
Hello! 各位 AI 開發者大家好 👋
我是 ihower,這期不小心變成月刊了,暑假真是過太快了。
幫分享今年的 PyCon Taiwan 在臺北文創,總共有 3 種形式的演講與 6 種不同性質的交流活動。
時間是 2025/9/5 – 9/7 👉 活動資訊與購票
🚀 OpenAI GPT-5 API 更新重點整理
OpenAI 於 2025/8/7 推出 GPT-5 啦,包括 ChatGPT 和 API 都同時上線了。這篇是我針對 AI 開發者快速解惑與整理重點。
🤖 Agent 讓 RAG 過時了嗎? 談 AI Coding 的檢索策略
看了一場 Augment Code (也是一家做 AI IDE 的廠商) 來講 “Agentic 檢索” 對比 “傳統 RAG 檢索” 的演講,蠻有啟發的。
在 AI Coding 領域,簡單的工具正在擊敗複雜的 RAG 系統。這篇是我的解讀整理。
📊 如何管理 AI 專案? AI PM 從確定性工程到應用研究
最近看了幾篇討論 AI 產品經理和 AI 專案管理的內容,最有感的是這句話:「傳統軟體開發是確定性的,但 AI 開發本質上是應用研究」,這根本性的差異改變了一切。
這篇是我的解讀整理。
🧩 從 Prompting 基本結構到 Agent Prompting 設計原則
Anthropic 最近才釋出了他們在 2025/5/22 開發者大會的完整影片,當時的重頭戲是 Claude 4 模型發布。其中有兩場關於 prompting 教學的演講內容很不錯,這兩場演講從基礎 Prompt 到針對的 Agent 的 prompting ,展現了 prompt engineering 的不同層次,推薦大家一看。這篇是我的解讀整理。
🏗️ Shopify 的內部工程經驗
在 Anthropic 開發者活動的錄影中,還有好幾場是客戶公司來展示他們用 Claude 做的產品,包括:
- Canva: 推出 Canva Code,讓非技術用戶也能建立互動式網頁原型
- Databricks: 整合 Claude 到他們的資料平台,用於處理企業級 AI 應用的治理和評估問題
- Manus AI: 建立通用 AI Agent,可以在雲端虛擬機器中執行長時間任務(如找辦公室、規劃行程)
- Shopify: 下述
- Tempo Labs: 打造「給 PM 和設計師用的 Cursor」,讓非工程師也能協作寫程式碼
- Zencoder: 推出 ZAN agents,支援 MCP 的自訂 Agent,可部署在整個軟體開發生命週期
- Gamma: 用 Claude 生成簡報和文件
- Biddo: AI 程式碼審查平台
- Refusion: 音樂生成平台,用 Claude 的 Ghost Writer 幫助創作歌詞
- Create: AI Text-to-App 建構器,讓任何人都能用自然語言建立行動應用程式
- Stanford 學生用 Claude 建立核武偵測模擬系統
- UC Berkeley 學生 7 個月從零學會寫程式,建立多個實用工具
但最讓我感興趣的是 Shopify 首席工程師 Obie Fernandez 的分享,這場我認為比較特別是在講內部工程工具,不是講產品。
Shopify 是全球最大的 Ruby on Rails 應用,開發近 20 年,有數百萬行程式碼。在這種規模下,他們怎麼善用 AI 提升開發效率?
他們的關鍵洞察是: 確定性 vs 非確定性工作流程的結合,他認為 AI 工具有兩種截然不同的使用方式:
- Agentic 工具 (如 Claude Code): 適合探索性、模糊的任務,需要適應性決策和迭代
- 結構化工作流程: 適合有明確步驟、需要一致性和可重複性的任務
他們發現,像花生醬配巧克力一樣,可以將這兩種方式結合起來。他們除了大量使用 Claude Code,同時也開發了 Roast 一套用 Ruby 寫的結構化 AI 工作流程框架。
實際應用案例:
- 自動化測試生成和優化
- 程式碼遷移
- 類型檢查改進
最巧妙的是可以雙向整合:
- 可以在 Claude Code 中呼叫 Roast 工作流程
- 也可以在 Roast 工作流程中呼叫 Claude Code SDK
實務好處:
- 可以快取 function 呼叫結果,不用每次重跑
- 可以從特定步驟重新開始,不用從頭跑
- 5-6 週內在內部環境推出後,已經在公司內部 “像野火般蔓延”
Obie 說: 無論最先進的模型在遵循指令方面變得多麼優秀,它們本質上仍然是非確定性的。這種混合方法讓 Shopify 能在保持靈活性的同時,確保大規模工程組織需要的可預測性和可重複性。
Ruby 程式語言是我的老本行,我進一步研究了這個 Roast 專案,他的核心原理是在建構一個連續對話流程,這個 workflow 採用 yaml 格式定義,例如:
name: analyze_tests
model: gpt-4o-mini
tools:
- Roast::Tools::ReadFile
- Roast::Tools::Grep
steps:
- read_test_file
- analyze_coverage
- generate_report每個步驟都可以定義自己的 prompt,後續步驟能參考前面對話的所有上下文。這種設計讓工作流程既結構化又保持彈性。
這套跟一般教的固定式 prompt chaining 流程不太一樣的地方在於
- 這有賦予工具使用,因此一個step實際上是一輪agent內部執行
- 採用模型 API 原生的對話串格式來維持 context
個人覺得算是蠻特別的設計,有點像是固定交接流程的 multi-agent 工作流程。
🌐 近期 MCP 演講整理和趨勢
看了 MCP Developer Summit 和 AI Engineer World’s Fair 中關於 MCP 的 50+ 場演講(當然只是看逐字稿 AI 摘要啦,不然看錄影會有20+小時),整理出 MCP 生態系的幾個重要發展趨勢:
- MCP 協定持續進化
- 企業級導入案例
- MCP Gateway 有超高需求
- 工具太多成為核心挑戰
- 從工具思維到 Agent 思維
- 標準化之爭
以下分別展開:
1. MCP 協定持續進化
MCP 新推出兩個重要新功能:
- Elicitation: 讓 MCP server 可以向 MCP client 請求用戶的額外資訊
- Tool Structured Output: 可以定義工具的結構化輸出格式
相關演講:
- MCP Project Update with Jerome Swannack, Member of Technical Staff at Anthropic
- MCP Registry: Designing For Server Discovery Tadas A. (PulseMCP) Alex H.(Block), and Toby P.(GitHub) 這場討論官方 MCP Registry 的發展情況
除了新功能,也有一些早就存在但被忽視的規格受到關注。例如 Sampling 功能(我在五月的 MCP talk 有講到,可讓 MCP server 使用 MCP client 的 LLM)
相關演講:
- MCP201: The Protocol in Depth with David Soria Parra at Anthropic
- Resources: Building the Next Wave of MCP Apps with Shaun Smith, LLMindset
2. 企業級導入案例
- Block 的全公司導入: 分享全公司導入 MCP 的經驗,最有趣的發現是「非技術人員比工程師更有創意!」甚至有非工程師自己 vibe code 了一個 MCP server (連 GitHub 帳號都沒有)。
- Bloomberg 的大規模採用: 展示如何用 MCP 連接內部各種系統,讓 AI 能夠安全存取企業資料。他們特別強調資料安全和合規性的重要。
相關演講:
- From Experiment to Enterprise: How Block Operationalized MCP at Scale – Angie Jones, Block
- Pragmatic Scaling of Enterprise GenAI with MCP with Sambhav Kothari at Bloomberg
3. MCP Gateway 有超高需求
企業一旦開始導入 MCP,馬上就會發現需要 Gateway 來解決各種問題,如何管理內部眾多 MCP server 和工具,特別是安全與授權挑戰。因此希望能有單一的 MCP server 作為 Gateway 角色,統一入口管理。
- WorkOS 分享從 localhost 到企業級的血淚史。身份驗證只是第一步,更難的是「AI workload 之間的授權傳遞」。還有各家推出 Gateway 方案百花齊放:
- UCL 把 MCP 包成企業級 Gateway
- Pomerium 用零信任架構包裝所有服務
- A16Z 提出 Service Proxy 概念
- Smithery、Fastn、Natoma 都推出託管方案
- MCP Defender 的安全方案: 使用 Proxy 攔截所有流量,用 LLM 來保護 LLM
- ScaleKit 提出 Auth 託管方案
- Anthropic 工程師也分享了他們內部 MCP gateway 的經驗
相關演講:
- What MCP Middleware Could Look Like with Yoko Li from A16Z
- Fastn UCL: Secure & Scalable MCP for Enterprise AI Deployments | Khalid Muaydh, Fastn
- Agentic Access: OAuth Isn’t Enough | Zero Trust for AI Agents w/ Nick Taylor (Pomerium + MCP)
- Tool Calls Are the New Clicks: Henry Mao on Building Smarter AI Agents with MCP
- Enterprise-Ready MCP: Hosted Solutions for Scale, Security & Real-World Use | Paresh Bhaya, Natoma
- How to Add OAuth to MCP Servers in 4 Steps — Ravi Madabhushi, Scalekit
- Securing AI Apps with MCP Defender — Sundeep Gottipati
- What does Enterprise Ready MCP mean? — Tobin South, WorkOS
- Remote MCPs: What we learned from shipping — John Welsh, Anthropic
非常多公司都在做 Gateway 這個題目,顯示這是真實且迫切的需求。
4. 工具太多成為核心挑戰
當你有幾百甚至幾千個工具時,AI 會選擇困難。各家提出不同解法:
- VS Code 的工具管理策略: 動態使用者在每個對話中有不同工具子集,還能自訂工具組合(toolsets)
- Block 的洋蔥式架構: 把工具分成三層 – 發現層、規劃層、執行層。先用一個工具來探索有哪些 API 可用,再用另一個工具取得詳細參數,最後才執行。有點像是「先問有什麼菜 → 再問怎麼做 → 最後才點菜」的概念。
- Appify 的動態載入: 他們有 4000+ 個工具!解法是用 MCP 的 toolListChanged 通知機制,根據使用者需求動態載入工具。比如說使用者想爬 LinkedIn,系統才去找相關的爬蟲工具加進來。
- 向量搜尋方案: 把所有工具描述先做成 embeddings,當使用者輸入 prompt 時,用相似度搜尋找出最相關的工具,再用 reranker 排序。這樣就不用一次載入所有工具。
相關演講:
- Too Many Tools? How LLMs Struggle at Scale | MCP Talk w/ Matthew Lenhard
- Full Spec MCP: Hidden Capabilities of the MCP spec — Harald Kirschner, Microsoft / VSCode
5. 從工具思維到 Agent 思維
這是重要的開發典範轉移: 不要只是把 API 端點一對一變成 MCP工具!你會有三個用戶: 終端用戶、client app 開發者,還有 AI 本身。要思考使用者會問什麼問題,然後設計適合的工具介面。
MCP-first 開發: 與其先做 REST API 再包裝成 MCP,不如一開始就為 AI 設計。當 AI 成為主要使用者時,系統設計的思維要完全改變。
相關演講:
- Scaling Enterprise MCP: Best Practices, Nexuses, and Security with Pat White
- MCP Is Not Good Yet — David Cramer, Sentry
6. 標準化之爭
LlamaIndex 的 Laurie Voss 比較了 14 個 Agent 通訊協議。Google 的 A2A (Agent-to-Agent) 已經加入 Linux Foundation,確保技術中立性。
關鍵問題: 「呼叫工具」和「呼叫 Agent」到底有什麼差別?A2A 說差別在於 Agent 可能需要很長時間回應(甚至幾天),所以內建了非同步機制。但講者認為這差異並不大,而且 MCP 也即將支援非同步。
編按: 你可以將 Agent 包在 Tool 裡面,呼叫工具就是傳訊息給裡面的 Agent。我在我之前的 MCP talk 就有提到這招。
現實很殘酷: 這 14 個協議大多「半生不熟」,真正有採用率的只有 MCP。為什麼?因為 MCP 選擇先解決一個小而具體的問題,證明了自己的價值。就像 React 當年征服前端世界一樣。結論是犀利的: 「MCP is all we need」。
相關演講:
- MCP vs ACP vs A2A: Comparing Agent Protocols with Laurie Voss from LlamaIndex
- A2A & MCP Workshop: Automating Business Processes with LLMs — Damien Murphy, Bench
🛠️ Block’s Playbook for Designing MCP Servers
這篇文章是 MCP server 的開發經驗談,關鍵洞察是: 別從 API 端點開始設計,而是從工作流程來設計
傳統 API 設計是 bottom-up,但給 LLM 用的工具應該 top-down,從「用戶想完成什麼任務」倒推回去設計。
舉個例子,他們的 Google Calendar MCP 第一版就犯了經典錯誤:
一開始直接包裝 API,例如 list_calendars(), list_events(), get_timezone()。結果問「我今天行程如何?」需要串接一堆 tool calls 才能回答。
改版後直接提供 query_database() 讓 AI 跑 SQL,一次搞定複雜查詢。要找三個人的共同空檔? 一行 SQL 就解決:
sql SELECT * FROM free_slots(['[email protected]','[email protected]','[email protected]'], ...)他們還發現幾個關鍵 Best Practices:
- 善用 LLM 優勢: SQL 查詢、Markdown 圖表是強項,但別讓它規劃太多步驟或輸出複雜 JSON
- 工具名稱很重要: 因為 tool name 和 description 本身就是 prompt,要寫得清楚明確
- 權限管理要簡單: 每個工具最好只有一種風險等級(唯讀 vs 寫入),別混在一起讓用戶困惑
- Prompt 要快取友善: 避免在指令中放動態資料(如當前時間戳),會讓快取失效
最後他們 Linear MCP 的演進,從 30+ 個小工具最後精簡到 2 個: execute_readonly_query 和 execute_mutation_query,直接讓 AI 寫 GraphQL。
📉 RAG Anti-Patterns in the Wild
看了 Skylar Payne 這場 “RAG Anti-Patterns in the Wild” 演講,內容蠻豐富的。他從五個實際客戶案例中整理出 RAG 系統常見的坑。這些案例涵蓋了不同領域的 RAG 應用,包括客戶支援知識庫、醫療建議聊天機器人、金融新聞摘要、學術研究助手、電商產品比較。
總共 17 個 Anti-Patterns,根據 RAG 流程的六個階段區分:
📁 資料收集與策劃 (Data Collection & Curation)
- 文件編碼格式錯誤處理不當: 例如假設所有文件都是 UTF-8,遇到 Latin-1 就直接丟掉
- 包含無關文件集: 索引包含與查詢無關的文件,像是金融新聞索引包含總體經濟文章
✂️ 擷取與內容強化 (Extraction & Enrichment)
- 資訊擷取不正確: PDF 表格擷取失敗,例如 LaTeX 生成的多欄文件
- Chunking 太小: 把文件切成太小片段,失去上下文造成幻覺,例如 電商產品規格表切成 200 字元
- 保留垃圾 Chunks: 例如頁首頁尾有一堆獨立重複的 chunk,佔用檢索空間
🗂️ 索引與儲存 (Indexing & Storage)
- 天真使用 Embedding: 沒考慮問答語義差異,問題形式與文件形式不同
- 沒檢查索引過期: 索引沒定期更新,提供過時資訊,例如財經新聞索引兩週沒更新
🔍 檢索 (Retrieval)
- 接受模糊查詢: 例如接受「健康建議」這種太廣泛的查詢,檢索結果雜亂無章
- 接受離題查詢: 沒有過濾無關查詢,如電商網站回答「寫一首獨角獸的詩」,造成奇怪的生成結果
- 所有用戶詢問都用RAG處理: 讓所有用戶查詢都去走完整 RAG 流程,例如「我的帳單日期」可用查詢結構化資料庫解決。解法是需要做意圖分類,找出常見用戶查詢改用一般資料庫查詢甚至用快取,而非進到 RAG 流程
- 沒有評估假陰性: 只評估檢索到的文件,不看漏掉的相關文件
- 沒有評估檢索充分性: 只標記相關性,不標記是否足夠回答問題。答案是否正確、檢索是否充分,有四種象限可以分析和處理
📊 重新排序 (Reranking)
- 過度使用 Boosting: 加太多人工 boost 分數提升規則,系統變脆弱,例如 10 個 boost 規則讓無關文件排名超前
- 允許離譜結果 (Face-Palm Results): 不過濾明顯錯誤的結果,例如查帳單地址變更,第一名是服務條款
- 不做評估就增加複雜度: 例如加入多個檢索路徑卻沒有評估效果,造成延遲從 4 秒增到 11 秒,品質反而變差
🤖 生成 (Generation)
- 簡單 RAG 是無法處理推理查詢的: 只做單次檢索無法連結多個概念,碰到多步推理的問題會失敗
- 沒有輸出防護措施防止幻覺,不要求引用來源,無法驗證生成內容,案例是 醫療聊天機器人憑空生成藥物副作用
以上每個 anti-pattern 都有具體的建議,蠻實用的。
作者還有個 The RAG Checklist 可以訂閱,會拿到一份 checklist PDF (就是演講內容的摘要)。
📑 Startups to F500: Document Automation Lessons at Scale
在一場關於大規模文件自動化處理的演講 Startups to F500: Document Automation Lessons at Scale,讓我看到跟 91APP 在 今年生成式 AI 年會一樣的「正確率 vs. 覆蓋率」概念。
Extend 團隊分享了一個血淋淋的教訓: 他們的客戶一開始就想要一次性自動化整個 SaaS 合約處理流程。結果呢?差點整個專案都要放棄,拿到 AI 工具就想馬上自動化一切,把文件丟給 ChatGPT,看起來擷取得很完美,就以為可以直接取代整個人工流程。
現實是殘酷的,在牙科帳單自動對帳案例中,他們提出一個關鍵的務實方法:與其追求 98% 準確率但不知道那 2% 錯在哪,不如達到 85% 的「真實自動化率(true automation rate)」- 也就是系統能 100% 確定哪些可以自動處理,哪些需要人工介入。
而在 91APP 的案例,他們在做商品資料自動填充時,面臨同樣的選擇:
- A 方式: 每個商品都有答案,但正確率只有 70%
- B 方式: 只有 50% 的商品有答案,但正確率 90% 以上。另外 30% 的商品只有部分答案。
你猜他們選哪個? 答案是 B 方式。為什麼?因為 A 方式那種情況最痛苦。使用者不知道哪些是錯的,只能全部重新檢查。這正是 Extend 說的:「在關鍵業務文件處理中(如合約、醫療記錄、財務文件),錯誤的代價極高。重點不是達到最高的處理覆蓋率,而是要能「明確驗證」(declaratively validate)哪些處理是正確的。只要能做到這點,即使只能自動化部分流程,也能安全地部署到生產環境」
那要怎麼做?
- 第一步:建立人工流程 (Human-in-the-Loop),先收集真實數據。Extend 的客戶改變策略後,即使 AI 處理了文件,還是有交給人工審核,藉此了解真實的生產數據。
- 第二步:建立文件特徵分類系統,理解數據模式。他們在 20 萬份文件上跑批次處理,不是為了擷取數據,而是為了理解「哪些供應商的文件有問題」「哪些版面配置會出錯」。
- 第三步:針對不同情況設計不同處理方式。例如 91APP 的方式: 高信心正確率的情況,完整填入答案讓人類簡單審核即可。沒信心的不要填答案,讓人類補齊答案。
總之,「盡可能自動化,否則就增強」。不是要 AI 完全取代人類,而是建立一個誠實、可信賴的人機協作系統。當 AI 說「我確定」的時候,你可以相信它;當 AI 說「我不確定」的時候,你知道要自己判斷。
別想著一次到位,先從能做好的部分開始,逐步擴大自動化範圍。真實自動化率比虛高的準確率更有價值。
🧭 模型是否就是你的產品?
看了兩場演講談「Is the Model The Product?」模型是否就是你的產品。討論 AI 產業的一個核心問題: 到底一個 AI 產品真正的價值在於模型還是產品體驗。
以下整理這兩場觀點跟心得。
觀點一: 模型即產品 The Model is the Product
Han 的觀點是模型的核心智慧才是唯一重要的,產品的核心價值來自基礎模型。
洞察有:
- 模型的突破性能力會創造全新產品類別,例如 GPT-3.5 誕生 ChatGPT、Claude Sonnet 3.5 誕生 AI Coding,每次模型能力的躍進,都會開啟一個新的產品賽道。
- 模型會吸收周邊的複雜度,例如以前做 NLP 要手動處理語法解析、語意理解、實體辨識… 現在 Transformer 把整個 stack 都吃掉了。系統的複雜性和結構變得不那麼重要,所有的智慧都將聚合到模型中。
每次模型能力的躍升,都會讓一批創業公司哭喊「OpenAI 殺死了某某新創」。如果你的價值建立在當前模型的不足之處,下一個模型版本可能就會讓你的護城河消失。
兩種生存策略: Model-First vs Product-First
Model-First: 例如 DeepSeek CEO 說:「我們相信當前階段是技術創新的爆發,而不是應用的爆發。」主要實驗室都追求最先進的模型,朝著 AGI 競賽,無論那是如何定義的。但這並不容易。即使對於像 Elon Musk 這樣的人,也花了將近兩年時間和三個模型發布,Grok 才能接近領先優勢,才能有競爭力。當模型驅動價值時,模型優先給你最強的牌。但對大多數公司來說,這非常昂貴、有風險,並不總是可行的。
Product-First: 產品優先戰略的本質。你如何設計、整合,以及如何分發和提供以用戶為先的體驗。但是核心挑戰是,許多產品優先公司,你依賴於市場上的模型優先實驗室來提供這些新能力。你無法控制底層的突破。你必須等待它。當這些能力被吸收到下一個模型發布中時,你的差異化可能會消失。那麼護城河在哪裡?
講者認為 AI 產品的生存關鍵是「distribution 分發」即護城河。
有句話說,第一次創業者著迷於產品,第二次創業者著迷於分發。在 AI 應用的世界中,分發給你數據、用戶行為數據、產品反饋數據,以及一些真實世界的信號,讓你知道什麼有效,什麼無效。你可以使用分發來建立自己的數據,建立自己的評估框架,建立自己的基準測試。所以當新的模型能力出現時,你將是第一個進入市場的。或者如果你願意,你可以使用你的數據來自己創造新興能力。
觀點二: 產品品味(Product Sense)才是護城河 The Model is Not the Product
Hamel Husain 講者的反駁是: 如果模型是一切,為什麼擁有最強模型的公司做不出好產品?
他認為你的品味和產品感才是護城河,不是模型。
很多人說基礎模型實驗室(OpenAI、Google 等)會往上游走,自己做產品,把所有價值都吃掉。但這不就是老掉牙的「為什麼 Amazon 不會自己做?」翻版嗎?把 Amazon 換成 OpenAI,道理是一樣的。Google 有最先進的 LLM、自己的硬體、50 億用戶,按理說應該橫掃 AI 產品市場吧?但是:
- Google Docs 不能處理評論、不能顯示差異
- Calendar 不能存取聯絡人
- Gmail 常常回答「我無法協助」
相比之下,第三方產品 Lindy 反而能輕鬆幫你從聯絡人找到 Brian 並安排會議。
AI 工程其實包含兩件事:
- 讓模型做你想做的事,用到 prompt engineering、RAG、框架等
- 搞清楚你到底想要什麼,這需要品味、判斷力、設計、UX,設計良好的使用者介面
就算未來第一件事變簡單了,第二件事永遠逃不掉。GitHub Copilot 和 Cursor 在很長一段時間內都可以存取相同的模型。也許現在不是,但在很長一段時間內都可以存取相同的模型。我會說非常、非常不同的產品,具有非常不同的能力和來自用戶的非常不同的反應。我會說不是模型的部分正在做大量的工作。產品體驗天差地遠,這不是模型的功勞。
💡 結論看法
模型能力是必要條件但非充分條件。就像 Switch 不是用最先進的晶片堆出來的,而是任天堂把現成組件整合成令人愉悅的體驗。
我們都同意分發(distribution)是一種護城河,用戶數據讓你比模型公司更有優勢,請建立自己的評估架構。
模型會越來越聰明,但「弄清楚用戶要什麼」這件事,還是需要人類的品味和洞察力。
⚖️ 驗證的不對稱性
剛被挖角去 Meta 超級智慧實驗室的前 OpenAI 研究員 Jason Wei,也是著名 Chain-of-Thought 論文的第一作者,最近寫了幾篇短文,講到的概念蠻不錯的,紀錄一下。
1. 驗證的不對稱性(Asymmetry of verification) 1
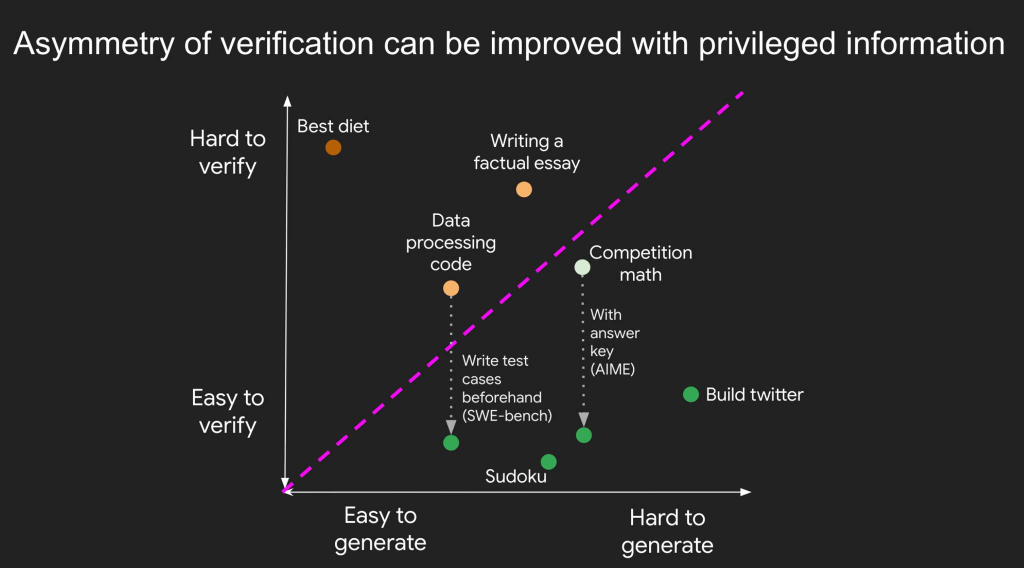
有些任務「解決很難,驗證很簡單」,例如數獨要花很久解,但檢查答案對不對只要幾秒。
但也有些任務「驗證比解決還難」,比如事實查核有個 Brandolini 定律: 「駁斥錯誤資訊所需的努力比製造它多出一個數量級」。許多科學假說也是如此,提出一個新飲食法很簡單,但要驗證是否真的有益健康,可能要花好幾年追蹤研究。
這裡 Jason 提出「驗證者定律」(Verifier’s Law): AI 訓練的難易度,與任務的可驗證性成正比。所有可能解決且能驗證的任務,最終都會被 AI 解決。
一個重要洞察是: 我們可以主動改善驗證的不對稱性。以程式設計為例,雖然閱讀程式碼並檢查正確性很繁瑣,但如果有涵蓋充分的測試案例,就能快速檢查任何解答。
為什麼這個很重要?因為能夠驗證,就能建立強化學習(RL)訓練環境,讓 AI 不斷嘗試、獲得回饋、持續改進。未來我們很可能會有個參差不齊的智慧邊緣: AI 在可驗證任務上會更聰明,因為解決可驗證任務要容易得多。
2. 描述-執行落差(description-execution gap”) 2
描述任務的難度與實際執行該任務的難度相比,哪一個更高?如果描述任務比實際執行簡單很多,這類任務就很適合 AI 自動化。
例如「修正文章中的語法錯誤」,描述起來簡單,但實際要人工檢查整篇文章很費時。
反之,像「以特定風格剪輯影片」,通常自己剪比描述每個細節該怎麼做還容易,或是「幫媽媽買雜貨」,她有非常特定的品項和數量,自己去買比跟我描述要買什麼、要怎麼挑水果還簡單。
這解釋了為什麼某些看似簡單的任務 AI 還做不好: 不是技術問題,而是描述成本太高,人會懶得跟 AI 講清楚。因此當描述任務的成本接近或超過執行成本時,人類自己做反而更有效率。
3. 從 RL 強化學習學到的人生哲學: 走自己的路 3
強化學習的重要概念是始終保持「on-policy」: 與其模仿他人的成功軌跡,不如採取自己的行動,並從環境給予的獎勵中學習。
模仿學習只適合初期啟動,就像在學校學習基礎知識。但真正要超越老師,必須做 on-policy RL: 根據自己的強項和弱點,從環境中獲得真實回饋來學習。
他舉了個人例子: 別人可能擅長快速嘗試,但他發現自己更擅長「深入閱讀資料」和「做細緻的實驗」。這些看似「慢」的方法,反而成為他的獨特優勢。
與其模仿別人的成功路徑,不如發揮自己的獨特優勢。就像 RL agent 最終要找到自己的策略,而不是永遠模仿人類的解法。
補充有人指正: 易驗證不等於 AI 一定能訓練得出解,原文中這個 Verifier’s law 還有一些但書。例如質因數分解還是很難,驗證卻很簡單。所以這更像是工程經驗法則: 要驗證快且能密集回饋有效訊號,RL 迭代才會有效。
💻 Claude Code 課程推薦
Claude Code 是目前最火紅的 AI Coding 工具,也是我最近的主力開發工具,可輔以 Cursor 使用。這裡推薦兩個 Anthropic 官方推出的課程:
- Anthropic Academy 的 Claude Code in Action 錄製非常精美的線上課程
- DeepLearning.AI 的 Claude Code: A Highly Agentic Coding Assistant 用了三個案例(RAG Chatbot、Jupyter notebook、Visual mockup) 實際示範開發過程,非常推薦
更多關於 Claude Code 的資源整理,可以參考我的筆記。
希望你會喜歡這集內容!
– ihower