想系統性學習如何打造 LLM、RAG 和 Agents 應用嗎? 歡迎報名我的課程 大語言模型 LLM 應用開發工作坊
延續之前做 Embedding 和 Reranker 評測,這次來研究 RAG 系統中的 Chunking 切塊環節。由於 embedding 和 LLM 模型的長度限制,我們必須將所有文本資料,拆成小塊後再轉成向量放進向量資料庫。
七月份 Chroma 做的這篇非常棒 Evaluating Chunking Strategies for Retrieval,評測了幾個 Chunking 策略,並且提出兩種新的切塊策略,想當然他是用英文文本做的。
因為他有公開 Github Repo 程式碼可以重現他的實驗(非常棒,是真的可以順利執行的),因此我就改成用繁體中文文本試試,排列組合出評測 38 種不同 chunking 的方式。
評估實驗方式
首先根據文本來合成測試問題,他是從你給定的文本中隨機挑 4000 tokens,產生問題和至多五個 references 參考來源。不需要產生答案,因為這個評估是做檢索,不是問答,不涉及答案的生成。然後他還會刪除類似的、不好的問題。因此需要多跑幾次才能湊滿足夠的題目。
用不同 chunking 策略切塊後,用 OpenAI text-embedding-3-large 檢索出前5筆/10筆/20筆,計算檢索後的 Recall 和 Precision 指標,而且這是從 tokens 層面來計算的,超仔細。
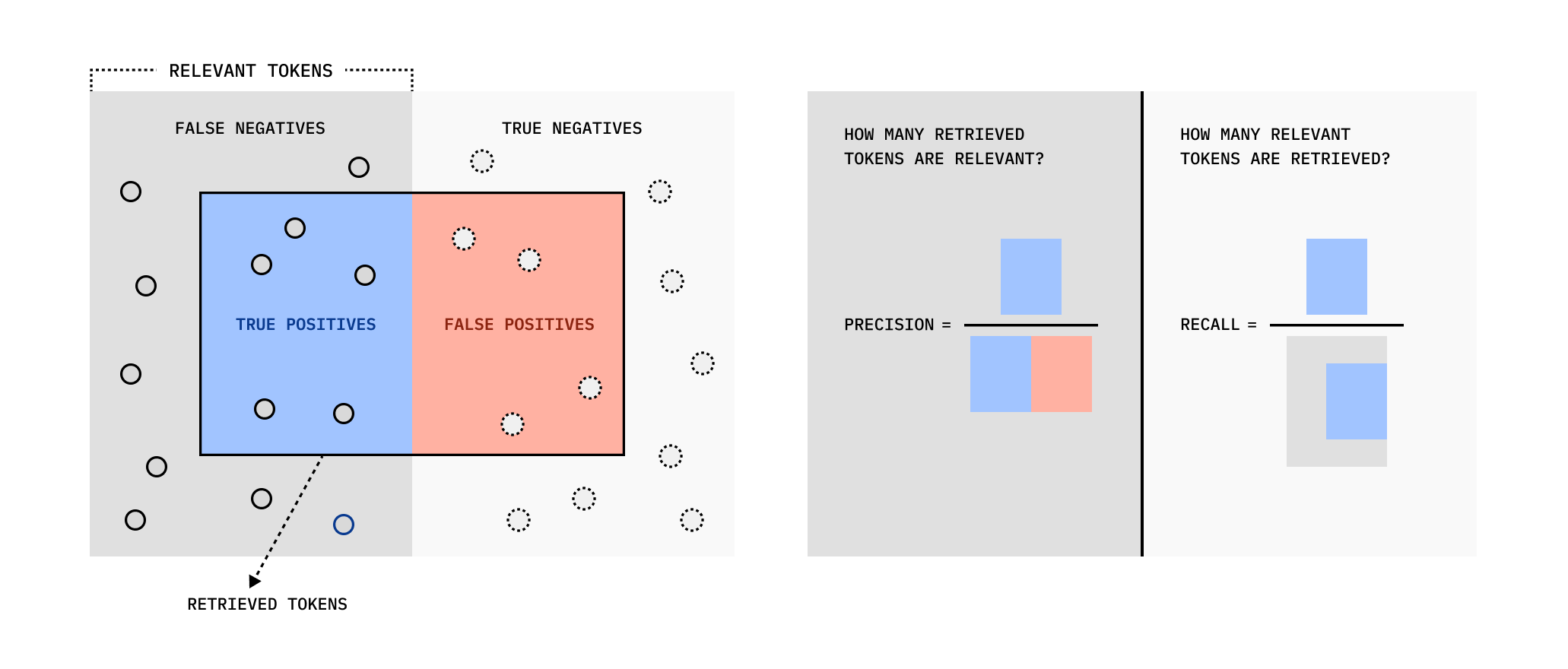
- Recall 召回率: 有多少相關的 tokens 被檢索出來
- Precision 準確率: 檢索出來的 tokens 中,有多少是真正相關的
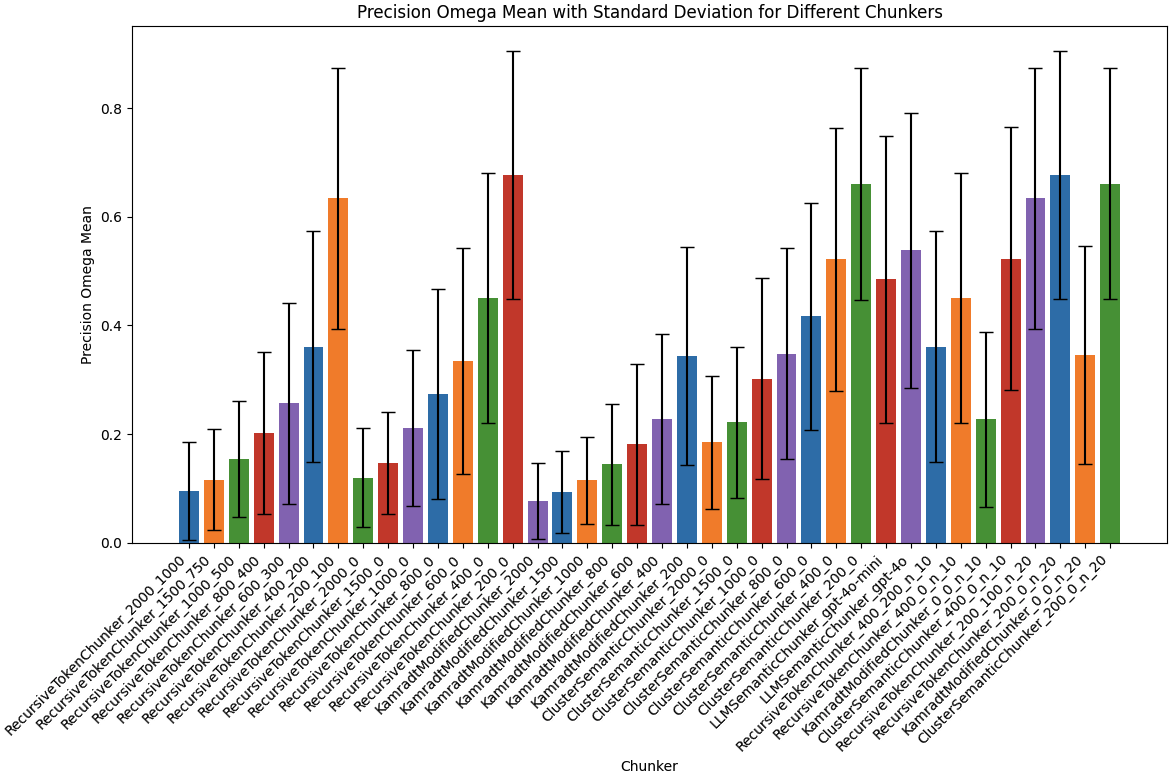
- PrecisionΩ 最大準確率: 假設 Recall 是滿分,最大的準確率是多少
- IoU: 這是作者發明的綜合性指標 (跟 F1 Score 有點類似),高分代表不但能夠準確檢索相關內容,同時最小化不相關或冗餘的內容。低分代表過多無關內容,或是遺漏了相關資訊。
Chunking 策略說明
- FixedTokenChunker: 固定照 tokens 硬切 。不過他的這個實作在中文不能用,因為中文不是剛好一個 token,他硬切 tokens 的結果造成錯誤,根本不能跑。
- RecursiveTokenChunker: 就是最多人用的 RecursiveCharacterTextSplitter 切法,我有稍改一下分隔符號,加上中文的逗號句號等等。這個 chunking 方式除了指定 chunk 大小,還可以指定要前後重複多少 tokens,以改進上下文語意。總共測試了 2000, 1500, 1000, 800, 600, 400, 200 切塊大小以及是否重疊。
- KamradtModifiedChunker: 由 Kamradt 提出的比較每段 embedding 差異來聰明切塊的方式,我測試了 2000, 1500, 1000, 800, 600, 400, 200 切塊大小。
- ClusterSemanticChunker: 根據 embedding 來分群,一樣測試了 2000, 1500, 1000, 800, 600, 400, 200 切塊大小。
- LLMSemanticChunker: 用 LLM 來幫我們切塊,標記哪段跟哪段要拆開。他下的 prompt 傳送門。
我使用的中文測試文本
- 科技: 我 Blog 中的一篇敏捷系列文章
- 投資: 某一篇 中國信託 經濟金融情勢週報PDF
- 科普: 寫點科普的 從萌芽到巔峰:HBM記憶體,台積電與NVIDIA成王之路
- 法律: 勞動基準法
- 小說: 第一次的親密接觸 (前兩集)
每篇大約 1~2 萬 tokens (cl100k_base),乾淨的純文字有段落分行,最後我合成出100題。
合成 Prompt 修改
我有修改他的 prompt,要求合成出來的問題,也必須是繁體中文: This question must be in Traditional Chinese (as used in Taiwan).
另外為了節省成本,模型換成 gpt-4o-2024-08-06,他本來用 gpt-4-turbo。
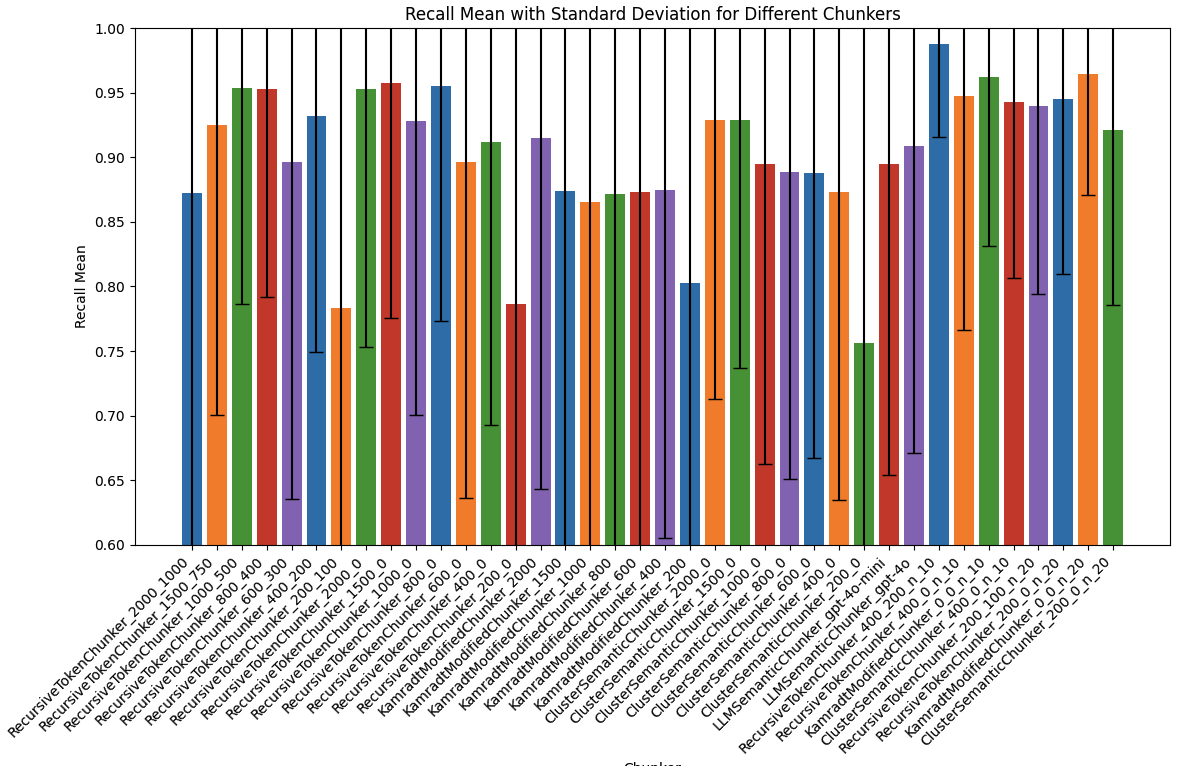
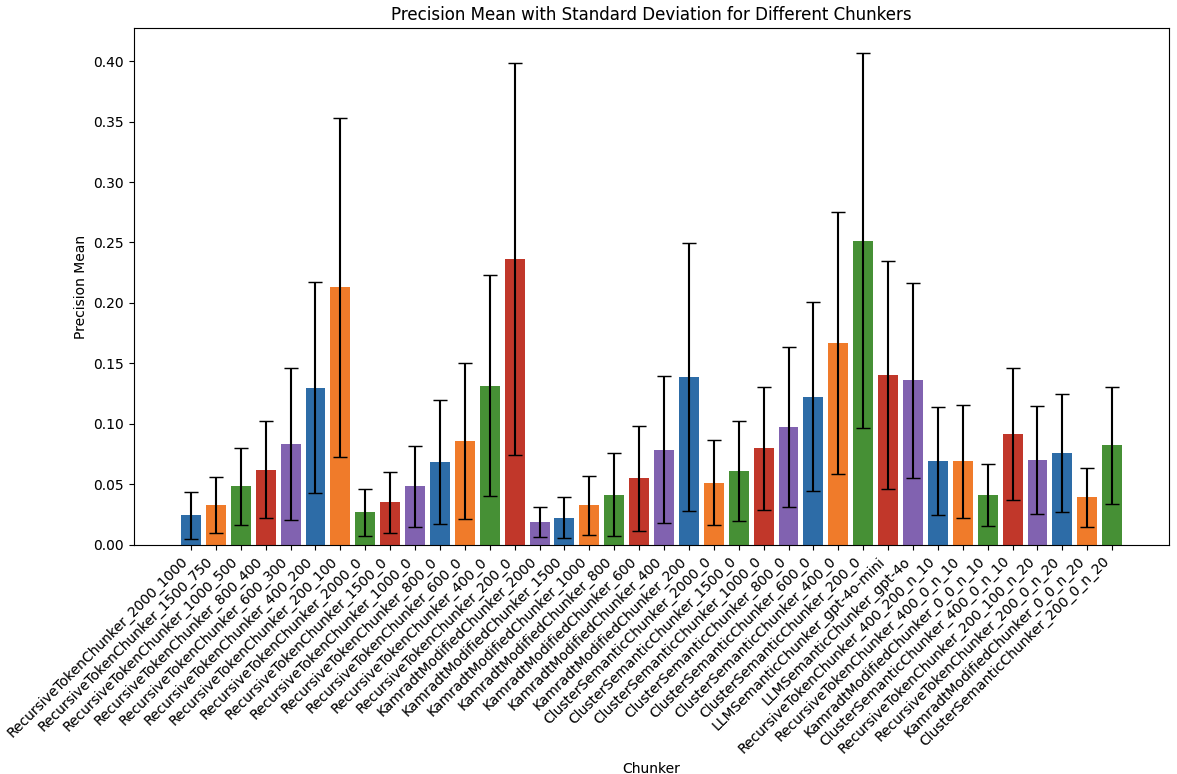
評估結果
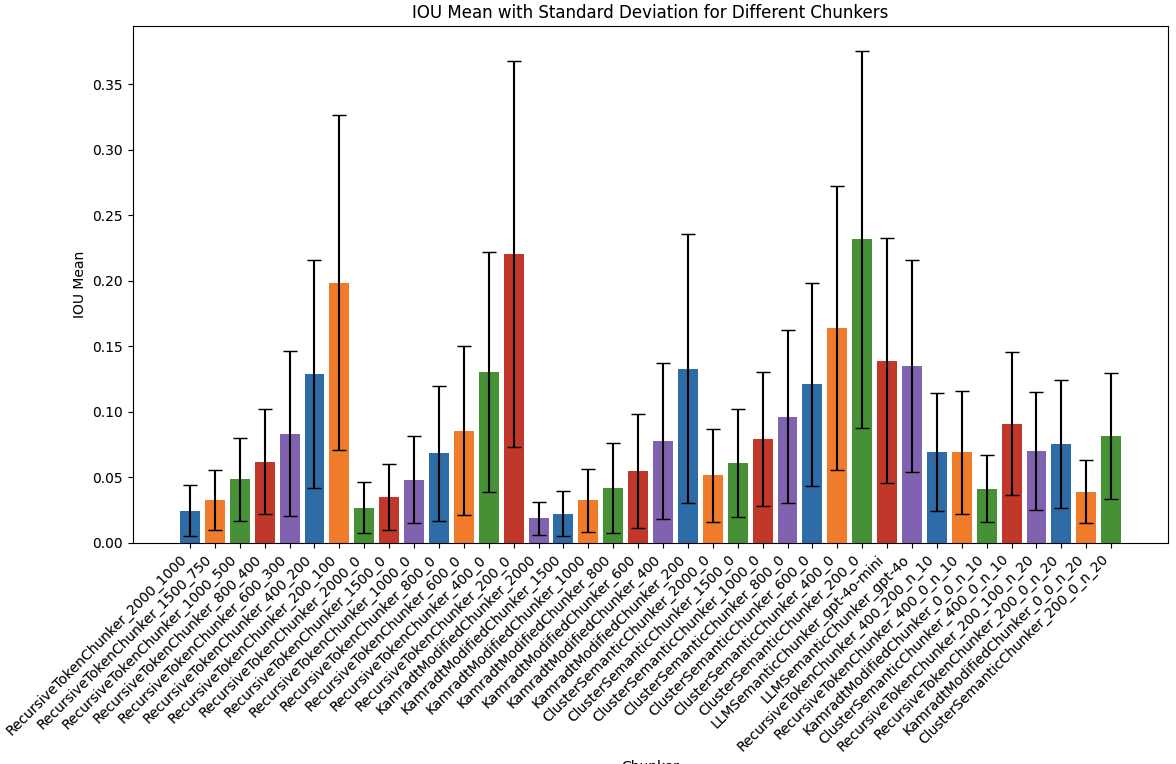
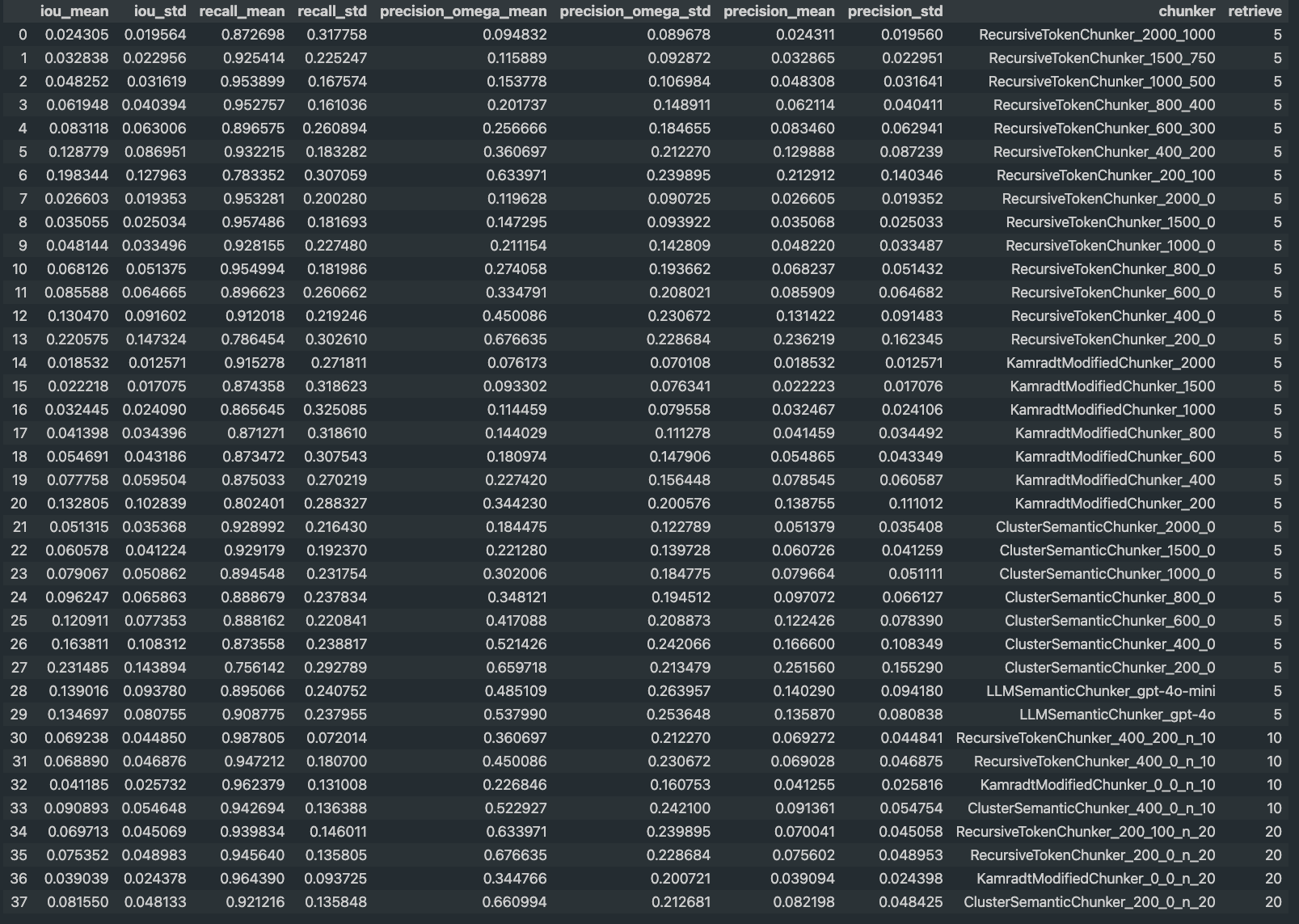
一些結論想法
我會優先看 Recall 指標,畢竟正確的參考資料都沒檢索出來的話,後面 LLM 要生成也就 gg 了。
- 在 top-k 是 5 的情況下
- RecursiveTokenChunker 的 chunk 切太大 1500 以上,或太小 600 以下看來不行
- RecursiveTokenChunker_800_400 這個配方看來是 OK 的
- 若在相同總 chunk tokens 數的條件下,如果切小塊但是 top-k 取高的話,例如 RecursiveTokenChunker_400_200 用 top-k 10,則 Recall 可以更高! 但也不能切太小塊。
- 所以 chunking 的大小,也跟到底要檢索多少筆的 top-k 有關,總 chunk tokens 能用多少跟你 LLM context window 限制有關
- 有用 chunk overlap 標準差會比較小,結果會比較穩定,代價是 Precision 比較差一點,雜訊變多,比較浪費成本,對模型生成也是,例如可能檢索出 4 個 chunks,但裡面快一半都是重複的文字…. XD
- (在 top-k 5 的情況下) KamradtModifiedChunker 跟 ClusterSemanticChunker 做出來沒想像中好,原評測用英文是高分的,但這裡我做中文比較差。個人猜測是這個依賴於 embedding 模型能力,而中文的 embedding 能力畢竟還是差了一點
- LLMSemanticChunker 還不錯,Precision 比 RecursiveTokenChunker_800_400 高,但原評測用這招的 Recall 分數是第一,換成中文後性能也是有所下降。如果文件本來就有用 LLM 清理資料,我會考慮順道試試這招。
在 Recall 差不多的情況下,可以選 Precision 高的,比較有效率。畢竟後面 LLM 生成時,在一樣的 context window 限制下: 單一 chunk 切越大,最後能取的 chunks 總數就比較少,例如 top-k 5,因為一塊就這麼大。切越小,最後取的 chunks 總數就比較多,例如 top-k 10,比較有彈性空間。
至於是否要犧牲 Recall 換 Precision,我認為跟你模型強不強、context window 可以塞多少 chunks 有關:
- Precision 跟切塊大小是非常相關,切越小 Precision 越準,切越大 Precision 越差
- 如果是能力強的大模型,Precision 低一點,有雜訊也沒關係
- 如果是能力弱的小模型,容易被雜訊影響,Precision 太低生成恐會不好,因此切塊需要小
最後,作者的這個切塊評估框架蠻不錯的,如果有實際專案用的文本推薦可以自己跑一跑,看看適合你的最佳 Chunking 策略是什麼。
此評測 Facebook 貼文討論 傳送門 ↗️ (歡迎按讚、追蹤、分享)
想請問一下 ihower 大大,評估結果的長條圖是另外用 matplotlib 繪製的嗎 ?
不是用 matplotlib,這是 Google Sheets 的圖表功能喔
了解! 感謝 ihower 大大的回覆 ☺️
您好,请问可以提供源码吗,我想学习一下
我现在想用简体中文进行一下评估,所以想申请源码学习一下,ihower 大大
您好,我在嘗試重現他的程式碼有遇到一個問題,請問您有遇到過同樣的問題嗎?是如何順利重現他的程式碼的?
我執行程式碼報錯的地方是在執行evaluation.run()的時候,出現以下錯誤訊息:
NotFoundError: Collection [auto_chunk] does not exists