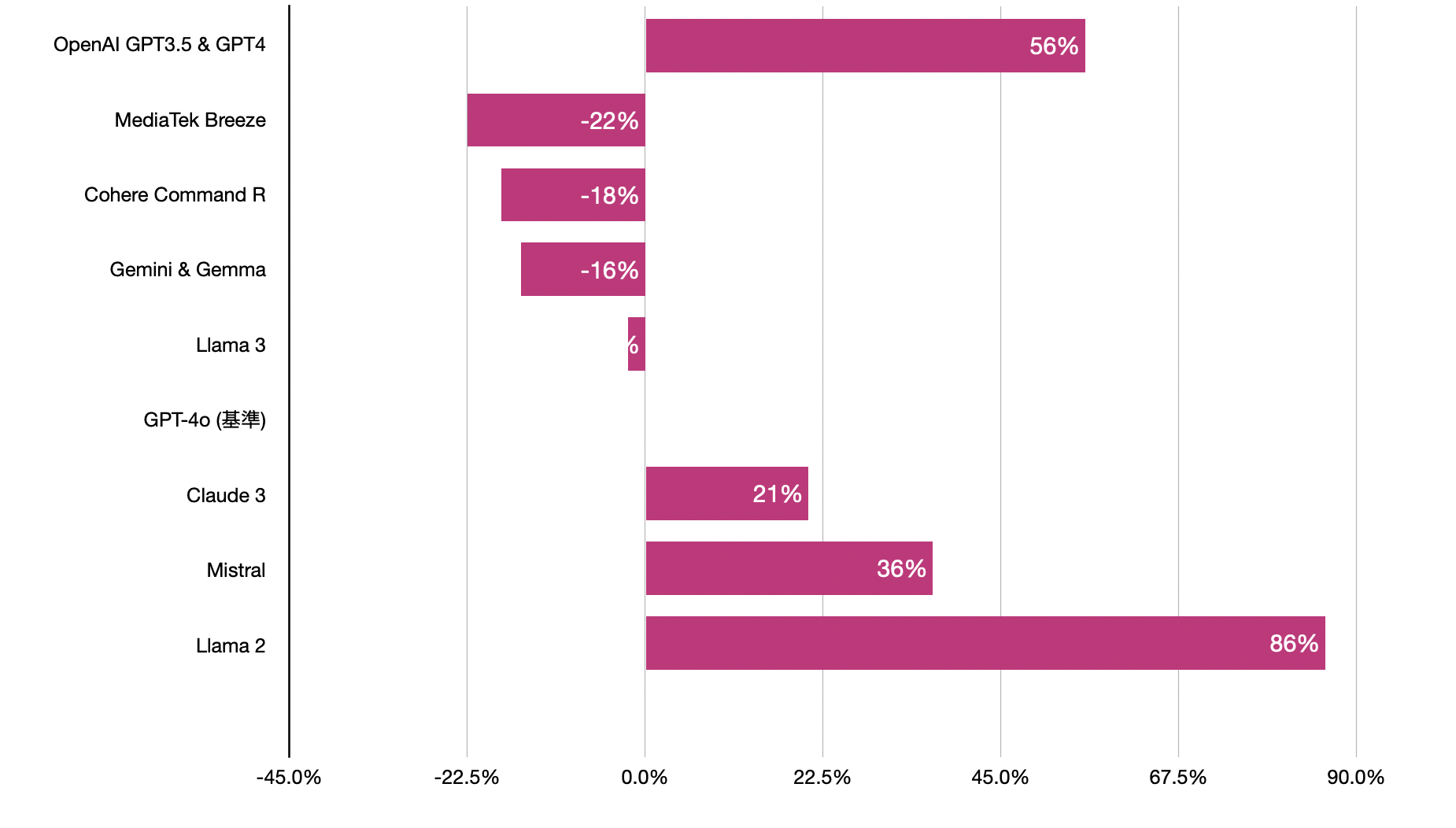
Updated: 以下改用 gpt-4o 做基準來畫圖
56% 意思就是 gpt-4 比 gpt-4o 多用 56% 的 tokens,而 Breeze -22% 則是節省 22% 的 tokens。
英文
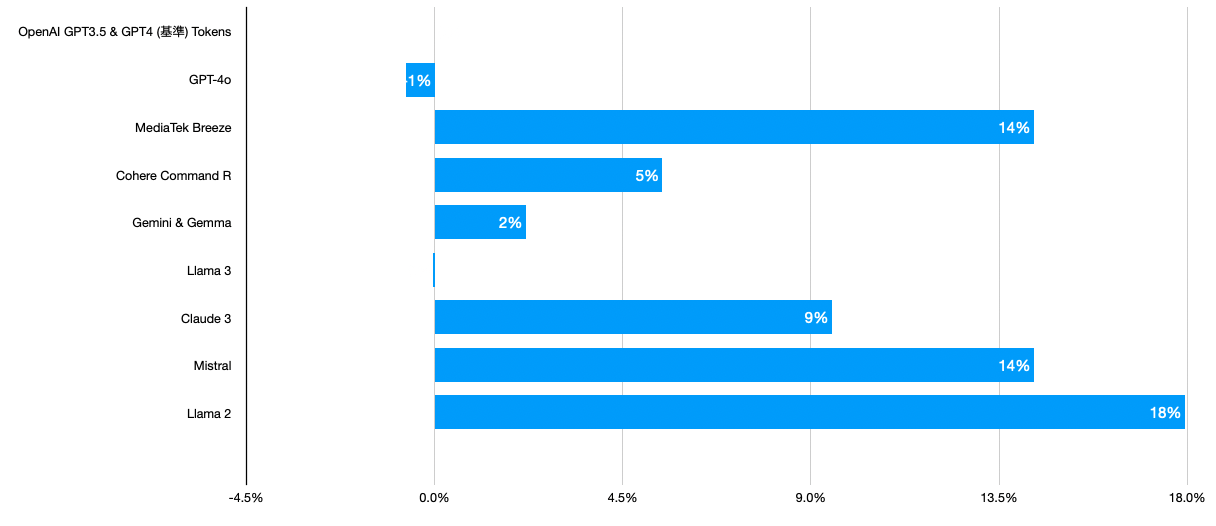
結果跟繁體中文差異很大,這裡 OpenAI 和 Llama 3 並列第一最省 tokens 數,其他家都會花比 OpenAI 多一些的 tokens 數。Llama 2 敬陪末座。
實驗方法
以下是使用的文本和數據
- 中文文本一是 數發部 立法院第11屆第1會期交通委員會數位發展部業務概況報告.pdf
- 中文文本二是 司徒達賢策略管理講義 前五章內容
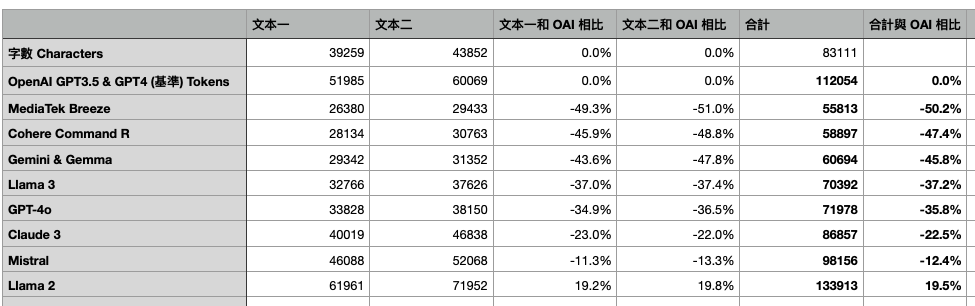
- 英文文本一是 We’re all Stochastic Parrots
- 英文文本二是 How I Won Singapore’s GPT-4 Prompt Engineering Competition

計算方式
- OpenAI 是用 platform.openai.com/tokenizer 計算的
- Gemini, Mistral, Llama 和 Cohere 是用 huggingface.co/spaces/Xenova/the-tokenizer-playground 算的,我有用 Gemini 後台跟 Cohere API 確認是一樣的。
- Claude 3 沒找到工具可以自己算,我只能實際用 Claude API 呼叫後,查看回傳的 tokens usage 數
- Breeze 7B 則是在我本機自己安裝跑的 huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0
其他別人做的 Non-English 評測
- 有受到這篇的啟發,不過他把 Non-English Text 混一起,不知道是怎麼計算的
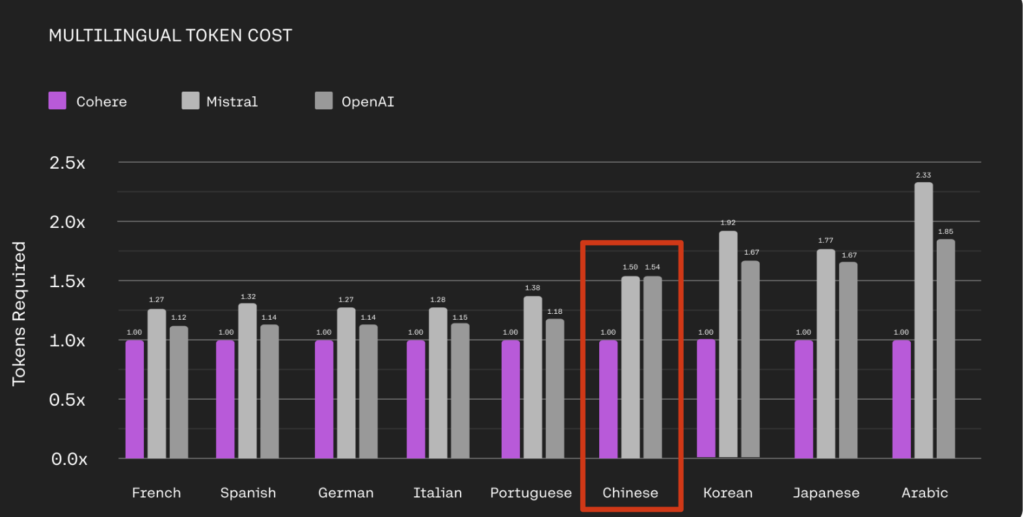
- Cohere Command R+ 官方也有做比較,Chinese (簡體中文吧?) 和 OpenAI 相差 1.54 倍
關於 Tokenizer 的科普知識
- 推薦 YC 的解說: 為何擁有好的中文詞表是重要的 (對於中文語言模型)
- 推薦 Andrej Karpathy 大神的教學影片 Let’s build the GPT Tokenizer 有很詳細的 Tokenizer 和 Byte Pair Encoding 原理解說。