
Hello! 你好 👋
我是 ihower,這期開始有個新系列是 Google Colab 分享,我會製作既實用又帶有教學意義的小程式給大家。
🔝With AI, Anyone Can Be a Coder Now | Thomas Dohmke | TED
要如何理解生成式 AI 會如何影響軟體開發?
GitHub 是目前做 AI coding 最厲害的公司,不但有全世界最多的 source code 可以訓練,也有微軟爸爸的算力。
最近他們 CEO Thomas Dohmke 有場 TED 科普演講: 透過 AI 任何人都可以成為 Coder (15分鐘、有簡中字幕) 值得一看。
– 目前可用 Github Copilot 工具協助你完成程式碼,將造福更多人可以輕鬆開始寫程式
– 透過自然語言與程式碼互動,未來將有更多人可以是 Coder
– 目前 Github 上有 100M 開發者,預計到 2030 年成長十倍,也就是 1B 的開發者。全球人口 10% 不只會用電腦,還會寫程式!
– 最後還 demo 了最新預覽版功能 Github Workspace: 只要開票,Github 就可以幫你拆解成文字規格,經過你確認修改後,再幫你寫 code 產生 pull request,最後你再檢查程式碼合併進主程式
– 最後主持人提問一個關鍵問題: 預測未來是否還需要人類參與? 回答是: 專業軟體設計師不會消失,仍需要人類去理解要打造什麼東西,仍需要人類專業去維護較大的複雜軟體系統。
幾點自己的看法:
1. 整場 talk 只講 Copilot (AI協助人類寫code),沒有提到 Autopilot (全自動開發軟體),我覺得這才是現況實際可行的發展。講什麼 AI 會取代軟體工程師,專業不要學資訊工程了,這都只是引發 FOMO 焦慮沒啥幫助,就跟去猜明年後年就有 AGI 一樣。
2. 我認為生成式 AI 不但不會減少軟體工程師的需求,反而會增加。有個現象叫做 “Jevons paradox” (杰文斯悖論): 當某項資源的使用效率提高時,反而可能導致對該資源需求的增加,而不是減少。當人人都可以寫點程式的時候,各行各業就會開始自行做些自動化程式,這將會產生更多 IT 軟體需求。
例如最近 Muyueh Lee 就在幫助一般上班族「用 AI 寫程式,讓自己早下班」,AI 小聚跟年會也常有公司分享他們如何自己做自動化。這樣演進下去,當單兵不滿足於 “自動化程式”,想要做一個長期維運的複雜 “軟體系統” 時,就會需要專業軟體工程師的協助。
3. 對軟體工程師來說,技能組肯定是會改變的。這件事情我想大家都已經是過來人,舊技能的需求會減少,新技能的需求會增加。這幾天又上了一次 Will 保哥 的 Github Copilot 課程,保哥就講他現在用嘴巴寫程式,打字退化,因為 Github Copilot 可以接受語音辨識輸入指令協助你寫 code。這樣透過與 AI Agent 交互協作開發軟體的 UX 體驗,是目前演進中的趨勢。
所以,只要你對 coding 有興趣,現在學是再好不過的時機。享受新的軟體開發時代來臨吧。
對 Autopilot Coding 發展有興趣的,可以關注 SWE-bench 評測(AI 是否能全自動解決 github issue) 目前最好的只有 19.27 成功率。所以你要說 AI 已經普遍超越初階軟體工程師我是不相信啦。這有人做深入分析 How Do AI Software Engineers Really Compare To Humans?,你會發現能解決的 issue 大部分都是小範圍的修改。
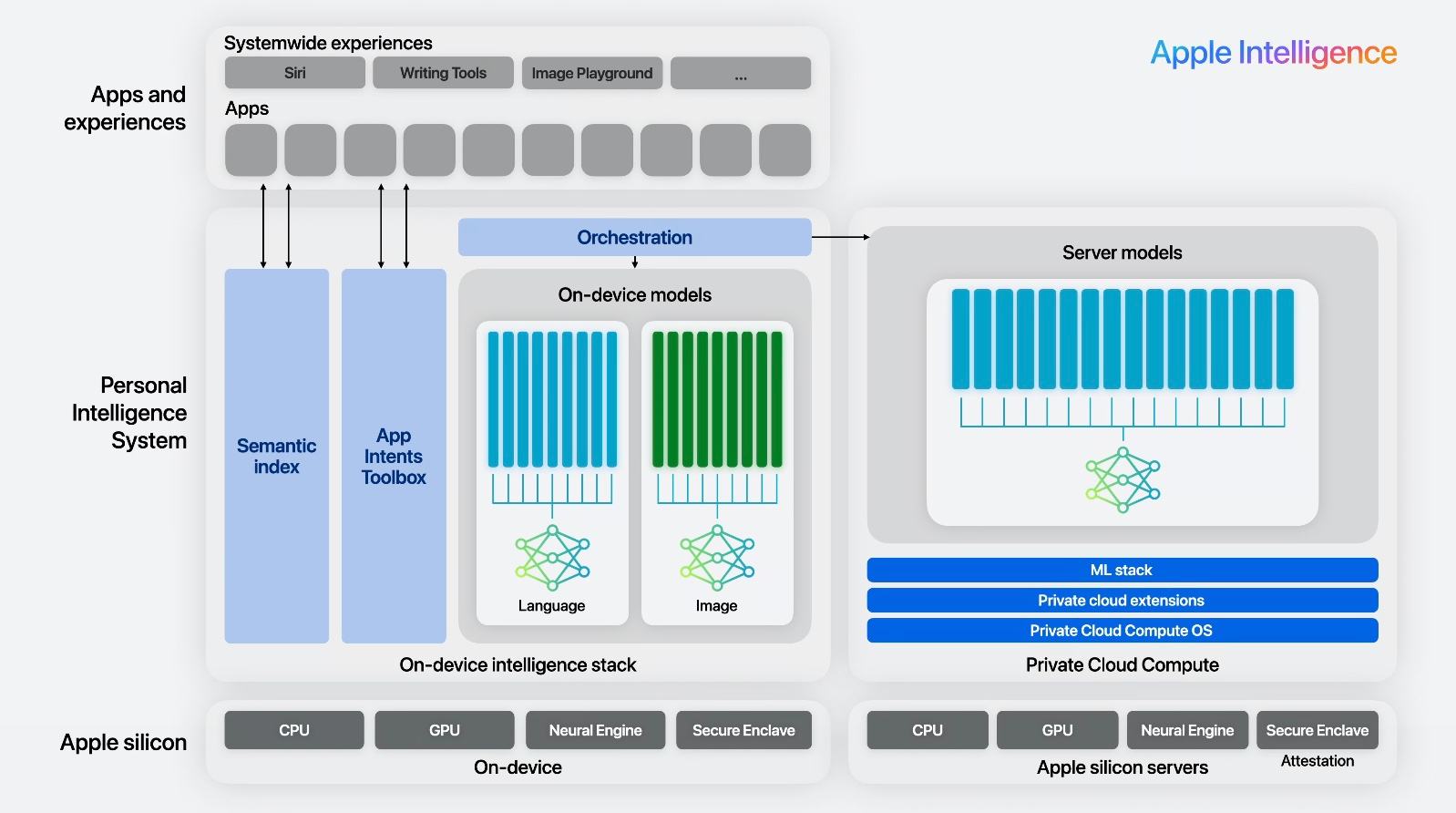
👍Apple Intelligence 發表
今年 WWDC 眾所期待發表了 Apple Intelligence,看來主要是由三個 LLM 所組成:
– Apple 地端 Siri: 判斷問題類型、基本文字任務、呼叫本機 function 等簡單任務,這是個 Apple 自製的 3B 小模型。另外本機還要負責做 semantic search 找出要參考的個人 context 資料。
– Apple 雲端 Private Cloud Compute 的 LLM: 當用戶指令比較複雜時改用這個,會根據傳上來的 context 資料做複雜任務規劃,這是個 Apple 自製特調此場景的大模型 (這 server 也是用 Apple Silicon 晶片,不是 Nvidia 喔)
– 整合外部 OpenAI ChatGPT: 會用於泛用的知識問答聊天,當 Siri 判斷用戶的問題適合 gpt-4o 時,會跳提醒問用戶是否允許去問 OpenAI。這個外部模型我想不同地區將會是可切換的。
詳細技術可以看官方資料 Introducing Apple’s On-Device and Server Foundation Models 和 Platforms State of the Union 影片(0:01:35~0:09:14 這段有說明架構)
最重要的就是這張架構圖了:
🎯李宏毅教授 生成式人工智慧導論
台大李宏毅教授的 “生成式人工智慧導論” 課程全部完結啦! 包括課程影片、投影片和作業 🤩
> 這門課程旨在讓已經熟悉生成式 AI 工具(例如:網頁版 ChatGPT)的同學,深入探索更多生成式 AI 的潛力,並掌握其背後的原理。這門課對學生的背景沒有預設,任何背景的學生都能理解課程內容 。
🚧Google Colab 分享系列: LiteLLM 平行測試多家模型
各位 LLM 高級玩家們,一定常常想要一次測試多家模型吧。這裏幫大家把 Google Colab 程式寫好了 (需自備 API Key)。
一次串 28 個 LLM 而且是平行發送,速度快的先返回結果,總執行時間 = 最慢的那一個
第一次設定比較麻煩些,你需要拿到各家的 API Key 設定一下, 包括 OpenAI, Groq, Gemini, Anthropic, Cohere, Mistral, OpenRouter 共七家
都是註冊登入後就可以拿到了,除了 OpenAI 要先綁信用卡才有 gpt-4,其他我記得都不需要。嫌麻煩你就註解掉不需要的模型即可。
順便介紹一下 OpenRouter 這家 API Provider
這家其實是個 API gateway,後面又串很多家,有幾個中國模型這裡也有,你只需要用這個 API 端點就可以對接多家模型。
然後我再搭配 LiteLLM 這個 Python 套件,統一用 OpenAI API 格式就可以對接多家模型。
所以 Litellm x OpenRouter 就可以輕鬆全部都測到啦。
👊不公開測資的 SEAL Leaderboards 評測
有些 LLM 的 Benchmark 表現好,是因為先看了題目把答案背起來了,而不是腦子好。
上個月 Scale AI 的一篇論文 Careful Examination of Large Language Model Performance on Grade School Arithmetic 實驗表明了資料集污染卻有其事。
最大苦主是 Mixtral 8x22B 和 Phi-3,準確率的真實表現比 Benchmark 還低上 13%,明顯過度擬合(over-fitting) 有背書現象。而 gpt-4 和 claude 3 表現最好,真實性能更高。
實驗的 Benchmark 是用 GSM8k,這是一個公開的小學算術的資料集,可以想像很多模型在訓練的時候,一定會把這個題目放進去訓練。而 Scale AI 從頭做了一個類似的不公開資料集 GSM1k 來做評測,發現很多模型的 GSM1k 分數比 GSM8k 還低! 特別是本來分數就比較低(40%~70%)的小模型,其實際的數學推理能力是更低的。
Jim Fan 大神就說了: 這種不公開資料集的 benchmark,例如 Scale AI 這種可靠第三方做的,會更可靠有用,因為模型廠商不知道題目 😄
而這個 SEAL Leaderboards 就是 Scale AI 最新推出的評測排行榜,題目是不公開的。
👊每月更新測資的 LiveBench 評測
為了避免各家模型因為背書造成高分假象,這是 Abacus.AI 和 Yann LeCunn 合作推出的新 LiveBench 評測。
之所以叫做 Live 就是因為每月都會更新問題集(來自最新的資料,例如新聞、論文、電影等),因此各家模型在訓練時是無法先背起來的。
LiveBench 目前包含 6 個類別中的 18 個多樣化任務,並將隨著時間的推移發布更新更難的任務。
這個月剛推出的 Claude 3.5 Sonnet 目前排第一,但也只是勉強及格 62 分。
更讓我感到震驚的是,小模型 SLM 的分數真的慘烈,分數很低,還有 0 分的。
這種<del>殘酷</del>高鑑別力的評測最喜歡了。
– ihower