歡迎訂閱 📬 愛好 AI Engineer 電子報 過往期數點這 📚
想系統性學習 Context Engineering? 歡迎參考我的課程 👉 大語言模型 LLM 應用開發工作坊
Context Engineering 這個詞最近在 AI 技術圈被提出,包括 Tobi Lütke (Shopify CEO)、大神 Andrej Karpathy、Harrison Chase (LangChain 創辦人) 、Jerry Liu (Llamaindex 創辦人)、Simon Willison 等大大都在討論+1。過去大家熟知的是 Prompt Engineering,但現在發現這詞已經不夠涵蓋目前大家在做的事情,而且更多人誤認為這只是撰寫靜態的提示詞而已,而忽略了背後所需要的工程技術。技術社群需要一個新術語能更廣泛統稱所有 Context 的動態管理,包括 System/User prompt、RAG、Memory、Tool Calling、結構化輸出、Agent、Multi-Agents 等等。
什麼是 Context Engineering?
開發 AI 應用需要建構一個系統,動態根據當前任務和狀態,提供正確的資訊和工具給 LLM 大模型,讓它有足夠的條件完成任務,這就叫做 Context Engineering 上下文工程。
Tobi Lütke (Shopify CEO) 說:「我真的喜歡 context engineering 這個詞勝過 prompt engineering。它更好地描述了核心技能: 提供所有上下文讓 LLM 能合理解決任務的藝術。」
LangChain 在 “The rise of “context engineering” 文章中說:「Context engineering 是建構動態系統,以正確的格式提供正確的資訊和工具,使 LLM 能夠合理地完成任務。」
Andrej Karpathy 說: 「LLM 就像新型作業系統,模型是 CPU,而 Context window 就是 RAM。Context engineering 是精巧地把對的資訊在對的時機塞進 context window 的微妙藝術與科學。」
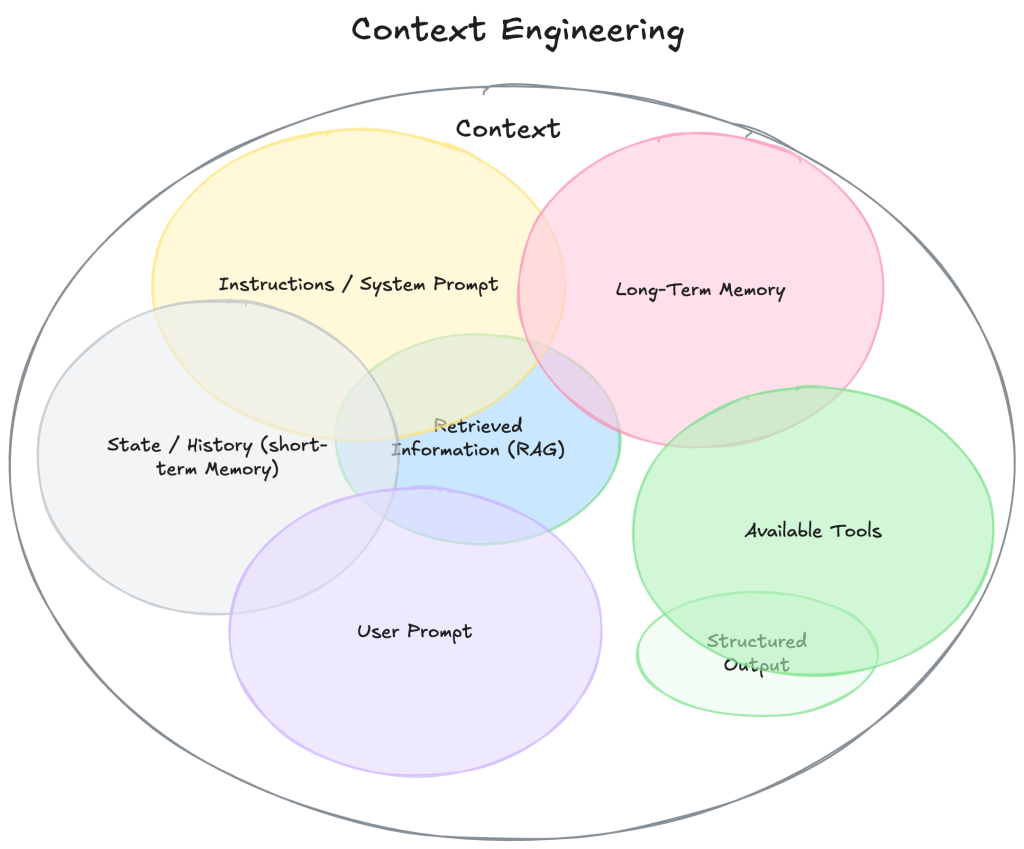
Context 包含什麼?
參考 Philipp Schmid 的 The New Skill in AI is Not Prompting, It’s Context Engineering 以及 Llamaindex 的 Context Engineering – What it is, and techniques to consider 兩篇文章,列舉 Context 不僅僅是你傳送給 LLM 的那段 prompt,而是模型在回應之前所看到的所有內容,這包括
- Instructions / System Prompt: 定義模型行為的初始指令和風格
- User Prompt / User Input: 使用者的請求、問題或輸入
- State / History: 當前對話的聊天歷史,包含所有使用者和模型的回應,這又叫做「短期記憶」
- Long-Term Memory: 跨對話的持久知識庫,包含學習到的使用者偏好、過去對話摘要、被告知要記住的事實,這又叫做「長期記憶」
- Retrieved Information (RAG): 外部的最新知識,從文件、資料庫或 API 檢索的相關資訊
- Available Tools: 所有可呼叫的函數或工具定義
- Responses from tools: 工具執行的結果
- Structured Output: 定義模型回應格式,例如 JSON 或 XML
- Global State / Workflow Context: 在多步驟驟 Agent 或 Workflow 中,暫存全域變數、任務進度、先前結果等等。
上述組合構成了目前幾乎所有 AI 應用中會出現的 context 內容。
Context Engineering 的四種方法
Lance Martin (LangChain 核心開發者) 寫了一篇 Context Engineering for Agents 文章,將上下文工程會用到的方法歸納為四類,我簡單總結和補充如下:
1. 寫入 Context:
動態將資訊保存在 context window 之外,例如跨對話記憶用戶偏好,形成長期記憶(Memory)的效果。ChatGPT 就很喜歡做長期記憶的功能,更多 Agent Memory 資料可以參考我的筆記。
2. 選擇 Context
將相關內容拉進 context window,這包括從 Memory 拉出需要的回憶、根據當下任務動態挑選工具、透過 RAG 檢索拿到的相關資料 。更多 RAG 資料可以參考我的筆記。
3. 壓縮 Context
由於模型有 context window 限制,在超過某個閥值時,我們只保留執行任務所需的 tokens。例如 Claude Code 在超過 95% context window 時執行會 auto-compact,將目前狀態總結存下來,再重新開始。或是其他修剪方式。
4. 隔離 context
將 context 拆分以協助任務執行,通常出現在 Multi-Agents 的實作,例如 OpenAI Agnets SDK 的 Agents as Tools,Anthropic 的 Multi-Agent Research 等等,都是把任務拆分到另一個 Sub Agent 去執行,執行完成回來就只會有結果,如此可以大幅節省 Lead Agent 的 context 用量。
不過隔離 context 會有無法有效共享資訊的問題,詳見 Multi-Agent 或 Single-Agent 架構討論 一文。
自訂格式
最早提出 Context Engineering 詞彙的,可能是 12-factor-agents 的 Own your context window 這篇內容。作者 Dex 這樣說:在任何時刻,你對代理人中的 LLM 的輸入都是「這是目前為止發生的事情,下一步是什麼」。一切都是上下文工程。LLM 是無狀態函數,將輸入轉換為輸出。要獲得最佳輸出,你需要給它們最佳的輸入。
Dex 甚至提出,不一定需要照模型廠商設計好的 message-based 格式,你可以建立專為你的使用情境最佳化的 context 格式,例如把 context 用 XML 格式都塞到單一 user prompt 裡面。這樣的好處是獲得最大的資訊密度:相同訊息,使用更少 Tokens。
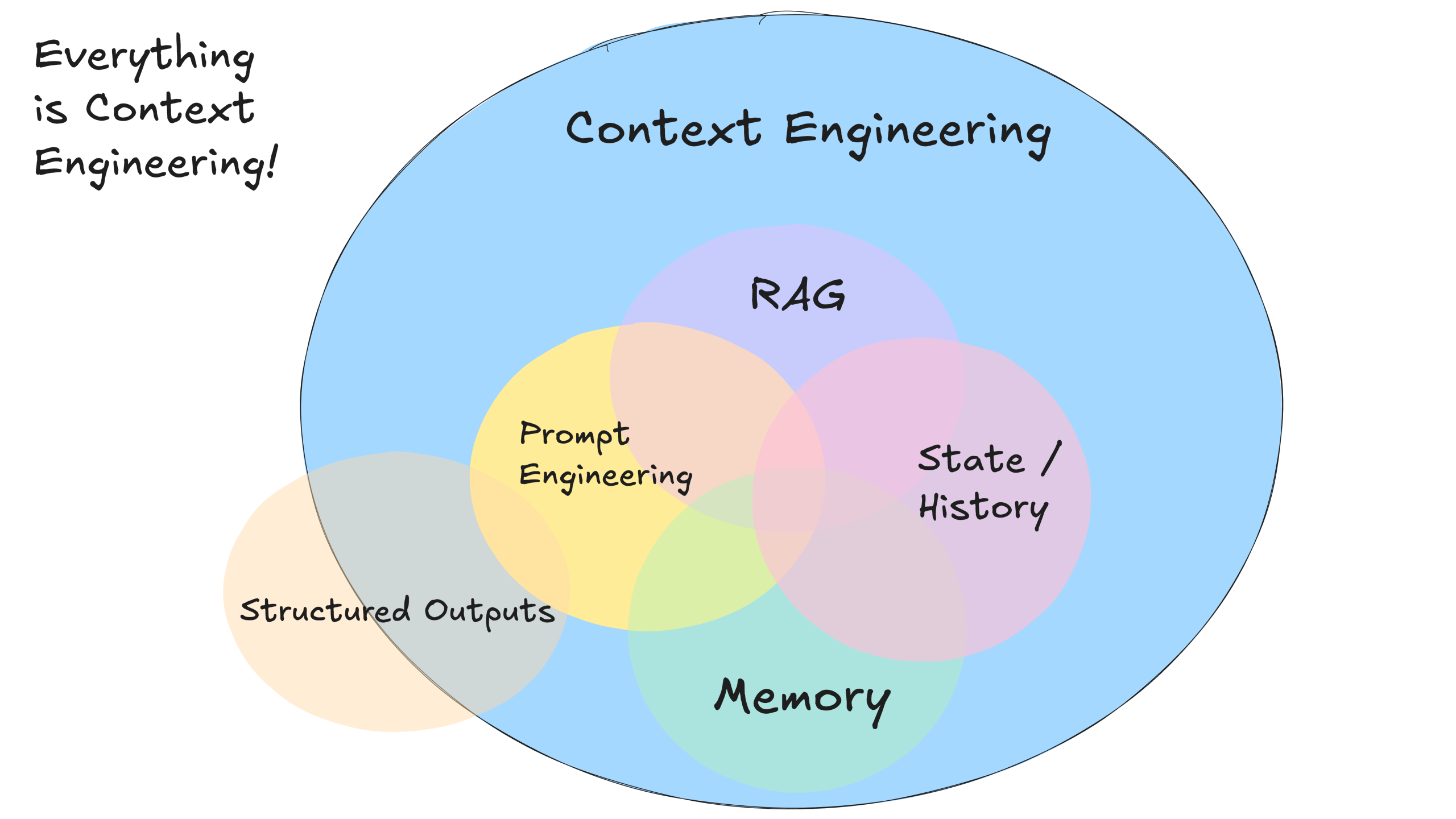
這是 Dex 的 Context Engineering 圖示版本,注意到文章最上面來自 Philipp Schmid 的圖示相比,少了 Tools。這是因為 Dex 認為 Tools are just structured outputs,工具沒什麼特別,只要 LLM 輸出 JSON,就能交給確定性程式碼執行。因此他沒有用模型廠商提供的 function calling 格式,而是用自訂的格式來做工具呼叫。
我感覺 Dex 的 12-Factor Agents – Principles for building reliable LLM applications 就像是 Agent 開發的第一性原理,沒有採用任何 LLM 開發框架,給了我很多啟發,非常值得一看。
為何 Context Engineering 重要?
LLM 就像一位被關在房間裡的天才,無法主動學習或操作世界,也沒辦法存取即時資訊或使用電腦。大模型的「原始智力」不等於「智慧軟體系統」。大模型 LLM 的「智力」只是基石,要把它轉化成真正有效的智慧系統,還需要兩個關鍵:
- 🔧 工具整合: 讓模型能實際操作、查資料、記憶與回應
- 📦 正確的上下文(context): 依照任務動態提供模型需要知道的資訊
上下文管理是打造強大 Agent 時,我們 AI 工程師最需要投入心力的地方。Context 並非免費,每個 token 都是成本,也都會影響模型行為。
這就是 Context Engineering: 動態處理「LLM 在當前任務中所需要的所有資訊和工具」。建立強大可靠的 AI 系統越來越不是找到某個神奇的 prompt 或換更厲害的模型,而在於在正確的時間,提供正確的 context 和工具。