
為什麼選這台?
能在本地自家跑 LLM 大模型,應該是 AI 工程師的夢想之一。
太小的模型不夠實用,因此一直有在關心能跑的動 70B 的機器。在 2025 年中研究了一下個人用的 AI 工作站電腦,在「128 GB RAM + 2TB SSD」的條件下來選,最後得出三個選項:
- 性價比冠軍: AMD Ryzen AI Max+395: 價格才 USD 2k (2026漲價到3k了); 記憶體頻寬 273 GB/s; x86 + Windows; 70B 模型推論 + 玩遊戲都 OK
- 生態優勢: NVIDIA DGX Spark: 要 USD 4k;(2026漲價到6k了) 記憶體頻寬也是只有 273 GB/s; ARM + CUDA,適合模型訓練/微調,若只跑推論感覺 C/P 值不如 AMD 啊
- 頻寬極速: Mac Studio M4 Max (2026 128g 缺貨中): 最貴 USD 4.5k; 546 GB/s 跑推論最快; macOS 生態
本地要跑 LLM,關鍵就是 GPU RAM 要夠,而且記憶體頻寬速度要夠快。
Mac Studio 是很多人推薦的選擇,但是我覺得組 128GB + 2T 硬碟的話,價格太貴了(六位數台幣約14W)。而且我已經有一台 MacBook Pro 了。
另一個選擇是 2025 年初發表的 NVIDIA DGX Spark,我對這台也很感興趣,後來發現這台有幾個問題:
- 這台是 ARM 機器是跑 Linux,定位就是機器學習工作站,拿來在 Nvidia CUDA 體系下做機器學習訓練
- 記憶體頻寬只有 273GB/s,跑推論應該會比 Mac Studio 慢,沒優勢
- 價格也不便宜,要台幣6位數,而且其實網上你還買不到
我自己的需求主要是模型 Inference 推論,買 NVIDIA DGX Spark 這台感覺有點浪費,又不是主力在做模型訓練微調,ARM 機器加上 Linux 環境,多功能用途比較受限。後來看到 AMD 的 Ryzen AI Max+395 跑推論好像也很猛,就去找有哪幾家有組裝,找到三家可買: Framework Desktop, GMKtec EVO-X2, Bosgame M5 AI (threads 上有人整理有哪幾家)
筆電形式就不考慮了,我已經有 MBP,而且這台也會當作 Server 一直開機,散熱和風扇噪音也要考慮一下,因此覺得小台的桌機更好發揮這台的效益。
這幾家裡面,Framework 這家公司因為 DHH 一直在推薦,所以很有印象。他後來也有寫一篇 The Framework Desktop is a beast 。基本上就是一樣的錢,現在你買 AMD 可以獲得比 Mac 更好的性能。
訂購過程
- 2025/6 月初 官網預訂 (Batch 11),五位數台幣,會先刷一個 3000 台幣訂金
- 2025/9/23 收到準備出貨通知,隔天會刷尾款
- 2025/9/26 順豐到貨
雖然 Framework 是美國公司,但組裝代工是台灣仁寶,因此是從台灣寄出的。他的台灣分公司 美商豐沃電腦股份有限公司台灣分公司 還會開電子發票給你。豐沃果然就是 Framework 麻。
為什麼用 Windows?
後來我改用 Ubuntu 了,後述
這台這麼猛,我是希望不只當作 Server,也可以當作日常多功能用途,有很多 GUI app 畢竟是沒有 Linux 版本。加上 DHH 推薦 VSCode + WSL makes Windows awesome for web development 也很棒,拿來開發環境也可以。
初步使用 WSL 的體驗還不錯,Terminal 打開就是一個真的 Ubuntu Linux 系統,就如 DHH 所說,用 Docker 的話 x86 硬體其實比 Mac 更有優勢。而且有些 app 整合的蠻好的,例如 VSCode 和 Docker,都是安裝 windows 版後,也可以順利無縫在 WSL 內的 Linux 用 CLI 操作。不過我同時也感覺是有複雜性的,畢竟這是 Windows + 子系統 Linux 的架構,例如如何從外部連進子系統 Linux 內,需要額外設定 Port Forwarding。
另外,相比 Linux 跟 Mac 的最大的優勢,就是這台還可以打 PC 遊戲,立刻就把世紀帝國2又裝起來複習一下,各種 3A 大作想必也沒有問題。
實際用了一天,覺得還不錯,雖然 UI 方面還是不如我用了18年的 Mac 順手啦。
安裝過程


這台需要 DIY,這是初始狀態,你需要自己裝 SSD 硬碟、CPU 風扇、前蓋板裝飾、USB 轉接擴充 (都在官網一起買),以及自己安裝作業系統。注意,AMD Ryzen AI Max+395 的 RAM 是不能換的,建議一開始就選最大 128GB 吧。
參考以下官方指南進行安裝。
- Framework Desktop (AMD Ryzen AI Max 300 Series) DIY Edition Quick Start Guide
- Windows 11 Installation on the Framework Desktop (AMD Ryzen AI Max 300 Series) 你需要準備一個 USB 開機碟

注意: 這照片中風扇我裝反了,後來又拆開重裝一次: 風扇要朝散熱片吹,而不是向外吹。
風扇跟散熱片的螺絲孔位也有點沒對齊,我是先不裝那個黑色的導流框,先用四個螺絲鎖並往下壓好之後,再裝導流框。
跑 gpt-oss-120b 速度
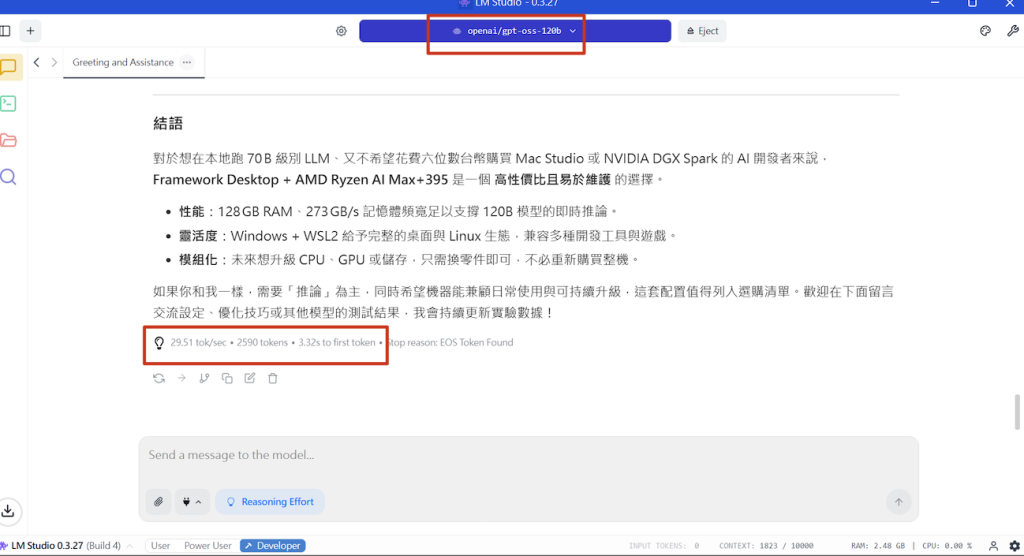
好,回到當時買這台的初心,跑 LLM 大模型。下定的時候 OpenAI gpt-oss 還沒有出,但現在是我最有興趣的開源模型。
請務必按照 AMD 文章的說明: 需要安裝 AMD Software 設定顯卡 VGM 到 96G,以及 LM Studio 設定 GPU Offload 開最大。如此 Framework Desktop (AMD AI Max+395 128g) 的實測速度是:
- gpt-oss-20b (GGUF) 超快,可以跑到 60 tok/sec
- gpt-oss-120b 速度則是 30 tok/sec 也很快!!
Context Length 方面,gpt-oss 模型的上限是 131k。但我這個家用硬體,當然是沒辦法開到滿。目前測試到 12k 是沒問題的,需要再進一步研究設定 (還沒開 Flash Attention)。
作為對比,相比我筆電 MacBook Pro M2 Pro (32g)
- gpt-oss-20b (MLX) 也是可以跑 50 tok/sec
- gpt-oss-120b 跑不起來,ram 不夠
我也嘗試了其他模型例如 Gemma 3 和 Mistral Small 等,但速度都沒有 gpt-oss 來得快,只有 15tok/sec 左右。而 Qwen3 30B 在 LM Studio 裝好就可以跑到 70 tok/sec 超快。要弄好模型 Inference 又是一門大學問了,很多設定在這邊。
以上,有更多經驗再分享。
整理成一個表
AMD RYZEN AI MAX+ 395 w/ Radeon 8060S
RAM 32 GB + VRAM 96 GB
LMStudio 0.3.27 on Windows 11
Vulkan accelerated llama.cpp engine
| Model | 大約 tokens per second | MoE active 參數量 |
| openai/gpt-oss-20b | 60 | 3.6B |
| openai/gpt-oss-120b | 30 | 5.1B |
| qwen/qwen3-30b-a3b-2507 | 70 | 3B |
| unsloth: Llama 4 Scout 17B 16E Instruct GGUF Q4_K_S | 20 | 17B |
| qwen/qwen3-32b Gemma 3 27B Instruct QAT mistralai/mistral-small-3.2 (24B) | 10~15 | 不是 MoE 架構,模型多大 active 參數量就多大 |
結論: 模型大小影響你是否可以載入、以及載入時間。但是實際執行速度跟 active 參數量相關。
更多關於 OpenAI gpt-oss 的資料,我整理在這裡。
補充
Framework 有個 Using a Framework Desktop for local AI 文件不錯:
推薦新手用 LM Studio 入門,把 llama.cpp 包裝成友善的 GUI。目前在 Fedora 42 上跑推理比 Windows 11 快約 20%。
模型選擇策略: 想跑更大的模型又保持速度? 推薦 MoE 架構的模型,例如 Qwen3 30B A3B 和 Llama 4 Scout。MoE 的特色是總參數多但 active 參數少,所以速度快。
更多 AMD Strix Halo 相關資料:
- github.com/lhl/strix-halo-testing/tree/main/llm-bench
- github.com/kyuz0/amd-strix-halo-toolboxes 推薦裝這個包好的 Llama.cpp server,我跑起來推論是最穩的(2026/5)
後續: 改用 Ubuntu Desktop 25.10
用了一週在 Windows 上開發環境還是不順手,想從 WSL 裡面 ubuntu 跑 code,搭配 Windows 上的 Cursor 裡面跑 Claude Code,然後就 gg 了,Claude Code 抓不到 IDE 我在看什麼。另外,我又看到 安德魯的這篇 用 WSL + VSCode 重新打造 Linux 開發環境 文章好長嚇到吃手手。
於是又重裝了 2025/10/9 最新推出的 Ubuntu 25.10 版本,查了一下這種 AMD APU 新硬體,裝最新的 Linux 版本比較沒有問題。結果蠻順利的,也不需要額外安裝任何驅動,安裝 LM Studio 也順利裝起來可以跑 gpt-oss-120b 沒問題,而且原先有幾個 Embedding 模型在 Windows 不能跑(我還以為是 LM Studio 的支援問題),換成 Ubuntu 之後就沒問題了。
後續都沒關機跑了好幾天很穩,也不像 Windows 11 在待機時莫名重開機好幾次,看系統 log 就是 Kernel-Power 事件 41 非正常關機,也找不出什麼原因(有嘗試調整休眠等設定沒用,推測是 driver 問題)。
後續: 與 Nvidia DGX Spark 評測比較
有人用 Framework Desktop 做了 AMD Ryzen AI MAX+ 395 “Strix Halo” 的 Llama.cpp Benchmark,
我拿來跟價差貴了約一倍的 Nvidia DGX Spark 比較一下:
prefill 階段(輸入):
- gpt-oss-120b: 1689 tps (Nvidia)
- gpt-oss-120b: 788 tps (AMD)
- gpt-oss-20b: 3610 tps (Nvidia)
- gpt-oss-20b: 1908 tps (AMD)
decode 階段(輸出):
- gpt-oss-120b: 53 tps (Nvidia)
- gpt-oss-120b: 50 tps (AMD)
- gpt-oss-20b: 80 tps (Nvidia)
- gpt-oss-20b: 73 tps (AMD)
prefill 階段主要是密集矩陣乘法,憑藉更高的算力,Nvidia 明顯領先。但是 decode 階段則受限於記憶體頻寬,兩者表現就差不多了。實際應用通常 decode 階段是主要瓶頸,因此兩者實際體感可能差不多快。
數據來源:
(2026/6) 後續: 升級 Ubuntu Desktop 26.04 和 ROCm
2026/4 推出了 Ubuntu Desktop 26.04 是 LTS 版本更好。
AMD ROCm 也於 2026/5 釋出 7.13.0-preview,正式支援 Ubuntu 26.04 和 AMD Ryzen AI Max+395 (gfx1151) 啦! 最簡單的方式就是用 AMD 包好的 Install PyTorch on ROCm 7.13.0,我實測可以順利跑 PyTorch, Transformers 程式,以及生圖 SDXL, FLUX.2 klein 等等都沒問題。
另外也推薦這個專案 Strix Halo AI Toolboxes 是包好的 Container,我是用這個的 Llama.cpp 來跑 LLM 推論。
用到現在,覺得如果不是要做進階 CUDA 開發,主要只是跑模型推論(LLM, embedding models, reranker models 等等都行) 的話。買 AMD 只需要花約一半價錢就可以買到同級 Nvidia GB10 的性能,是個不錯的選擇。
方便問入手價格嗎 以及保固的相關問題嗎
價格去官網點你要的配置就有了,看到的數字就是台幣 frame.work/tw/en/products/desktop-diy-amd-aimax300/configuration/new
有一年保固 frame.work/tw/en/warranty
除了跑本地模型,這台我在還在觀望,跑bazzite玩steam遊戲,充當家用遊戲主機不知道如何?如果能一機多用就完全不浪費了
跑 Bazzite 玩遊戲完全可以。
別放棄 WSL 啊,很好用的
就是兩個地雷要閃遠一點就好…
1. 別忘了 WSL 是個 VM
2. 別不自覺過度依賴 NTFS
WSL 跟 Windows 整合的很好, 但是終究是 VM
記住這一點就不會有過度期待
透過他 WSL 可以走 windows 的 GPU driver 讓 Linux 能吃到 GPU 算力
省很多事
然後 IO 轉換的效能是大地雷,別嫌麻煩直接把檔案放 VM 內吧
放 NTFS 再 mount 是場災難
請問這台夠openclaw用嗎?