Hello! 各位 AI 開發者大家好 👋
2026 新年快樂,這期內容偏向 2025 年 AI 年度回顧與整理。
📊 Andrej Karpathy: 2025 LLM Year in Review
大神 Karpathy 發表了他的 2025 LLM Year in Review 年度回顧,整理了 2025 年 LLM 領域最顯著的「典範轉移」
中文摘要在我 Facebook 貼文。
🎙️ Andrej Karpathy: AGI is still a decade away
大神 Andrej Karpathy 在 2025 十月的一場訪談,內容兩個多小時內容很多。這場訪談涵蓋了 AGI 時間表、強化學習的侷限、自駕車的現實挑戰、以及他為什麼從 AI 研究轉向教育等等。
這裡我分享我最有感的四個子主題內容:
- RL 強化學習還不夠,我們還需要新做法
- LLM 的認知缺陷: AI Coding 你很順,只是因為你做的事情 AI 都訓練過了
- 人類如何學習 vs. 大模型: 模型坍塌問題與記憶詛咒
- AGI 最終會融入 2% GDP 增長: 沒有奇點時刻,只有持續的緩慢擴散
中文摘要在我 Facebook 貼文。
🧵 Mark Chen: How OpenAI Shapes Its Research And What’s Next
這是 OpenAI 研發長 Mark Chen (陳信翰) 在 2025/12 接受 Core Memory podcast 的訪談內容。
這篇訪談讓我繼續保持對 OpenAI 的信心,雖然最近 OpenAI 的光環在強敵環伺之下有所減少,但我對 OpenAI 還是最有感情的,也是我投入最多時間研究使用的 API 平台。
這集訪談,可以感受到 Mark Chen「我們知道自己在做什麼,不會被外界牽著走」的自信
中文摘要在我 Facebook 貼文。
🧩 AI in 2025: gestalt
一篇蠻有料的 2025 年度 AI 回顧文章 “AI in 2025: gestalt”,作者是 Gavin Leech 是研究顧問公司 Arb Research 的共同創辦人。
這篇文章有 300 多個引用連結,從模型能力進步、安全研究到產業動態都有深入分析。有蠻多我原先不知道的知識點。
中文摘要在我 Facebook 貼文。
🖥️ Thoughts on AI progress (Dec 2025)
Dwarkesh Patel 是一位 Podcast 主持人,主持長篇訪談節目 Dwarkesh Podcast,訪問過很多 AI 大咖。他最近寫了一篇對 AI 進展的看法,蠻有意思的。
- 短期適度看淡,因為目前的模型缺乏「持續學習」能力,還無法像人類一樣邊做邊學、舉一反三,因此難以真正取代人類勞動力。
- 長期爆發看好,因為一旦這個關鍵瓶頸突破,數十億個能不斷累積經驗、相互分享學習成果的 AI,影響將會是爆炸性的。
中文摘要在我 Facebook 貼文。
📉 The Truth About The AI Bubble
這是 YC 的一場 Podcast 聊到 2025 年最讓他們驚訝的 AI 趨勢,其中最讓我注意的 Anthropic 已經超越 OpenAI 成為新創首選的模型供應商惹。
這也跟我最近看到一篇的市占率趨勢一致: OpenAI ChatGPT 仍然主導消費者市場(高達八成),但企業端市場 Claude 已經略為反超。
不過有趣的是,其中非技術員工仍偏好 ChatGPT,技術人員則更愛 Claude。
中文摘要在我 Facebook 貼文。
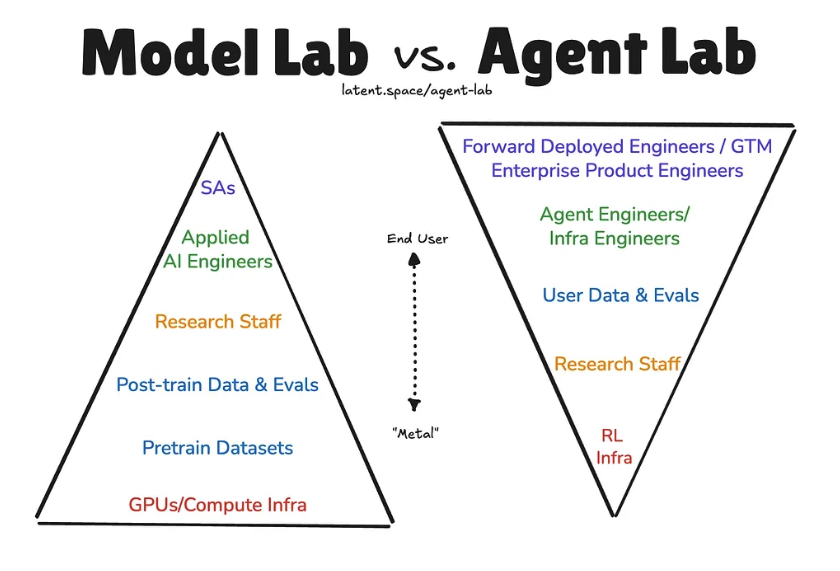
🏗️ The Agent Labs Thesis
最近 Manus 被 Meta 併購,又冒出是不是套殼 app 沒有護城河的說法。這讓我想起前陣子 Latent Space 的一篇文章,提出了一個 AI 公司的分類方式: Agent Labs vs Model Labs。
Model Labs 大家都知道: OpenAI、Anthropic、Google 這些專注在訓練最強模型的公司。
而 Agent Labs 則是另一種打法: Cursor、Perplexity、Cognition、Sierra、Lovable 這些公司,他們不訓練 SOTA 模型,而是專注在打造最強的 AI Agent 產品。
中文摘要在我 Facebook 貼文。
⚙️ 你的工作是提交已被驗證可運作的程式碼!
To 軟體工程師: 你的工作是提交已被驗證可運作的程式碼!
近來在開源專案中,開始出現一種 PR 型態:在缺乏實際使用情境或對應 issue 的前提下,短時間內提出多個小型修正。這類 PR 通常:
- 沒有明確的問題背景
- 缺乏可重現案例或測試驗證
- 描述篇幅很長,但關鍵動機不明確
即使出發點是善意,這樣的提交方式仍可能增加 reviewer 與 maintainer 的負擔,降低審查效率。無論程式碼是否透過 AI 協助產生,責任都在提交者。最好在送出 PR 之前,應確認:
- 問題確實存在
- 修改能穩定重現與驗證
- 變更動機清楚且具體
- 已人工測試並理解影響範圍
剛好最近看到 Simon Willison 這篇 “Your job is to deliver code you have proven to work” (原文連結在留言),是很好的呼籲。
中文摘要在我 Facebook 貼文。
🧩 反向半人馬
上一篇講軟體工程師應該要提交已被驗證可運作的程式碼,沒想到獲得蠻多迴響,看來的確有不少 senior code reviewer 有被提交上來的 AI slop code 氣到 😅
來繼續分享一篇 AI 懷疑論的內容好了,到底 AI 可以取代你的工作嗎? 科幻作家 Cory Doctorow 在華盛頓大學的「神經科學、AI 與社會」講座中,分享了他對 AI 產業的批判觀點。
雖然我不是完全認同,內容也有一些對 AI 技術的理解偏差,但論點仍然犀利值得思考,摘要分享如下:
中文摘要在我 Facebook 貼文。
🚀 AI Coding Accelerator: How Amp uses Amp
看了一場 Sourcegraph AMP (也是一家 Coding Agent 工具) 團隊分享他們內部怎麼用 AI Coding 的實戰技巧,非常讚。
中文摘要在我 Facebook 貼文。
🎯 Evaluating Context Compression for AI Agents 評測
OpenAI API 最近默默推出了一個神奇的 /responses/compact 壓縮功能,可將對話紀錄的所有 assistant 輸出、工具訊息和輸出,通通壓縮變成加密 tokens,只保留 user messages。
這功能可用在 context window 滿的時候,將用戶的歷史對話做一次摘要壓縮,好讓用戶可以持續對話,是開發 Agent 常見的需求。
和使用摘要 prompt 來做不一樣,OpenAI 這個可能是 KV cache 或某層的 hidden state,就像是模型的記憶快照存下來,而不是人類看得懂的摘要,輸出是一種加密的 tokens 給你。
我實際測試了壓縮效果很驚人: 170k 壓縮到 5k,另一串 76k 壓縮到 4k。但壓縮率這麼高,摘要品質到底如何?
最近終於等到 Factory AI 這家公司做了一個實驗來回答這個問題: 當 AI Agent 對話歷史太長超出 context window 時,不同壓縮方法的效果差多少?
他們比較了三種方法,測試資料來自真實的 coding agent session,包括 debug、code review、功能開發等場景,總共超過 36,000 則訊息。
中文摘要在我 Facebook 貼文。
🔎 搜尋技術不會消失,只是變成 Agent 的工具: 談 Agentic Search
看了兩場關於 Agentic Search 的演講,分別來自 AWS OpenSearch 的 John Handler 和 AI-Powered Search 這本書的作者 Doug Turnbull (這有很多檢索知識文章,超讚),兩位都在探討: AI Agent 是否正在取代幾十年累積的搜尋智慧?
全文見我 Blog 文章。
🧭 OpenAI Agents SDK 開發日記: Gemini 3 和跨模型對話支援
我最近貢獻了 Gemini 3 整合以及跨模型支援至 OpenAI Agents SDK: PR #2158,已經被合併發佈 v0.6.5。
開發經驗全文在我 Facebook 貼文。
🧠 Agent Skills 資料整理
Agent Skills 是近期 Coding Agent 非常熱門的功能,我收集整理了一些 Agent Skills 的資料在我的筆記裡。
—
希望你會喜歡這集內容!祝大家在 2026 年的開發與學習一切順利!
– ihower