這篇 Chip Huyen 寫的 “生成式 AI 應用開發的常見錯誤”,歸納出 6 個容易踩雷的地方,實在心有戚戚焉啦。以下結合原文與我自己的經驗,整理出以下六個觀點:
1️⃣ 不該用生成式 AI 的場景硬要用生成式 AI
大模型 LLM 是很厲害,但是很多人對於這項技術的能力不夠了解,硬要把不適合的需求塞給它處理。例如: 最佳化能源消耗、用來檢測流量異常、用來預測電量、檢測病人是否營養不良等等,其實都不適合用生成式 AI 來做。
我個人也碰過公司想要做些營運最佳化和異常檢測,細問才發現資料都是數字型態。這種不是用生成式 AI 啦,而是應該用專門的演算法或是機器學習來做。
2️⃣ 搞混「爛 AI 產品」與「笨 AI 模型」
很多失敗案例其實不是 LLM 模型不夠聰明,而是產品設計和 AI 工程能力的不足。
例如最近最火熱的 AI Coding 產品為例,無論是 GitHub Copilot、Cursor、Windsurf 還是 Devin,背後用的往往都是一樣的 LLM,差別在於產品設計與 AI 工程做得好不好。所謂的 AI 工程能力,主要是指如何有效提供模型所需的 context(透過 prompt chaining、RAG 等技術),讓模型能在正確資料的基礎上產生有用的結果。若缺乏這些工程環節,再強大的模型也只能”巧婦難為無米之炊”
因此你會看到出現 o3 這種可以解決奧數的聰明模型,又同時看到 Devin 處理實際的軟體開發任務還做不好。根本原因可能不是模型太弱,而是整合的 AI 工程還不夠完善。
最近看到一句話是 raw intelligence ≠ intelligent software systems「原始智力」不等於「智慧軟體系統」
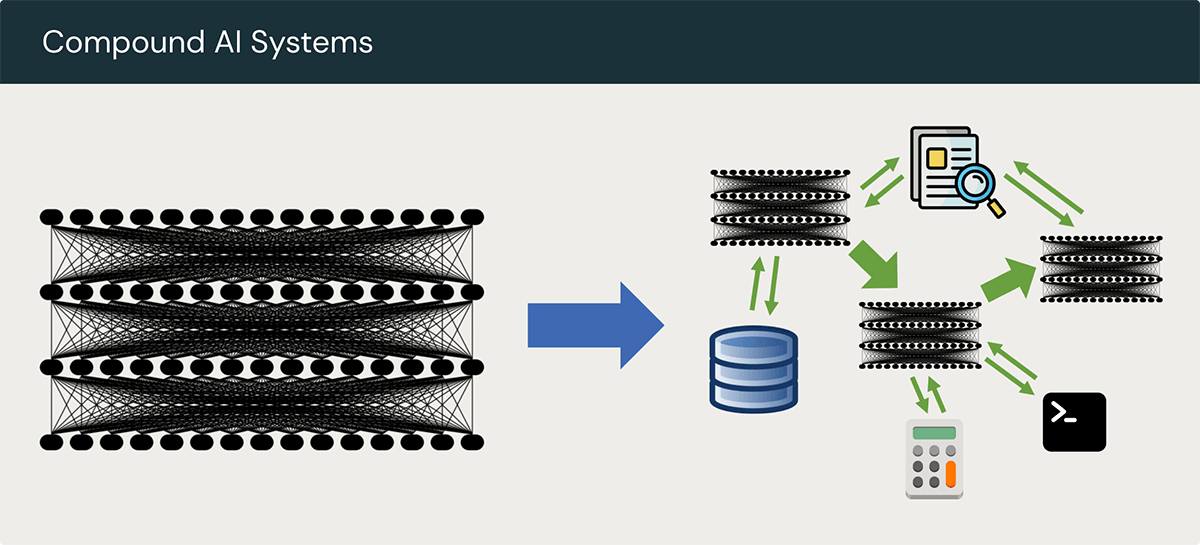
大模型的「智力」只是基石,要把它轉化成真正有效的智慧系統,還需要正確的上下文、工具整合以及成熟的工程化流程,這就是 Berkeley AI Research (BAIR) 所提出的 The Shift from Models to Compound AI Systems 的趨勢:領先的 AI 成果越來越依賴「多重元件」協作,而非單純依賴一個大型模型,才能發揮 LLM 的最大潛能,做出好用的 AI 產品。