
Hello! 各位 AI 開發者大家好 👋
我是 ihower,今天 10/31 萬聖節快樂!祝大家有個歡樂愉快的一天,颱風天在家也請注意安全。
🔝 OpenAI DevDay 2024 重點整理
這是月初 OpenAI DevDay 2024 舊金山場的重點整理,包括
- Realtime API 你也可以做出 ChatGPT 進階語音模式在你的 app 了,這將帶來一整個新世代的語音 app
- Prompt caching 不用額外設置,命中快取就自動有 50% 折扣
- Vision fine tuning 視覺圖片微調 gpt-4o
- Model distillation & eval tools! 模型蒸餾和評估工具
👍 我的 OpenAI o1 的資料整理
OpenAI 在 9/12 推出的 o1 模型,採用了隱藏的 CoT,大幅提升了推理能力,但思考的 latency 時間也增加不少。我收集了一些資料分享給有興趣的朋友。
🎯 OpenAI Latency 和 Accuracy 最佳化文件
在 OpenAI API 文件中有兩份不顯眼 Best Practices,如果你錯過了,推薦值得一讀:
- Latency optimization 改進 Latency 的一些原則,包括一個厲害的範例
- Optimizing LLMs for accuracy 改進準確性的方向,包括 RAG 和 Fine-tuning,以及說明多少準確度算是足夠好?
🧠 Agent Frameworks 的比較討論
看了兩篇 Aparna Dhinakaran 寫的討論 Agent Frameworks 的文章,比較自行開發,或是使用 LangGraph、Llamaindex workflows 框架的優缺點,以下摘我偏愛的重點:
1. Navigating the New Types of LLM Agents and Architectures
目前業界認為實用的 Agents 架構是基於更嚴格的方式定義可以採取的可能路徑,也就是事先會定義好步驟,包括有決策條件的步驟(又叫做 Router),步驟之間可共享資料。而不是完全讓 LLM 做 Planning,例如 ReAct 的開放性特質的 Agent 這種雖然很通用但是不實用。
Q: 您是否應該使用框架來開發您的 Agent ?
我們在這個領域有相當強烈的看法,因為我們自己建造了一個助手。我們的助手使用多層路由器架構,具有分支和步驟,這些與當前框架的一些抽象相呼應。我們在 LangGraph 穩定之前就開始建造我們的助手。因此,我們不斷問自己:如果我們從零開始,我們會使用當前框架的抽象嗎?它們能勝任這個任務嗎?
目前的答案是否定的。整體系統的複雜性太高,不適合採用 Pregel 基礎架構。如果你仔細看,可以將其映射到節點和邊緣,但軟體抽象可能會造成障礙。就目前而言,我們團隊傾向於選擇程式碼而非框架。
2. Choosing Between LLM Agent Frameworks
在框架中進行除錯是困難的。這主要歸因於混淆的錯誤訊息和抽象的概念,使得查看變數變得更加困難。
如果你使用框架中的所有內容,LangGraph 運作得很順利;如果你超出這個範疇,準備好面對一些除錯的頭痛問題。
LangGraph 為你做了相當多的事情,如果你不完全接受這個框架,可能會導致麻煩;代碼可能非常乾淨,但你可能會因此付出更多的除錯成本。
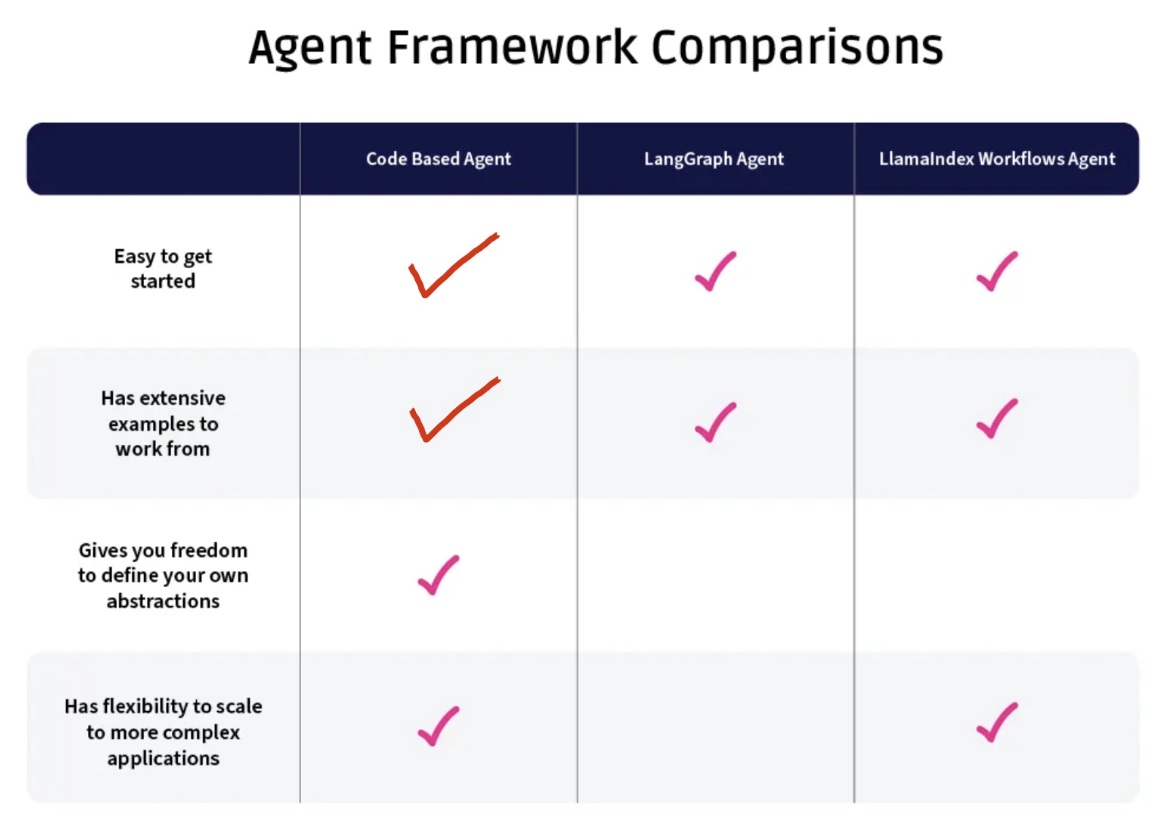
然後他最後有一張比較表,但我覺得自行開發才是 East to get started,你不需要先學框架的專有語法就可以開始。至於 Has extensive examples to work from 這項,我的學習方式是參考 LangGraph 的 examples 不用框架自己做一遍,難度不會比刷 leetcode 高啦。
📚 Anthropic 內部工程師談 Prompt engineering (影片)
這是 Anthropic 內部幾位工程師的一場訪談,談 Prompt engineering 提示工程。原錄影跟有人整理的逐字稿連結我放在留言中。 以下摘錄一些我比較有收穫的觀點(摘自逐字稿):
01 好的 prompt:足夠清晰、持續迭代
- 試圖讓提示詞過於抽象是一種使事情複雜化的方式,提示詞要寫得更深入。但更多時候,需要做的只是寫一個非常清晰的任務描述,而不是嘗試構建抽象的東西
- 一個好的寫作者不等於一個好的提示工程師,關鍵是要有迭代的意願和觀察的能力,為了寫出一個還算不錯的提示詞,可能會在短短 15 分鐘內發出數百個提示,反復調整
02 要把你知道 模型不知道的東西寫出來
- 你得把自己腦海中所有你知道但模型不知道的東西整理清楚,然後寫下來。我見過很多人寫的提示詞,可那些東西連我這樣一個人類都不明白,他們卻指望著模型能幫你解決問題……
- 很多人在看到模型出錯時,往往不會直接去問模型問題。他們只會告訴模型:「你做錯了。」但其實你可以問模型:「你知道為什麼出錯嗎?能幫我改改我的提示詞,讓你不再出錯嗎?」
03 越調越偏,不如直接放棄
- 有些任務確實很難,你的每一次調整可能都讓結果更加偏離目標。這種情況下,我傾向於放棄。與其花幾個月的時間在這個問題上,不如等下一個更好的模型出來
04 不需要角色扮演,和模型實話實說
- 隨著模型的能力越來越強,對世界的理解越來越深入,我覺得其實沒有必要對它們撒謊。更重要的是盡量具體地描述當前的場景
- 最擔心的是大家總是用角色扮演類的提示詞作為一種捷徑,讓模型完成某個類似的任務。而當模型沒有按照預期完成任務時,他們就會感到困惑。但其實那個預設的角色根本不是你想要模型完成的任務本身。你讓它去做了其他的事情。如果你沒有給它提供足夠詳細的信息,那麼你可能就漏掉了某些關鍵點。還是回到我們一開始說的,提示詞最重要的是表達清晰準確
- 很多人都沒有理解什麼是提示詞。很多人看到一個輸入框時,會把它當成一個谷歌搜索框,輸入幾個關鍵詞
05 模型有推理,但不是人類的推理
- 把模型的推理過度擬人化可能有點問題,甚至可能有害,因為它偏離了我們真正要做的事情,我們應該關注的是模型的表現
- 如果概念表達得清晰,語法和標點問題就沒那麼重要了
06 嘗試做一些難的任務,會有效提高 prompt 能力
- 多看別人寫的優秀提示,多和模型溝通、嘗試不同的提示詞
- 試讓模型做一些你認為自己做不到的事情。最能讓我學到提示技巧的,往往是在探索模型能力的極限時
07 信任模型的能力,不要把它當小孩子
- 我相信模型能夠處理更多的信息和背景,並將其融入到任務執行中
- 模型可以理解複雜的信息,不需要過度簡化。這是我隨著時間的推移逐漸學到的經驗
08 提示工程的未來
- 模型會越來越擅長理解你的意圖,你需要投入的思考量可能會減少。但信息論的角度來看,你總需要提供足夠的信息來明確指定你的要求。這就是提示工程的本質,我認為它會一直存在。而且能夠清晰地陳述目標始終很重要,因為即使模型在理解上下文方面變得更好,我們還是會需要能夠明確預期結果的能力,這仍然需要技巧
🌟 我對 Claude Computer Use 的看法和討論
Anthropic 最近推出 Computer Use 令人驚艷,讓大家對未來充滿樂觀期待。
Claude 的傳教士 Alex Albert 寫了一句 “Computer use is the everything API”,我認為這一句話解釋了這技術最重要的價值,任何沒有提供 API 的 GUI 軟體都因此可以被程式串接自動化。
但這句話我覺得也表示沒有更多突破: Anthropic 訓練了模型更加認識螢幕截圖跟 GUI 操作,可根據截圖跟你的指示,輸出操作鍵盤滑鼠的參數。應用層拿到此參數後去操作 GUI。至於模型是否足夠聰明能夠理解你的複雜任務,順利拆解步驟,那又是另一回事了,又回到模型本身的 zero-shot ReAct agent 任務規劃能力。就現況來說,prompt 還是要把步驟寫足夠清楚,才能讓執行結果比較順利。
不過即使如此,有些只能透過 GUI 操作的任務透過 Computer Use 變的可以自動化了,例如:
- 操作繪圖軟體例如 photoshop
- 影片編輯例如 final cut pro
- 遊戲操作例如玩 minecraft
- GUI 軟體安裝設定、測試
- 網路銀行操作
- 網路購物
- 線上訂票
- 相片整理
- 文件排版
- 操作手機,例如透過 iPhone Mirroring
- 操作多個 GUI 交互,例如從 A 得到資訊,輸入到 B 表單
- 等等歡迎大家發想補充
至於原先就有提供 API 可以程式串接的軟體,用 Computer Use 去串接只是又慢又貴又不可靠,不會比較好喔。
也推薦各位工程師可以把 API 文件中的參考實作 Demo app 跑起來玩一下,只要一行 Docker 指令跑起來很簡單的,可以立即打破你的一些幻想(?),到底有沒有這麼神,距離實用到底還有多遠。
補充說明: 這個 computer use 的 demo docker 跑起來是個 desktop linux (ubuntu 22.04),裡面有個 streamlit 來接收對話。這個 streamlit 收到 LLM 回覆的指示後,操作鍵盤滑鼠則是用 xdotool 這個工具,原理大概是這樣,是一個跑在linux desktop 上的 PoC 應用,還不是真正可以控制你的電腦的官方 app 版本。不過,馬上就有第三方做出可以真正控制你的電腦的版本啦,例如 agent.ext
🛠️ rerankers
rerankers 是個提供一致 Reranker 模型 API 的 Python 函式庫,作者寫了一篇文章說明了什麼是二階段檢索,以及比較不同 Reranker 模型。我之前也寫過一篇 使用繁體中文評測各家 Reranker 模型的重排能力。
📊 On Impactful AI Research
(這篇跟 AI 技術無關) 知名 Prompt 最佳化框架 DSPy 作者 Omar Khattab,史丹佛 NLP 博士候選人、Databricks 研究員,明年會去 MIT 當 EECS 助理教授,寫了一篇 總結了他如何透過開源 Open Source 專案讓研究產生影響力的文章。雖然我不是做研究的科學家,但這種研究模式看起來超棒的,很喜歡這種有開源專案的論文研究,有理論又有 code 可以實際跑來用。
以下是我快速的摘要:
- 投資於長期專案,而非單篇論文 不要將研究視為一系列獨立的論文,而應思考你想在 AI 領域中開創的新方向或解決的重大問題。你的研究願景應該遠大於單篇論文的範疇,是一個需要長期探索和持續改進的目標。例如,你可能致力於開發更有效的自然語言處理模型,這個目標可能需要多年的研究和多篇論文來逐步實現。
- 選擇及時、有擴散潛力的問題 並非每篇論文都值得無限投入;許多將是探索性的單次作品。要找到可以轉化為更大項目的方向,需要選擇具有潛力、能大規模擴散、有大幅提升空間的問題。
- 預想兩步並快速迭代 至少要思考兩步之後。識別大多數人在問題變得主流時可能採取的路徑,然後識別該路徑本身的限制,並開始著手理解和解決這些限制。
- 主動分享研究成果積極推廣 當你有了重要發現時,不要急於轉向下一個研究主題。相反,你應該積極地向學術界和業界分享你的研究成果。
- 透過開源專案擴大研究影響力 除了發表論文外,開發和維護開源軟體也是擴大研究影響力的有效方式。透過將你的研究成果轉化為實用的開源工具,你可以讓更多研究者和開發者受益,並在實際應用中檢驗你的理論。這不僅能提高你研究的影響力,還能收到寶貴的回饋,幫助你進一步改進研究。
- 持續投資專案,並發表新的論文 投入開源專案並不意味著要犧牲學術研究。相反,這兩者能夠相輔相成。透過持續開發和維護開源專案,你能更早發現新的研究問題,並在解決這些問題時擁有獨特優勢。
本期換了 E-mail 樣式,我把電子報系統換成自行架設的 listmonk 了,雖然功能不如 SaaS (我本來用 emailoctopus 這套),但基本也夠用了,就不用付月費啦。
– ihower