想系統性學習如何打造 LLM、RAG 和 Agents 應用嗎? 歡迎報名我的課程 大語言模型 LLM 應用開發工作坊
📊 評估數據結果 google spreadsheets 傳送門 ↗️
Updated(2024/9/23): 新增 Jina Embeddings v3
Updated(2024/9/24): 新增 Voyage-3
Updated(2024/10/22): 新增 mistral-embed
Updated(2025/2/12): 新增 Voyage-3-Large (排第一但也最貴)、Chuxin-Embedding、model2vec
Updated(2025/2/12): 有測 Nvidia NV-Embed v2 模型,但模型太大本機跑不動沒結果
Updated(2025/2/13): 新增 Nomic Embed Text V2
Updated(2025/3/9): 想測 gemini-embedding-exp-03-07,但因為 rate limit 超低很搞笑,無法跑完
Updated(2025/6/16): 新增 Voyage-3.5 跟 Voyage-3.5-lite、voyage-multimodal-3、Cohere Embed 4、Qwen3 Embedding 0.6B 跟 4B
—
在 RAG 系統中,將文字轉語意向量的 embedding 模型,是非常重要的關鍵檢索環節。
很多人在問繁體中文的 embedding 建議選哪一套,通常大家就推薦比較熟的 OpenAI embedding 模型。
但到底哪一套客觀評測比較好,在 HuggingFace 上雖然有個 MTEB 有 (簡體)中文評測,但幾乎都是中國模型霸榜,而且感覺用簡體中文評測不代表繁體中文。
於是我就想自己跑評測看看,週末花了時間,參考了 Llamaindex 針對 RAG 場景評測 Embedding 模型的方法(Boosting RAG: Picking the Best Embedding & Reranker models),使用聯發科整理的 TCEval-v2 資料集中的台達閱讀理解資料集 drcd,其中有不重複文章段落共 1000 段,以及對應的 3493 個問題。
評估方式是將全部問題,以及每個問題對應的唯一正確 context 段落,都轉成 embedding 向量,然後每一題都去做 cosine 相似性搜尋,評估撈出來的 context 是否準確。也就是將 3493 題要從 1000 個 contexts 中,撈出前 5 個最相似的,計算兩個指標:
- 平均 Hit Rate (命中率) : 取 top_k 是 5,在撈出來最相似的 5 筆中,是否包含正確 context。只要有中就1分,沒中是0分
- 平均 Mean Reciprocal Rank (MRR 平均倒數排名): 在撈出來的五筆中,正確的 context 排在第幾名?,若排第一得1分,排第三是 1/3 分 (取倒數),沒中就是0分
我挑選了有做多語言的國外廠商模型,也在 MTEB 中文排行上挑了一些看起來靠譜的(簡體)中文模型,台廠我只查到到台智雲有做。
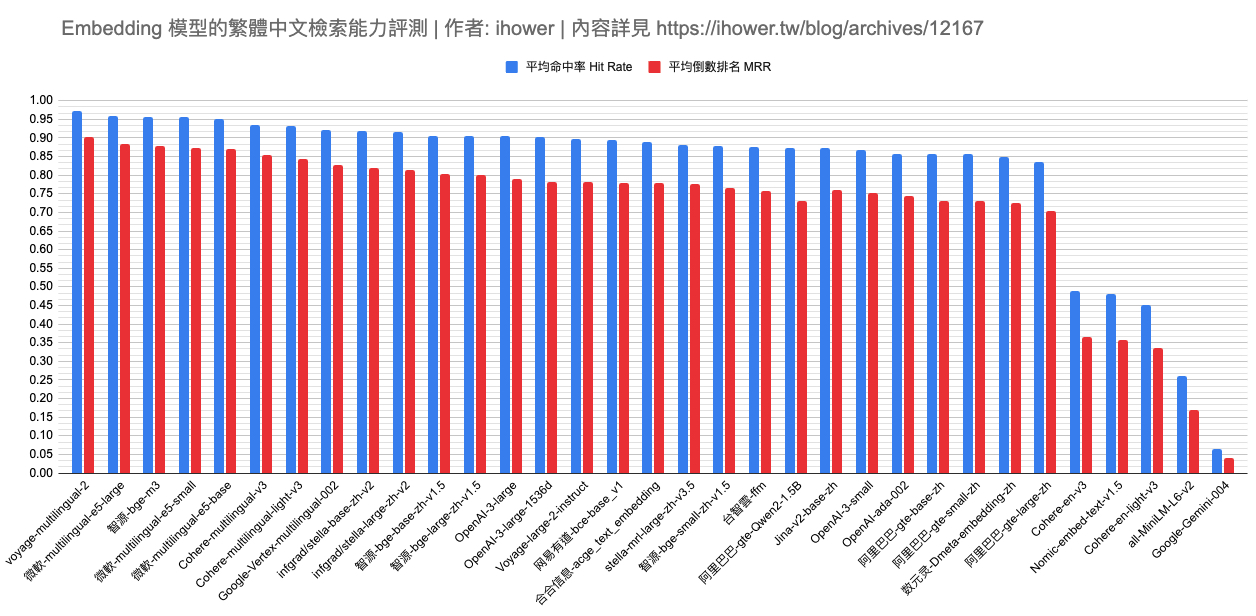
圖表就是評測結果,依照命中率排序。
收穫幾點心得:
- 有沒有支援中文差很多,記得要挑 multilingual 多語言版本,例如 Google Gemini 的 text-embedding-004 分數超慘
- OpenAI 不是最強的,這評測中最強的是 voyage-multilingual-2,命中率 97% 超強
- 開源最強是 微軟的 multilingual-e5-large 命中率 95% 讚讚,可惜輸入的 tokens 上限只有 512 tokens 偏少
- 隨著 LLM 的 context window 變大了,我們原始資料切塊(chunking) 時也可以隨之變大來避免上下文切不好,因此這太小的 tokens 限制會不好用
- 如果分數差不多,可以選向量維度小的,儲存和計算成本較低
- 綜合幾個 trade-off 因素: 向量維度(跟儲存和計算成本有關)、輸入的 tokens 上限(跟切塊有關、跟部署成本有關)、API 價錢、準確率性能
- 前幾名分數其實在伯仲之間,感覺題目還不夠難,歡迎建議更好的資料集
- 這個評估是針對檢索場景,而 embedding 還可以拿來做 分類(classification) 跟 分群(clustering),這個沒測
- 有些模型因此設計可以傳參數表示目前是什麼場景,例如 Cohere 跟 Voyage 有個 input_type 參數,可以指定是 search_query, search_document, classification 或 clustering,這樣效能會更好一點
- 其實也沒有一定最好的 embedding 模型,需要在你自己的資料集上面跑評估才能決定最好模型,推薦 Weaviate 的文章 Step-by-Step Guide to Choosing the Best Embedding Model for Your Application
- 開源 embedding 模型也可以根據你的資料集做微調,進一步提升性能。
- 完整的 RAG 是個 end-to-end 的系統有很多環節,這個評測只測 embedding 模型,並且是在一個沒有切塊(chunking)問題的乾淨資料集上做測試
我的小結論:
- 追求最好性能試試 Voyage-3
- 便宜(USD 0.02 per 1M token 這個價位) 好上手選 OpenAI text-embedding-3-small 或 Voyage-3-lite 或 Jina Embeddings v3
- 開源會選 北京智源人工智能研究院 的 bge-m3 或 jina-embeddings-v2-base-zh (Jina 是德國公司但創辦人是中國人) 或 Jina Embeddings v3 (但這授權是 CC-BY-NC)
- 若切塊 chunk 都小於 512 tokens,可以選微軟 e5 系列,例如做 dynamic few-shot prompting 的場景。
評測數據和程式碼,請見留言連結。若沒測到的你想知道的模型,也歡迎留言告訴我。
最後感謝 Will 保哥 跟 YC 給我的一些指導跟建議。
評測實作細節
程式碼放在 github 上了: github.com/ihower/zh-tw-embedding-model-benchmark
有用到 supabase (一個 PostgreSQL 線上服務) 來存向量資料,這上面有兩個 tables 分別是:
- paragraphs table 存 context 段落,欄位有
- id
- embedding 向量
- model 是哪一種模型
- questions table 存問題,欄位有
- embedding 向量
- paragraph_id 對應的標準 paragraph ID 是哪一個
- model 是哪一種模型
- 程式有兩隻
- indexing-{provider}.py 處理轉成向量,存到 supabase 資料庫
- benchmark.py 從 supabase 取出某模型的全部資料,每個問題跟 paragraphs 去計算相似度,撈出 top-5 然後計算平均分數
但我沒有用 pgvector 做相似度搜尋,一來是為了避免向量資料庫的 ANN 算法有任何誤差,二來數據量也不算是非常多,於是就在本機逐筆算 cosine 相似度了,一個模型也就是 3493 x 1000 = 349.3 萬次 向量計算,以一台 MBP m2 pro 風扇轉一轉還是沒問題的。
所有評測的開源模型都是用 SentenceTransformers 套件從 HugguingFace 上下載模型回來,在我本機 MBP 電腦上跑轉向量的。除了 Qwen2-1.5B 模型因為比較大,且需要 CUDA 是在 Google Colab 開 GPU 跑的,至於 Qwen2-7B 在免費版 Google Colab 也跑不動,就放棄了。這兩個 Qwen2 模型支援到 32000 tokens 輸入,因此需要比較多的運算資源跟記憶體。
另外有些模型的最大輸入 tokens 只有 512 tokens,如果超過會自動截斷只取前面 512 tokens 轉成向量。在本資料集中,問題字串長度確實都在 512 tokens 以下,但是段落 contexts 則有部分超過,大約有 10% 左右的段落文字,落在 512~800 tokens 之間。這部分各家 tokenizer 不太一樣所以 tokens 數也不太一樣。總之對於上限是 512 tokens 的模型,這個評估結果會有些許誤差(應該是低估,實際會更高分),不過如同我上面說的,在 RAG 場景中,恐怕是不會選擇上限只有 512 tokens 的模型來用了。
FAQ
Q: 同一個應用的 Embedding 模型跟 LLM 模型可以不同家廠商嗎?
A: 可以的,兩者在使用上沒關係。Embedding 模型只用於檢索找相似向量,找到向量對應的文字後,文字塞進 prompt 給 LLM 生成答案給用戶。所以兩者在使用上無關。
Q: 不同 Embedding 模型的向量相通嗎?
A: 都不相通,包括同一家出的不同代模型也不相通。
未來展望
進一步評測 Reranker 模型: 我們可加上 Reranker 做二階段檢索,例如第一階段把 top-k 改 10,然後第二階段使用 Reranker 從中取前 5 這樣。如此可以進一步提升 Hit Rate 和 MRR 分數。
Updated(2024/7/14): 下集來了,請見 使用繁體中文評測各家 Reranker 模型的重排能力
—
此評測 Facebook 貼文討論 傳送門 ↗️ (歡迎按讚、追蹤、分享)
好奇問一下: 中研院的CKIP Lab ( huggingface.co/ckiplab )沒有納入評比,是不是只是漏掉還是技術不同? 或是什麼其他原因?
非常感謝大大的資訊分享~
謝謝~
@Thomas 單純是我不知道而已,我來試試。但他的文件沒有寫 embedding 用法,我不確定我做得對不對:
我的 source code 請看 github.com/ihower/zh-tw-embedding-model-benchmark/blob/main/index-ckiplab.py 的 get_embeddings 方法
輸出的 embedding 維度是 768 維、最大輸入是 512 tokens
ckiplab/bert-base-chinese 評測出來的命中率是 0.6767821356999714
MRR 分數是 0.5003960301555483
ihower大大動作好快~ 非常感謝您的資訊~ (唉,ckip這個分數…)
而且CKIP的embedding效能超爛…
最近QWen3 Embedding model開源了,不知道ihower大大有沒有測試過他在繁體中文的成效