
Hello! 你好 👋
我是 ihower,近期全球 AI 工程師最關心的事情,就是在舊金山的 AI Engineer World’s Fair 2024 大會啦 🎉🎉
這次大會有好幾軌,涉獵的主題包括 CodeGen, Open Models, RAG, Multimodality, GPUs, Evals, and Agents 等等。
目前釋出的直播錄影只有公開其中兩天兩軌,但長度也是約 8.5+8.5+3.5+4 約 24 小時的長度。
如何用最短時間,吸收這麼長的英文演講內容呢? 我跟 Claude 3.5 Sonnet 協作寫了個自動化程式,可將影片轉成 不重複圖片 搭配 語音辨識字幕 網頁,並加上中文翻譯。因為看文字的速度,比看影片還快。如果投影片看到有興趣的,旁邊就可以看到對應的逐字稿,不會有漏掉的內容,逐字跟現場畫面都有。
我陸續整理中的截圖和逐字稿都放在這裡,以下介紹幾場內容:
🔝AIE大會: Simon Willison 的 Open Challenges for AI Engineering
Simon Willison 是我很喜歡的一位 Python 工程師,他也是 Django 的共同發明者,近來非常關注 AI 議題。這場分享他講了目前的 ChatGPT 使用者體驗還不夠好要再加油、prompt injection 議題、AI 信任危機: 用戶擔心私人資料被用在訓練,他特別讚美了 Anthropic 在發布 Claude 3.5 公告裡面補充了他們到目前為止,沒有用任何用戶資料來做訓練。最後呼籲我們要避免發布未經審核的AI生成內容,這種內容叫做 slop!
👍AIE大會: Mozilla 的 Llamafile
是的,是 Mozilla,這個 Llamafile 可將模型轉換為單一可執行文件,無需安裝即可在各種操作系統和 CPU 硬體上運行,超猛。
🎯AIE大會: AWS 的 5 practical steps to go from Software
雖然內容偏簡單而且是贊助商場(置入介紹了 AWS Bedrock 和 AWS Q Developer 產品),但是演講標題和行動呼籲我是蠻認同的。
做 AI 本來是機器學習工程師的專科領域,現在門檻已經降到廣大的 App 軟體工程師們,也可以有能力開發 LLM-based 的 AI 應用。
AWS 演講中的五個實用步驟,讓你從 Software Developer 成為 AI Engineer:
1. Understand the basics of Gen AI: 這有很多新的專業名詞要學習,可以看看我的入門投影片
2. Increase your productivity with AI: 讓 AI 輔助程式開發,可使用 Github Copilot 或是這場的 Amazon Q Developer
3. Start prototyping and building with AI: 串 LLM API 很有趣的,可以做些 side project 練練手
4. Integrate AI into your application: 在你的應用中導入 AI 功能
5. Stay updated and engage with the community: 社群參與,例如 Facebook 社團有 Generative AI 年會 、 Generative AI 技術交流中心 和 台灣人工智慧同好交流區 等等,當然也歡迎追蹤我的 Facebook。
這場 AWS talk 還 demo 了一個 Minecraft agent 也很有趣。
🚧AIE大會: Devin AI 創辦人 Scott Wu 的演講
這場是由前一陣非常有話題的 Devin AI,號稱全球首位AI工程師 的 創辦人 Scott Wu 的演講。我覺得他的結尾講得太棒了,容我編排後直接貼上他講的話:
<quote>
Devin並不是決定該做什麼或該構建什麼的人。在軟體工程的核心部分,軟體工程師無論在哪裡,其實都在同時做兩份工作:
第一份工作基本上是用程式碼解決問題。精確地分解出你將構建的解決方案是什麼。你將使用什麼架構?所有的流程和細節以及可能出現的邊緣情況是什麼,並設計出你的精確解決方案。
第二部分是,你將處理除錯或實現不同的功能或撰寫單元測試,或者所有其他涉及到你知道你想做的事的實現過程中的事情。
我認為現在普通的軟體工程師可能花10%或20%的時間在第一個思考部分,而花80%或90%的時間在實現部分。我們真正看到的是,Devin實際上讓你有更多時間做第一部分。
我認為Devin的未來,Devin讓你不必去設置Kubernetes,不必去除錯那些故障的API,不必處理版本變更或遷移,或者那些在軟體工程中佔用大量時間的其他事情,而你實際上會花所有時間在解決面前的問題上。這有點像技術架構師和產品經理的混合體。
所以,我認為我們稱之為軟體工程的工作會改變。但實際上我認為會有比以往更多的軟體工程師。我認為這方面有很多先例。以前編程意味著穿孔卡片,然後是匯編,再後來是C語言。隨著這些技術的發展,大多數人不再使用穿孔卡片,但實際上程序員的數量比以前多得多。
我認為容易被低估的一點是需要編寫的程式碼實際上多得多。這很有趣,因為我們在場的所有人都熱愛軟體。我認為軟體是過去40或50年來世界進步的首要驅動力。儘管如此,我認為我們對軟體的需求實際上可能比現在多10倍。
所以,我認為我們能讓更多人接觸到軟體工程的力量,每個軟體工程師都能提高5到10倍的效率。但我們實際上會做更多的軟體工程。很酷。
有人問,隨著所有這些簡單任務的解決,對於需要學習編程的初級工程師或實習生來說會發生什麼?我認為,坦白說,我認為需求將繼續隨供應增加。
我認為培訓過程會有所改變。但我認為很多這些核心基礎,如果你說某人是一個非常優秀的工程師,通常你不是說他們打字速度很快,儘管他們可能也很快。通常你是指他們對問題有很好的理解,他們知道所有不同的架構,他們從不錯過任何 edge-case 情況等等。所以這些是我認為始終重要的基礎。我認為實習生或初級工程師將更早地接觸到使用這些知識的機會。
</quote>
👊Claude 的的 prompting 技巧
最近 Anthropic 推出 Claude 3.5 Sonnet 模型,各家評測表現蠻好的。大家知道不同模型的提示詞技巧會有點不同,這裏我想分享 Eugene Yan 寫的 Prompting Fundamentals and How to Apply them Effectively 這篇文章,算是少見是針對 Claude 寫的 prompting 經驗分享。
以下是我想分享的重點:
1. 愛用 XML 格式來結構化輸入輸出,可以精準地在 prompt 中描述哪些是資料、哪些是變數。
2. Chain-of-Thought (CoT) 喜歡在 prompt 裡面用 <sketchpad> 來包裹推理過程,你可以理解這就是 AI 的內在思考筆記本。
3. 處理幻覺,除了要告訴模型可以回答不知道,還可以進一步提示 只在有信心的情況下做回答: Only provide an answer if you are highly confident it is factually correct.
4. few-shot 範例給 3~5 個算少,可以給到十幾個以上,看任務複雜程度。
5. 有禮貌或是情勒沒用
6. 可預先填寫 AI 回覆,會文字接龍!
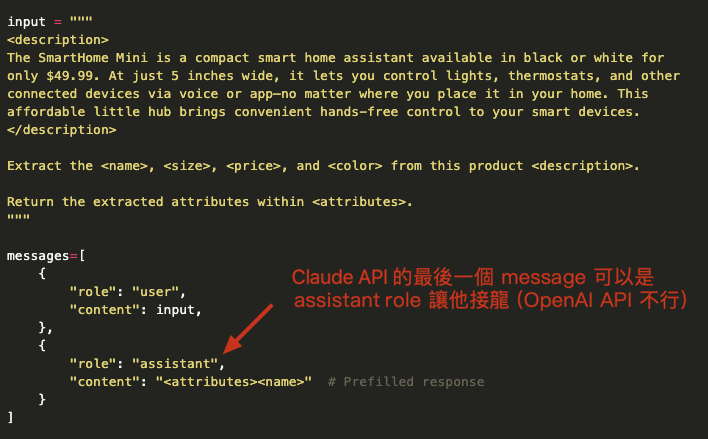
你可以在最後一個 message 填寫 assistant 角色的回覆開頭,這樣模型回覆就會文字接龍。
接龍在 Completion API (輸入是 prompt 字串時)很正常,但是目前 LLM API 各家都改用 Chat API (輸入是 messages 陣列) 後就沒人注意這需求了。
例如在 OpenAI API 中,最後一個 message 若放 assistant 訊息,他不會接龍,而是若無其事的繼續回覆。(Gemini API 也是沒有接龍作用)
但是在 Claude API 是有文字接龍效果的,如果你給 assistant 訊息,那回覆就會是繼續接龍的 assistant 訊息。例如附圖中故意讓開頭是 <attribute><name> 可強迫模型回覆從這個開頭繼續,這樣結尾就會出現</name></attribute> 喔。
我覺得這功能蠻 pro tip 的,希望哪一天 OpenAI API 也可以這麼做。
7. 溫度建議從 0.8 開始,然後根據測試結果再降低溫度!
這點有反直覺,通常我們碰到不是創意開放的任務,在 API 中都直接給溫度 0,沒想到作者發現如果溫度太低,會讓模型變得不聰明。
一般的理解是針對有標準答案的確定性任務(例如單選題)會在 API 中用低溫度。溫度若給高,會讓模型回答太天馬行空發散,因此為了獲得一個最確定的答案所以我們常用溫度 0。只有針對創意或開放性任務才會使用較高的溫度,這是因為溫度 0 比較保守,傾向於選擇最常見的簡單回答,輸出缺乏多樣性導致表現顯得僵化,讓回答看起來不夠聰明和豐富。
所以我看到作者這裡建議不要從 0 開始用蠻訝異的(即使是確定性任務),然後有人去評測 gpt-4o 發現也有這個情況: 在有標準答案的任務上,溫度 1 的準確率竟然比溫度 0 還高,但同一人測試 llama3-8b 時卻又沒有這個現象,看來這不是通則?
總之我目前的感想是溫度 0 不必然是確定性任務的最佳解,也要認真當作一個超參數來跑評估調整。
這裡也引述尹相志老師在我 Facebook 留言解釋: 「因為溫度等於零所生成答案本來就並非是最確定的答案,僅是從詞頻層級來看最必然的答案,而且溫度為零會導致思維鏈以及反思等行為會失效,所以效果變差可以預期。」
最後我覺得 Claude 的 prompting 風格其實更 geek 更有結構,這讓我有點想轉換專攻😆
👊Google Colab 分享系列: 我改寫的吳恩達教授 Agentic 翻譯程式
什麼是 Agentic 呢? 話說 AI “Agent” 代理人這詞因為沒有公認定義,吳恩達教授在前一陣子的貼文中表示,與其爭論一個系統是不是 Agent (例如只 prompt 一次不算是 agent),不如承認有不同程度的 “Agentic” 人工智慧代理程度。
然後,他發現雖然懂技術的跟不懂技術的人,都會使用 “Agent” 一詞。但只有懂技術的會寫 Agentic (目前是這樣啦) 。因此只要文章是寫 “Agentic” workflows 時,他更有可能花時間去閱讀,因為這比較不可能是行銷噱頭文章,而是真正懂技術的人寫的….. 😆
近期吳恩達教授還寫了一個 “Agentic translation using reflection workflow” 使用反思流程的人工智慧翻譯程式,原理步驟如下:
1. 先用 LLM 做第一次翻譯
2. 用 LLM 反思剛剛的第一次翻譯結果
3. 根據反思結果,用 LLM 翻譯第二次
他原版需要在本機執行 Python,我改寫成簡單的 Google Colab 更好上手,可以立即執行看到他的 prompt 是怎麼串接及執行過程。我也改用 LiteLLM 套件來做 API 呼叫,因此很快可以切換成不同模型。
這個 Python 程式碼其實不難:
– 有一個通用的 get_completion function 用來呼叫 OpenAI API
– 上述的三個步驟,分別定義了三個 function
– 最後有個 one_chunk_translate_text function 將上述三個 functions 依序串接在一起
這就是個 <del>prompt chaining 而已</del> Agentic workflow 囉! 適合想要精雕細琢的翻譯場景。
這讓我想起吳恩達教授在 INSIDE 專訪中的這一段 QA:
Q:隨著自然語言 AI 繼續發展下去,寫程式的能力是否仍然重要呢?
A:當然重要。如果你有寫程式能力 ,且懂怎麼下 prompt 給 LLM,那能做的事就更多了!你將大幅擴展使用 LLM 可以做到的事。
—
One More Thing,再講一個台灣 AI 界的大消息是 Project TAME 繁中專家模型 Llama-3-Taiwan-70B 開源釋出啦,這一個基於 Llama-3 70B 做繼續預訓練(Continue-Pretraining) 和微調的大模型,由台大資工、亞太智能機器 APMIC 和多家企業夥伴開發團隊共同合作,使用 NVIDIA 開發者計畫技術支持,針對台灣繁體中文語料,訓練出來的繁中大型語言專家模型 🎉🎉
– ihower