2024/9/11 在 Hello World Dev Conference 分享的演講投影片 ➡️ 這裡下載 PDF (18.3mb)
後續有補充 Textgrad 和 DSPy 的最佳化 colab 通用範例在這裡。
如果你還沒有訂閱我的電子報,歡迎訂閱 📬 愛好 AI Engineer 電子報。
議程介紹:
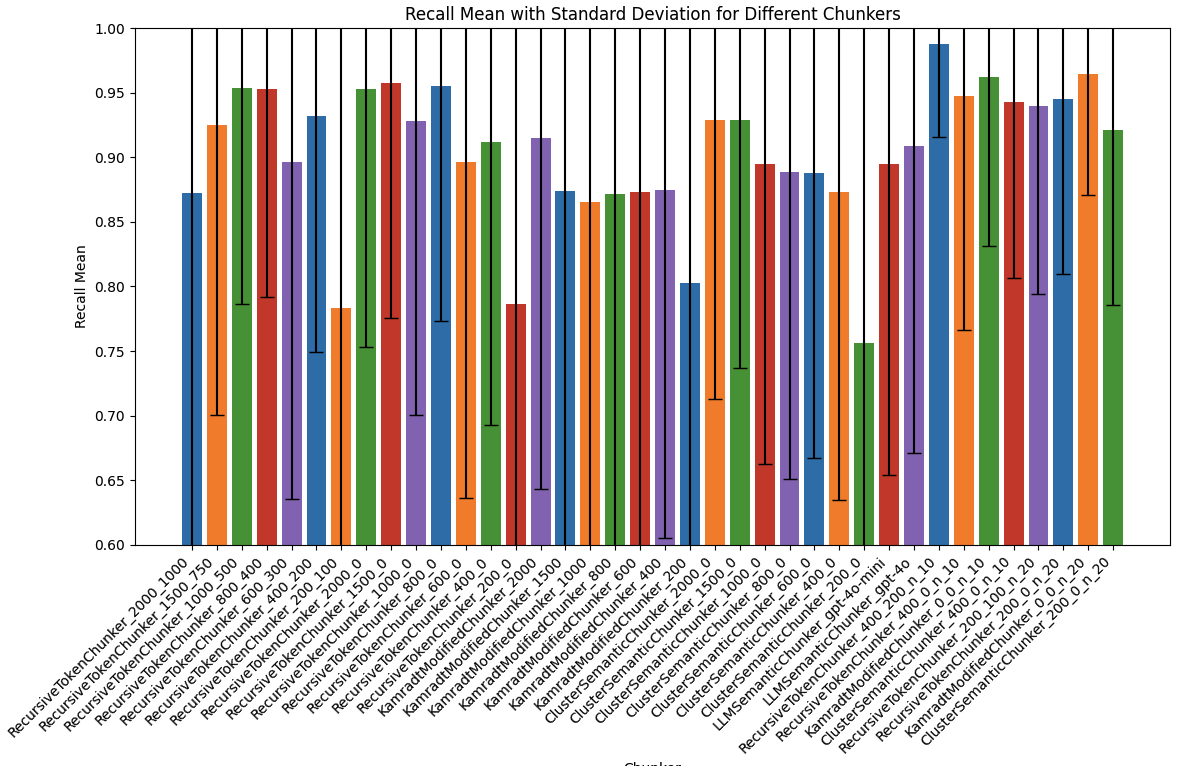
Eval-Driven Development (EDD) 是一種通過特定任務評估,來引導開發 LLM-based 的應用軟體。我們會合成和製作資料集,設計評估指標,然後在評估的輔助下,實現 LLM 應用功能。簡單來說,就是先寫評估再開發。
在評估機制的支持下,我們可以自動最佳化超參數,包括自動提示詞生成 ,來提高應用性能。我們也可以透過這個機制,確保提示詞變更或升級更換模型時,AI 性能不會退化。
最後,評估流程還可以搭配 LLMOps 收集線上數據,進行數據飛輪不斷迭代改進,持續提升 AI 性能。
聽眾收穫:
聽眾將掌握先寫評估再開發的方法論,確保開發出的 AI 軟體能夠達到預期的性能指標。在開發初期就確立明確的目標,從而提高開發效率和結果的可靠性。並且透過自動最佳化超參數技術,可以顯著減少人工調參的工作量,並提升和保障軟體的整體 AI 性能。