在講完 WebConf 之後,我有種莫名的不協調感: 一方面 Vibe Coding 讓大家寫程式變簡單了,人人都可以做 App 了,也很多人講硬技能不重要了。但另一方面,我覺得開發 AI Agent 產品仍是非常有技術挑戰性的,需要的知識技能深度廣度一點都不少。
最近也看到了幾篇關於 AI Agent 開發的文章,發現國外技術社群在 2025 Q4 也有類似的體悟: Agent 產品開發設計還是很難。
不是「寫程式很難」那種難,而是「95% 的 AI Agent 產品,進到正式環境會失敗」這種難。問題不在模型不夠聰明,而在於周邊的工程架構: context 管理、memoy 設計、錯誤處理、agent prompt 最佳化、語意檢索、評估回饋機制等等,很多都是全新領域,且戰且走的情況。模型只能用幾個月就要升級更換,幾個月前的 best practice 也可能會被推翻重新思考。
總之,以下我整理年底四篇我覺得關於 Agent 開發氛圍的不錯文章:
🔹 實戰踩坑: Flask 作者的 Agent 開發心得
Armin Ronacher (Flask 框架作者) 分享了他開發 Agent 的經驗,幾個實戰觀察:
關於 SDK 選擇: 他們原本用 Vercel AI SDK,現在不會再這樣選了。各模型差異太大,用 Anthropic 或 OpenAI 原生 SDK 反而更好控制。高階抽象聽起來很美好,但最終還是得自己建立 agent 的抽象層。
關於快取管理(Prompt Caching): Anthropic 要求顯式管理快取點,一開始覺得很蠢,為什麼平台不自動處理? 但後來完全改觀,顯式管理讓成本和快取利用率更可預測,還能做到 context 編輯和對話分支這些進階操作。
關於 Reinforcement (增強回饋): 每次 Agent 執行完工具後,不只是回傳資料,還可以塞更多資訊進去: 提醒整體目標、任務狀態、失敗時給提示。這個「增強」機制比想像中更重要。
關於錯誤處理: 如果預期會有很多失敗,可以用子 agent 跑到成功為止,只回報成功結果。但讓 agent 知道「什麼方法沒用」也很重要,能幫助下一步避開同樣的坑。
關於共享狀態: 多數 agent 需要一個共同存放資料的地方。他們選擇用虛擬檔案系統,這樣不同工具和子 agent 都能存取同一份資料,避免資料孤島。
關於測試: Testing 和 Evals 是最難的部分,目前還沒找到滿意的方案。Agent 的特性讓傳統測試方法都不太適用。
他最後補了一段我很喜歡: 「如果你根本不需要 MCP 呢?」很多 MCP server 過度設計,塞了一堆工具吃掉大量 context,其實用簡單的 CLI 工具透過 Bash 執行就好。
🔹 為什麼 95% 的 Agent 在 Production 失敗?
What Makes 5% of AI Agents Actually Work in Production?
這篇來自一場舊金山活動的座談筆記,有句話很中肯: 「大多數創辦人以為自己在做 AI 產品,其實是在做 context selection 上下文選擇系統。」
Context Engineering 不等於 Prompt 技巧: RAG 做得好其實就夠用,不太需要 fine-tuning。但多數 RAG 系統太天真 – 索引太多會讓模型混亂,索引太少又缺乏訊號。進階的 context 工程更像是「給 LLM 做特徵工程」: 選擇性裁剪、驗證、可觀測性都是功夫。
Text-to-SQL 的殘酷現實: 主持人問「有多少人把 text-to-SQL 做到正式環境?」結果沒人舉手。不是這問題太小眾,而是查詢理解真的超難 – 自然語言有歧義,商業術語是領域專屬的,LLM 不知道你公司定義的「營收」或「活躍用戶」是什麼意思。成功的團隊會建立商業詞彙表、查詢模板、驗證層和回饋迴圈。
信任問題是人的問題,不是技術問題: 有位講者說他老婆不讓他用 Tesla 自動駕駛,不是因為它不行,而是她不信任。企業 AI 也一樣。那成功的 5% agent 有什麼共同點? 都有人機協作設計,讓 AI 當助手而不是自主決策者,並且建立回饋迴圈讓系統從修正中學習。
記憶不只是儲存,是架構決策: 大家都想「加記憶功能」,但記憶是設計決策,要區分用戶層級、團隊層級、組織層級。而且什麼時候「個人化」會變成「侵犯隱私」? 有講者說 ChatGPT 推薦家庭電影時直接叫出他小孩的名字,他的反應是: 「別碰我的隱私。」這中間的平衡很微妙。
多模型調度: 正式環境不會所有東西都丟給最強最貴模型。團隊會根據任務複雜度、延遲要求、成本敏感度來做模型路由: 簡單問題用小快模型,複雜推理才用頂級模型。而且哪個查詢適合哪個模型,這個選擇本身也可以隨時間學習優化。
🔹 Agent 能力的金字塔層級
RL Environments and the Hierarchy of Agentic Capabilities
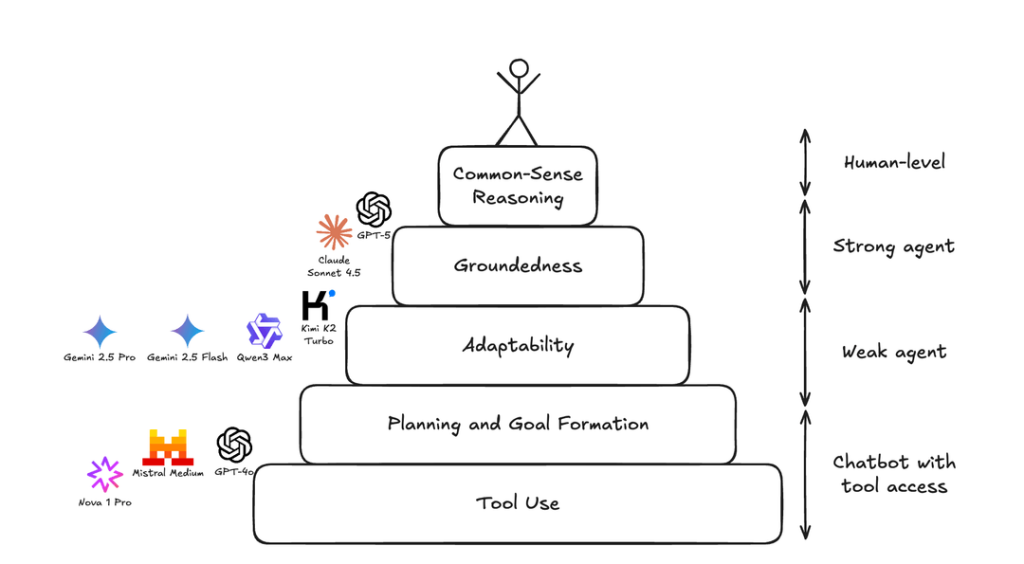
Surge AI 把 9 個頂級模型丟進模擬職場環境,給 150 個客服任務。結果? 即使是 GPT-5 和 Claude Sonnet 4.5 也有超過 40% 的任務失敗。
他們從失敗模式中歸納出「Agent 能力層級」金字塔:
第一層: 基本工具使用與規劃: 能把多步驟任務拆解成小目標、辨識該用哪個工具和順序、正確把資訊對應到工具參數、一步步執行不會跑掉。GPT-4o、Mistral Medium、Nova 1 Pro 卡在這層,連基本的工具呼叫都會出錯,例如把 “gold” 當成客戶 ID 傳進去。
第二層: 適應力: 計畫碰到現實就崩潰怎麼辦? Gemini 2.5 和 Qwen3 常執行正確的工具呼叫順序,但遇到問題不會調整。例如搜尋 “Vortex Labs” 沒結果 (系統存的是 “VortexLabs” 沒空格),它們就直接回報找不到,而不是試其他搜尋方式。相比之下,Claude Sonnet 4.5 會主動嘗試不同的搜尋參數,這正是人類會做的事。
第三層: 接地能力: 保持在當前脈絡中,不要亂編 ID、不要瞎掰事實。Kimi K2 會搞錯年份,系統提示明明說 2025 年,它搜尋時卻用 2024。Claude Sonnet 4.5 有時也會編造 email 地址,雖然它能自我修正,但這種脫離現實的傾向令人擔憂。
第四層: 常識推理: 這是分隔 GPT-5 和人類水準的關鍵。客戶說「包裹幾小時前到了」要求退款,這明顯是退貨不是取消訂單 (因為已經收到商品了),但 GPT-5 沒推理出來。另一個例子是找「遊戲玩家」客戶,合理做法是先找遊戲相關產品類別再搜尋訂單,但 GPT-5 卻笨拙地逐日搜尋整個月的訂單。
結論: 2025 年不是「我們已經實現強大通用 agent」的一年,而是「agent 終於能夠穩定行動,我們可以開始討論分析它們的常識推理能力」的一年。
🔹 解方: Agent 應該更有主見
Agents Should Be More Opinionated
面對這些挑戰,有一個產品開發方向我很認同: 最好的 agent 產品不是最有彈性的,而是最有主見 (Opinionated) 的。
彈性陷阱: 什麼用戶會興奮地自己調整模型溫度和分塊策略? 沒有。以為用戶想要選擇,其實他們想要結果。Steve Jobs 和 iPhone 就是最好的例子: 一個按鈕、一個螢幕,但功能沒有任何限制,魔法在於產品從少數互動點就能可靠運作。
替用戶做大量前置工作:
- 測試每個模型,所以用戶不用測 (不要相信 benchmark,要在你的真實場景測試)
- 寫詳細的 prompt 告訴 agent 成功長什麼樣、怎麼達成
- 每個必填的用戶選項,都代表你沒替用戶做好決定
模型在框架裡是不可替換的: 你沒辦法脫離框架來評估模型。模型智力是「尖刺狀」的,當你設計框架時,你隱含地在繞過模型的強項和弱項設計。所以「升級」到新模型常常會打壞現有框架。唯一重要的問題是: 這個框架 + 模型組合,在我的任務上成功嗎?
從深且窄開始: 寬泛的 agent 想處理太多種任務,demo 很厲害但正式環境很慘,因為每多一個功能就多一堆 bug 和邊界情況。淺薄的 agent 又不夠複雜,根本不該是 agent。甜蜜點是夠窄可以徹底優化,又夠深讓複雜度值得投資。先找出那 10% 能產生最大價值的任務來做 agent,忽略其他的。
連 Anthropic 都在變得更有主見: 他們有專門的生命科學和金融團隊,不是為了做專門的基礎模型,而是在深耕問題領域、優化 agent 框架 (prompts、工具、context、sub-agent)。Claude Code 和 Codex 這些產品也都有內建的工具和 context 管理,而不是給你一堆選項。
—
以上四篇文章分享,算是 2025 歲末 AI Agent 開發的現況。使用 Claude Code、Codex、Cursor 這些 Coding Agent 來寫 code 確實很爽,但別忘了這些是目前最強的 AI 公司傾力打造的產品,而要我們自己要開發 Agent 的時候,挑戰才正要開始。