
話說 OpenAI 今年一月新出的 Embeddings 模型(將文字轉成語意向量),可以透過傳參數指定不同的維度大小,這背後使用的是一種叫做 Matryoshka 俄羅斯套娃的嵌入表示方式,非常酷。
Paper: Matryoshka Representation Learning
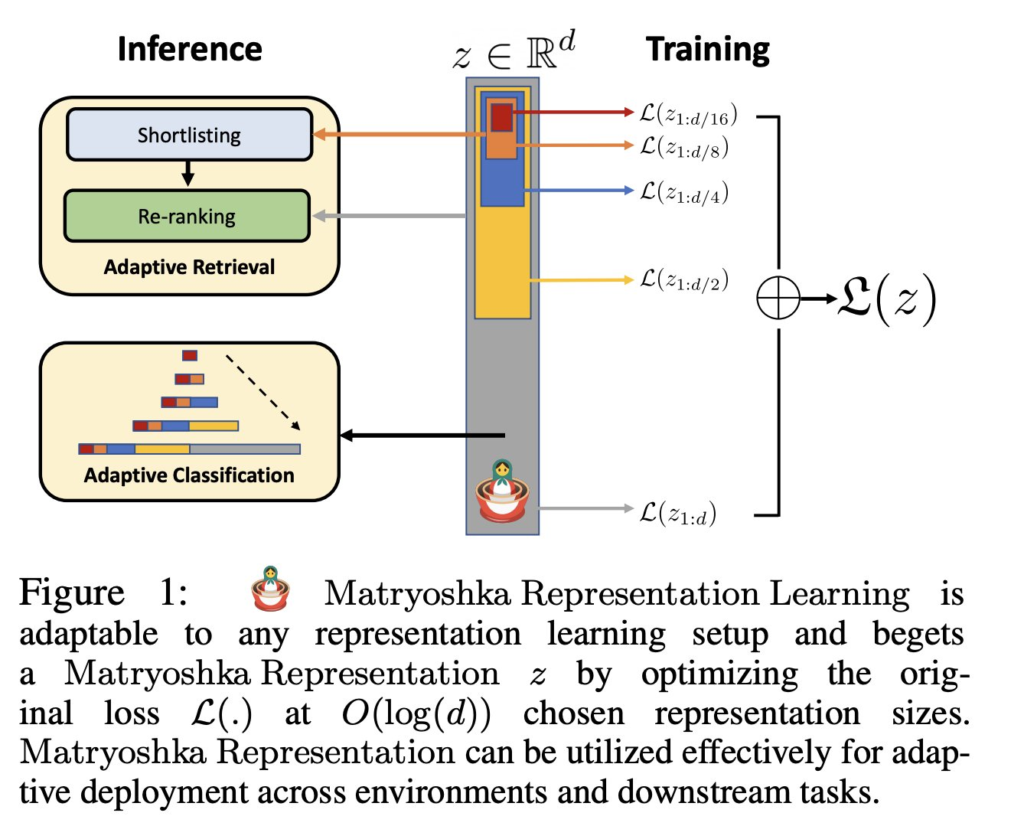
這酷的地方在於,你可以丟棄任意長度的尾部,僅使用開頭也是有效的!
例如呼叫 text-embedding-3-large 模型得到 3072 高維度的向量後,可把後面 2048 個數字丟棄,只使用前面 1024 個也是有效的。
只要做個向量正規化(normalization)調整一下長度單位, 就會得到跟傳 1024 維度參數得到的向量數字一模一樣!
這有什麼用呢? 可以做多層檢索加速,準備階段只需要呼叫模型算一次高維度,你就可以自己縮小到不同維度存下來。
向量搜索時,先用低維度例如 256 維度初步篩選一次(可用ANN加速),這會比較快因為維度低。
接著再用 3072 高維度來排序過濾第二次(可用KNN更準),這樣就精準啦。
補充(2024/7/23):
Weaviate 寫了一篇 OpenAI’s Matryoshka Embeddings in Weaviate 介紹