Hello! 各位 AI 開發者大家好 👋
我是 ihower,農曆新年的腳步接近,先在這裡祝福大家新年快樂,萬事如意,財源滾滾! 🧧🧨
🔝 Common pitfalls when building generative AI applications
這篇 Chip Huyen 寫的 “生成式 AI 應用開發的常見錯誤”,歸納出 6 個容易踩雷的地方,實在心有戚戚焉啦。以下結合原文與我自己的經驗,整理出以下六個觀點:
1️⃣ 不該用生成式 AI 的場景硬要用生成式 AI
大模型 LLM 是很厲害,但是很多人對於這項技術的能力不夠了解,硬要把不適合的需求塞給它處理。例如: 最佳化能源消耗、用來檢測流量異常、用來預測電量、檢測病人是否營養不良等等,其實都不適合用生成式 AI 來做。
我個人也碰過公司想要做些營運最佳化和異常檢測,細問才發現資料都是數字型態。這種不是用生成式 AI 啦,而是應該用專門的演算法或是機器學習來做。
2️⃣ 搞混「爛 AI 產品」與「笨 AI 模型」
很多失敗案例其實不是 LLM 模型不夠聰明,而是產品設計和 AI 工程能力的不足。
例如最近最火熱的 AI Coding 產品為例,無論是 GitHub Copilot、Cursor、Windsurf 還是 Devin,背後用的往往都是一樣的 LLM,差別在於產品設計與 AI 工程做得好不好。所謂的 AI 工程能力,主要是指如何有效提供模型所需的 context(透過 prompt chaining、RAG 等技術),讓模型能在正確資料的基礎上產生有用的結果。若缺乏這些工程環節,再強大的模型也只能”巧婦難為無米之炊”
因此你會看到出現 o3 這種可以解決奧數的聰明模型,又同時看到 Devin 處理實際的軟體開發任務還做不好。根本原因可能不是模型太弱,而是整合的 AI 工程還不夠完善。
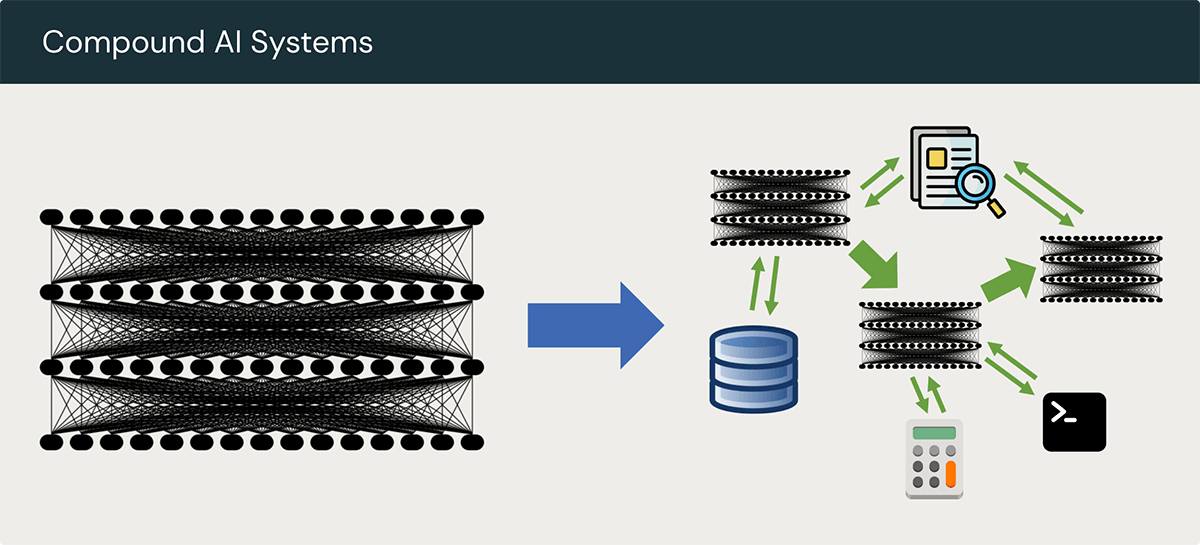
最近看到一句話是 raw intelligence ≠ intelligent software systems「原始智力」不等於「智慧軟體系統」
大模型的「智力」只是基石,要把它轉化成真正有效的智慧系統,還需要正確的上下文、工具整合以及成熟的工程化流程,這就是 Berkeley AI Research (BAIR) 所提出的 The Shift from Models to Compound AI Systems 的趨勢:領先的 AI 成果越來越依賴「多重元件」協作,而非單純依賴一個大型模型,才能發揮 LLM 的最大潛能,做出好用的 AI 產品。
3️⃣ 一開始就搞得太複雜
常見的過早複雜化包括 1. 不需要時就用 agent 框架 2. 糾結選擇向量資料庫 3. 明明 prompting 就足夠還要搞 fine-tuning 等等。太早引入複雜的工具會抽象掉關鍵細節,讓系統更難理解和除錯。
4️⃣ 過度樂觀看待初期成功
我之前也分享過的 LinkedIn 開發經驗: 從 0 到 80% 只花一個月,但從 80% 到 95% 卻花了四個月,最後那 10-20% 的優化往往最耗時難度最高。做出一個 Demo 很容易,但要做出一個真正能上線的產品卻很困難: 幻覺、延遲、準確度與效能的權衡、Prompt 設計、評估等等等,這些在開發後期都是大考驗。
5️⃣ 忽視人工評估
雖然用 AI 來評估 AI (LLM-as-judge)很方便,但不能完全依賴。最好的團隊都會每天抽樣做人工評估(30-1000 例),用來補充他們的自動化評估, 並且可以 1. 驗證 AI 評估的準確性 2. 了解用戶使用情況 3. 及早發現異常模式
6️⃣ 盲目蒐集使用案例
不少企業想做 AI 數位轉型,但對於目標不夠明確(就是一種我知道 LLM 很厲害,但我不知道可以用在哪裡),於是就讓員工天馬行空地提案來個黑客松,搞出一大堆重複的小專案(像是到處都在做聊天機器人或是各種插件)。然後 AI 開發團隊就被這些零碎、影響力有限的專案分散注意力,最後公司得出 “生成式 AI 投資報酬率不高” 的結論。這裡建議應該要有大局觀和整體策略,專注在真正能帶來高價值的應用上,這樣才能有最大的回報。
以上,對於正在規劃或開發 AI 應用的團隊來說,這些坑都蠻常見的,不只是技術問題,也需要有清楚的策略和務實的工程思維啊。
更多討論在我 Facebook 貼文。
🧠 o1 isn’t a chat model
“OpenAI o1 不是一個聊天用的模型,而是一個報告產生器!” 最近看到這種說法覺得很貼切,也符合我最近的使用體驗 😀
ChatGPT 去年底推出的推理型 o1 模型是一種不同類型的模型,它會先內部思考後才回答你。你需要用不同的 prompting 方式來使用它。
最近看到越來越多人在討論分享如何針對 o1 模型下 prompt,有看到一篇不錯的經驗分享文章(連結在留言),整理一些重點如下:
- 這不是一個聊天模型,而是一個報告產生器!
- 盡可能提供更多參考資料(Context),並清楚說明您的需求和目標(Goal)
- 不需要花時間雕琢 prompt 提示詞,而是要塞更多問題描述和大量背景資訊
- 不要跟它說 “how”,只要說 “what”,專注在給目標而不是給方法
- prompt 可以包括 criteria 如何判斷輸出好跟壞的標準,這樣 o1 可以更好自我改進、修正錯誤
- o1 擅長生成完整報告和分析、解釋複雜概念、一次處理大量內容
- o1 不擅長用特定的寫作風格
- 跟 o1 互動更像是寫 email 求助而不是聊天: 你會一次給比較完整的背景資料和所有資訊給對方
以下截圖是文章中的 o1 prompt 範例:

注意: 以上 tips 對於一般模型例如 gpt-4o, claude, gemini 等不適用喔
更多討論在我 Facebook 貼文。
👍 The 6 AI Engineering Patterns In 2025
由 Greg Kamradt (現為 ARC Prize 的 President) 撰寫的這篇 “The 6 AI Engineering Patterns In 2025” 講了 AI 工程包括哪些東西,以及一些學習資源:
1. Models (模型)
- 主流模型包括 OpenAI、Anthropic Claude、Google Gemini、Meta’s Llama 等
- 理解不同大小模型的特性和使用場景
- Function Calling
- 最佳化效能和成本
- Straming 串流和快取等技巧
2. Prompting (提示工程)
- 無需記 prompt 樣版,只要記得用清晰指令描述需求
- CoT (Chain of Thought)
- Few-shot examples
- 結構化 prompt,越來越推薦多用 XML 標籤了
- Structured Outputs 結構化輸出是關鍵技巧
- prompt 管理
3. Context (RAG 應用)
- 檢索出最相關能回答用戶的參考資訊
- 分塊 chunking、查詢理解 query understanding 是常見挑戰
- 即使模型支援長 context windows,但太長的 contexts 仍影響性能和成本
4. Orchestration 和 Agents (編排和代理人)
- 自動化完成複雜任務
- 目前主要應用在銷售線索(lead generation)和程式開發(AI coding)
5. Evals (評估觀察)
- 觀察工具對除錯、性能和成本優化很重要
- 建議使用 LangSmith 等工具
6. Mindset (心態)
- 要有快速學習的心理準備,接受這個領域資訊衰退的速度很快
- 快速實作原型驗證想法,善用 Cursor, v0, Windsurf 等工具
- 實驗新功能和使用案例,例如 Claude MCP 和 OpenAI Realtime API 等
📚 The 2025 AI Engineer Reading List
過年在家有什麼計劃嗎? 來看論文吧!這是由 Latent Space 精選的 50 篇 AI 論文,涵蓋 LLMs, Benchmarks, Prompting, RAG, Agents, CodeGen, Vision, Voice, Diffusion, Finetuning 等等。
還看不夠的話,還有 Sebastian Raschka (從頭打造 LLM (大型語言模型) 實戰秘笈這本書的作者)整理的 2024 最值得注意的論文:
📊 Anthropic Clio: A system for privacy-preserving insights into real-world AI use
Anthropic 發了一篇 paper 講他們開發了一套 Clio 系統,如何透過對大量 Claude 使用者對話進行匿名化與聚類分析,來了解實際上大家如何使用語言模型。
技術上如何強調匿名保護隱私就不多解說了,來分享一些有趣的洞察。首先是主要使用案例的比例:
- 網頁與行動應用程式開發 (10.4%)
AI Coding 正夯,有 10% 對話與「Web 和 Mobile app 程式開發」相關,Claude Sonnet 3.5 的 coding 能力和 Artifacts 介面真的是太強了。
- 內容創作與溝通 (9.2%)
- 學術研究與寫作 (7.2%)
- 教育與職業發展 (7.1%)
- 進階 AI/ML 應用 (6.0%)
- 商業策略與運營 (5.7%)
- 語言翻譯 (4.5%)
- DevOps 與雲端基礎設施 (3.9%)
- 數位行銷與 SEO (3.7%)
- 數據分析與視覺化 (3.5%)
還有一些比較小眾有趣的也被分析出來:
- 解釋和分析夢境
- 足球比賽分析
- 填字遊戲的提示
- 角色扮演遊戲: 龍與地下城
- 最佳化和建模交通系統及流量
- 計算單字「strawberry」中的 r 的數量….
另外,不同語言呈現各自特色,某些主題在非英語對話中更常見,例如
- 中文用戶特別偏好犯罪、驚悚、懸疑小說的創作,比例是其他語言的 4.4 倍
- 日語用戶喜歡創造和分析動漫內容,是 6.8 倍
- 西班牙語用戶喜歡解釋和分析經濟理論與實務,3.5 倍
更多討論在我 Facebook 貼文。
🌟 OpenAI Realtime API Agents Demo
OpenAI 默默發了一個 Realtime API Agent Demo,示範如何打造 多代理人語音即時應用 (mutli-agents realtime voice app) 🗣️🗣️
範例中有定義兩個比較複雜的場景:
- 零售客服 語音對話 (包括 身份驗證 agent, 退貨流程 agent, 銷售 agent )
- 導覽客服 語音對話 (包括 身份驗證 agent, 導覽 agent)
過程首先都是 身份驗證 agent 先接待你收集資料,完成後才會交接給下一個 agent。
程式是用 Next.js + TypeScript 寫的,交接採用跟 OpenAI Swarm 一樣的概念,我之前的 Agent 投影片有講。
(對工程師來說)跑起來很容易,只要 git clone 回去用 npm 把 server 跑起來就可以玩了。
🎁 最大的彩蛋是裡面有個可以產生 Agent Instruction 的 meta-prompt (連結放留言),這個用來產生 prompt 的 prompt 產生出來的 prompt 值得學習一下。
它會根據你給的描述,協助定義 Agent 的人設跟語調,還包括一個流程狀態機! 沒想到這裡也可以用偽代碼寫法啊,厲害。
這是我測試的產出結果: gist link,可以看到 Conversation States 的部分就是偽代碼,定義了流程。我輸入的 agent 描述是 “賣電腦書的推銷員, 請先引導用戶搜尋關鍵字(呼叫 search_project function),然後加入購物車(呼叫 add_to_cart function)”
- 直接看 meta-prompt: 修改 user_input 那行填入你的 agent 描述,然後整段貼到 ChatGPT 產生
- 也可用 Voice Agent Metaprompt GPT 產生 agent 指示
更多討論在我 Facebook 貼文。
🛠️ The Dawn of GUI Agent
關於 GUI Agent 代理的能力,看到一篇 paper: The Dawn of GUI Agent 針對 Claude 模型的 Computer Use 功能做了詳細的評測。
評測的案例結果如截圖,我也把用戶指令做了簡單翻譯如下。可以快速了解一下目前 GUI Agent 的能力到哪裡。
網頁搜尋:
- ✅ amazon 網站: 將一組價格在 100 美元或以下,具有主動降噪功能的無線耳機添加到購物車。
- ✅ apple 網站: 將配備奈米紋理的 Pro Display XDR 顯示器連同所有配件一起放入袋中,並檢查總計
- ❌ Fox Sports 網站: 將 formula 1 添加到我在 Fox 上關注的運動項目中
工作流程:
- ✅ 開啟 Apple Music,前往「新內容」分頁,找到「最新歌曲」下的第一首歌,並將其添加到名為「Sonnet 的精選」的播放清單中。向下捲動以找到相同分頁下的「新加坡百大」合輯。將「新加坡百大」中的第一名歌曲添加到「Sonnet 的精選」播放清單中。
- ✅ amazon 網站 + Excel 操作: 在 Amazon 上搜尋 27 吋、165Hz 電競螢幕,將前兩個搜尋結果的產品名稱和價格記錄到 Excel 試算表中。
- ✅ Google Sheet + Excel 操作: 匯出並下載 Google 試算表,然後在本地開啟
- ✅ 在 App Store 搜尋「GoodNotes」。點擊取得並安裝以將其下載到我的裝置。檢查並回報其大小。
辦公室生產力:
- ✅ Outlook: 將 Anthropic 寄來的最新電子郵件從 Outlook 轉寄。請仔細找到右上角的「轉寄」選項。然後將電子郵件轉寄給「[email protected]」,並抄送「[email protected]」
- ✅ Word: 將文件佈局改成A3 尺寸紙張,橫向擺放
- ✅ Word: 將文件排版從單欄改成雙欄
- ❌ Word: 更新履歷範本上的姓名為 Sonnet 和電話號碼改成 7355608
- ✅ Powerpoint: 在新空白投影片中,將預設背景替換為漸層填滿背景。
- ✅ Powerpoint: 新增投影片標題為「Triangle」,並插入相對應的形狀
- ❌ Powerpoint: 在第二張投影片的文字中新增編號符號
- ✅ Excel: 把 $ 替換成 SGD 在目前的 worksheet
- ❌ Excel: 在缺失的「總計」中插入一個函數來計算「實際」欄的總和
玩遊戲:
- ✅ 爐石戰記: 讓我們開始建立一個新的法師牌組來玩。選擇「核心法師」預設牌組,建立後將其重新命名為「Sonnet 的新牌組」
- ✅ 爐石戰記: 你可以用你的小兵攻擊,或使用法師的英雄
- ✅ 崩壞: 星穹鐵道: 你的目標是為我執行 10 次扭曲拉取。按下鍵盤上的 Escape 鍵打開選單,然後點擊扭曲,它應該會打開扭曲頁面,左側的第一個項目將是「忍者之眼」,這將是目的地池。然後點擊「扭曲 x10」執行 10 次扭曲拉取,然後點擊右上角的空白處以顯示右上角的箭頭,然後點擊箭頭跳過動畫。如果右上角有箭頭,請始終點擊箭頭繼續跳過動畫。只有當所有動畫都通過點擊箭頭跳過後,才會出現拉取摘要頁面,並且那裡會有一個叉號,點擊叉號完成拉取。祝你好運!
- ✅ 崩壞: 星穹鐵道: 你的目標是幫我完成每日遊戲任務。按下鍵盤上的 Escape 鍵開啟選單,然後點擊星際導航,再點擊彈出遊戲視窗左側的「花萼黃金以獲得經驗值」項目,然後點擊「回憶之芽」(你需要仔細檢查名稱) 這個第一個項目同一行的傳送按鈕,再點擊「+」按鈕 5 次將嘗試次數增加到 6 次,然後點擊挑戰,再點擊開始挑戰。然後點擊右上角的自動戰鬥按鈕——從右到左仔細數,應該是第二個圖示,它靠近「暫停」圖示,看起來像一個「無限」符號。戰鬥完成後點擊退出。
這樣的結果,你覺得實用嗎? 😀 更多討論在我 Facebook 貼文。
📚 Thoughts On A Month With Devin
AI Coding Agent 之理想很豐滿,現實很骨感 😆
目前可以買到的最強(?)且最貴的(每月訂閱費 $500 美金) 的 AI 軟體工程師 Devin 實際用起來如何?
Devin 的操作體驗是透過 Slack 對話就可以交辦任務,它本身就有完整的工具環境(瀏覽器, 編輯器, Shell 等)可以從頭到尾幫你完成,就像你交辦任務給人類工程師一樣 (順利完成的話挺酷的🤩)
有軟體開發團隊真的用了一個月,在嘗試的 20 個真實任務中,有 14 次失敗、3 次結果不確定,僅僅 3 次成功。最糟糕的是無法預測哪些任務會成功,要跑很久才發現做錯了…. XD
他們最終放棄了 Devin,改用 Cursor (AI 輔助開發,而非 end-to-end 全自動) 逐步建立整合,效率高得多。
以下是他們做的任務列表,我簡單整理一下,分成四大類:
全新專案:
- ✅ 行星位置追蹤應用
- ✅ 將 Notion 的資料移轉到 Google Sheets
- ❓ 將多個應用程式部署到單一的 railway 部署環境中
- ❌ 產生合成數據並將其上傳到 Braintrust 監控系統
- ❌ 建立 Circleback(我的 AI 筆記工具)和 Spiral.computer 之間的整合,並附上每個工具的文件連結
- ❌ 使用 Playwright 程式從 Google 學術搜尋取得一位作者最近的 25 篇論文
- ❌ 閱讀 HTMX 文件頁面中的批量編輯範例,然後建立 HTMX 批次上傳範例應用程式
- ❌ 用 DaisyUI 和 highlight.js 套用 frankenui theme
研究執行:
- ✅ 研究如何使用 Python 建立一個 Discord 機器人,以總結每天的訊息並發送電子郵件
- ❌ 處理摘要逐字稿,具備精確時間戳記
- ❌ 建立一個最簡潔的 DaisyUI 主題作為範例
分析現有程式碼:
- ❓ 評估安全性漏洞。程式碼庫少於 700 行程式碼,結果寫入 Markdown 檔案
- ❌ 審閱一篇 Quarto 的部落格文章,並以 pull request 的方式建議修改
- ❌ 查看我之前提到的時間記錄應用程式,並給了他一個開放式的任務,請他提出任何改進建議。
- ❓ 找出當我使用 ssh key 設定伺服器時,為何 ssh 金鑰轉發無法運作的原因。
修改現有整個專案:
- ❌ 修改 FastHTML 和 nbdev 專案,跟 apple 捷徑整理
- ❌ 將一個 Python 專案遷移到 nbdev
- ❌ 將 MonsterUI 整合到我的其中一個 FastHTML 應用程式
- ❌ 新增功能以檢查使用者輸入與資料庫之間的衝突
- ❌ 建立包含每個 fasthtml 圖庫範例內容給 LLM 使用
更多討論在我 Facebook 貼文。
🎯 Leveraging User Feedback for Better RAG Systems: Lessons from Zapier Central
這是之前我上 Jason Liu 課程 Systematically Improving RAG Applications 中的一場 Guest Session,最近被免費釋出錄影了,覺得內容不錯,對做 AI 產品有幫助,簡單摘幾個重點跟大家分享。
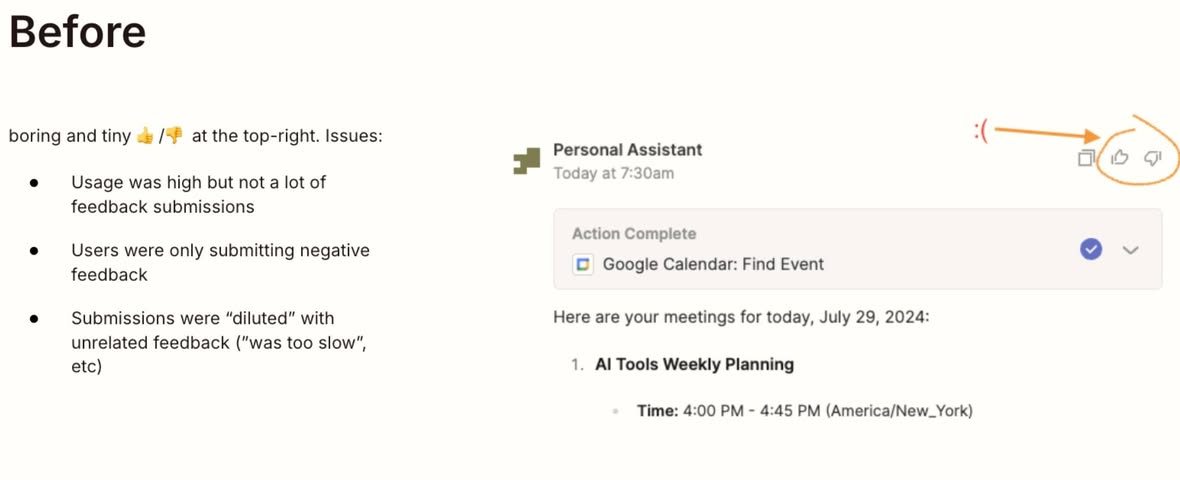
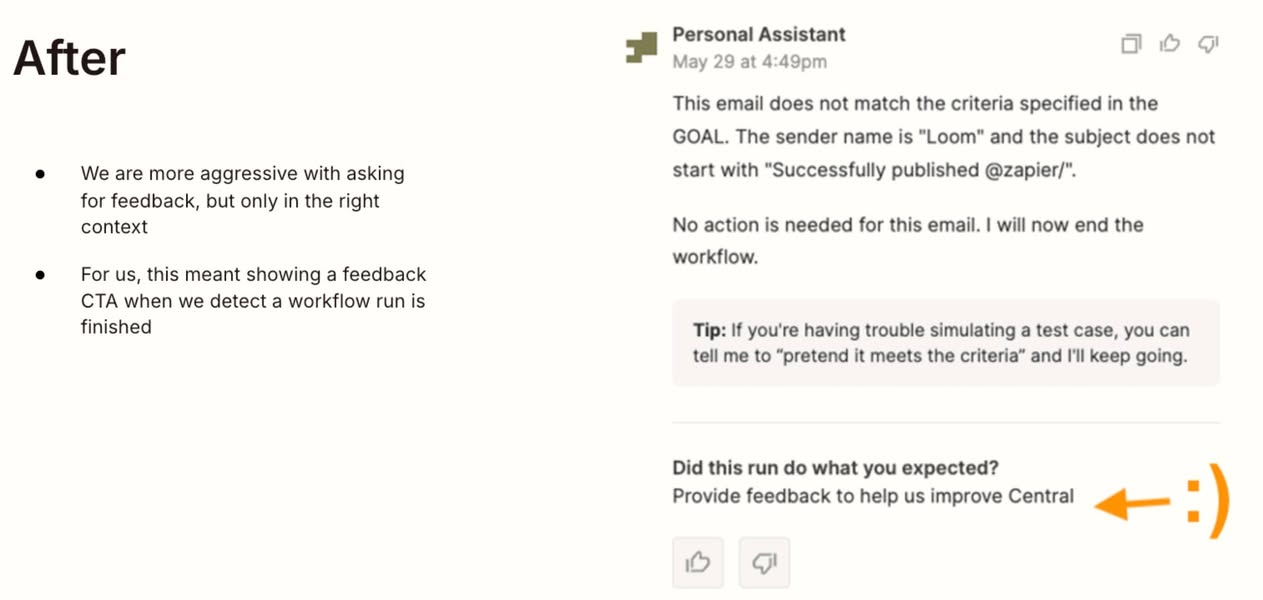
- 收集更多 feedback
- 只用簡單 thumb up 👍 跟 down 👎 並不好,人們會忽略,提交率超低,只有超不爽才會點
- 建議改成更明顯並搭配一個明確文案問題,提交率才會高 (如附圖)
- 了解資料
- 找到用戶常問但失敗的問題,轉成評估 eval 在本地重現來改進
- LLM-as-a-judge 目前不是目標,要先有足夠的人工標記範本,包括 positive 跟 negative
- 鼓勵團隊幫助標記,鼓勵看數據,要讓團隊喜歡看數據,大家一起開會做標記,每天看 raw data 都能有新的 insight 喔
- 改進產品
- 更多評估讓我們更有信心,做任何系統改變都不會對用戶帶來大問題,升級新模型時,也更有信心
- 發現問題,就加 eval 評估 (跟軟體工程中,發現 bug 就加一個 unit test 的概念類似)
更多討論在我 Facebook 貼文。
🔍 GAR: Generative AI Augmented Retrieval
新學到一招叫做 生成式 AI 增強檢索: GAR: Generative AI Augmented Retrieval (不是 RAG 喔)
也是出自 Jason Liu 課程 Systematically Improving RAG Applications 中的一場 Guest Session,最近被免費釋出錄影了。
GAR 的想法是用 LLM 來增強 lexical search (例如用 elasticsearch),利用 LLM 來增強資料,讓 BM25 做得更好,而不用改本來的 search engine 基礎設施。
講者示範了:
- 用 LLM 去修 title,去補缺失的 description,例如有商品照片但缺少內容
- 用特定的 taxonomic 分類法 (作者用 Google Product Taxonomy) ,來調整搜尋結果分數: 將用戶 query 用 LLM 判斷屬於哪一個分類,資料也會先做好分類。如果是 query 和 BM25 搜尋結果是相同分類的話,就會加權搜尋分數。詳細做法作者有給 colab 可以直接參考。
更多討論在我 Facebook 貼文。
最後推薦一個課程: Gen AI 年會與小聚的主辦人 Muyueh Lee 李慕約 的 365 AI 訂閱計劃 已經開賣啦!
對職場工作人來說,直接一整年不用煩惱追什麼 AI 工具新知,跟著李慕約陪跑學習就好啦 👍😘
更多詳細的內容在課程網頁上寫的非常完整: pse.is/6yw436
我的 $240 專屬折扣碼:IHOWER

– ihower