(2024/7/25) 有新增內容 LLM-based Ranker 在最後
接續上一篇 Embedding 模型評測,這次我們來看看搭配 Reranker (重排)模型,做成二階段檢索會是什麼情況。
圖片出處: Boosting Your Search and RAG with Voyage’s Rerankers
什麼是二階段檢索?
Reranker 模型是另一種不一樣的模型(學名叫做 Cross-Encoder),不同於 embedding 模型(學名叫做 Bi-Encoder) 輸入是文字,輸出是高維度向量。Reranker 模型的輸入是兩段文字,輸出一個相關性分數 0 到 1 之間,也就是我們會將用戶 query 跟每一份文件都去算相關性分數,然後根據分數排序。

Reranker 的執行速度較慢,成本較高,但在判斷相關性上面,比 embedding 模型更準確
因此當資料非常多、想要快又要準時,跟 embeddings 模型搭配,做成兩階段檢索,是前人做推薦引擎時就發明的招式。
- 第一階段: 從上萬上億筆資料中,用 Embedding 向量相似性,搜尋出前數十名到數百筆
- 第二階段: 從數十到幾百筆資料中,用 Reranker 進行精細的相關性排序
評測方法
我挑選了 4 個 embedding 模型,以及 10 個 Reranker 模型,top-k 取 10, 50, 100 三種,共有 78 種組合。
相比於上次一階段檢索只用 embedding 模型挑出 top 5,這次採用二階段檢索是先用 embedding 模型挑出 top-k 10/50/100,然後再用 Reranker 模型重排取出 top 5 後,再評分命中率和 MRR (倒數排名)
評測結果
評估數據結果 google spreadsheets 傳送門 ↗️
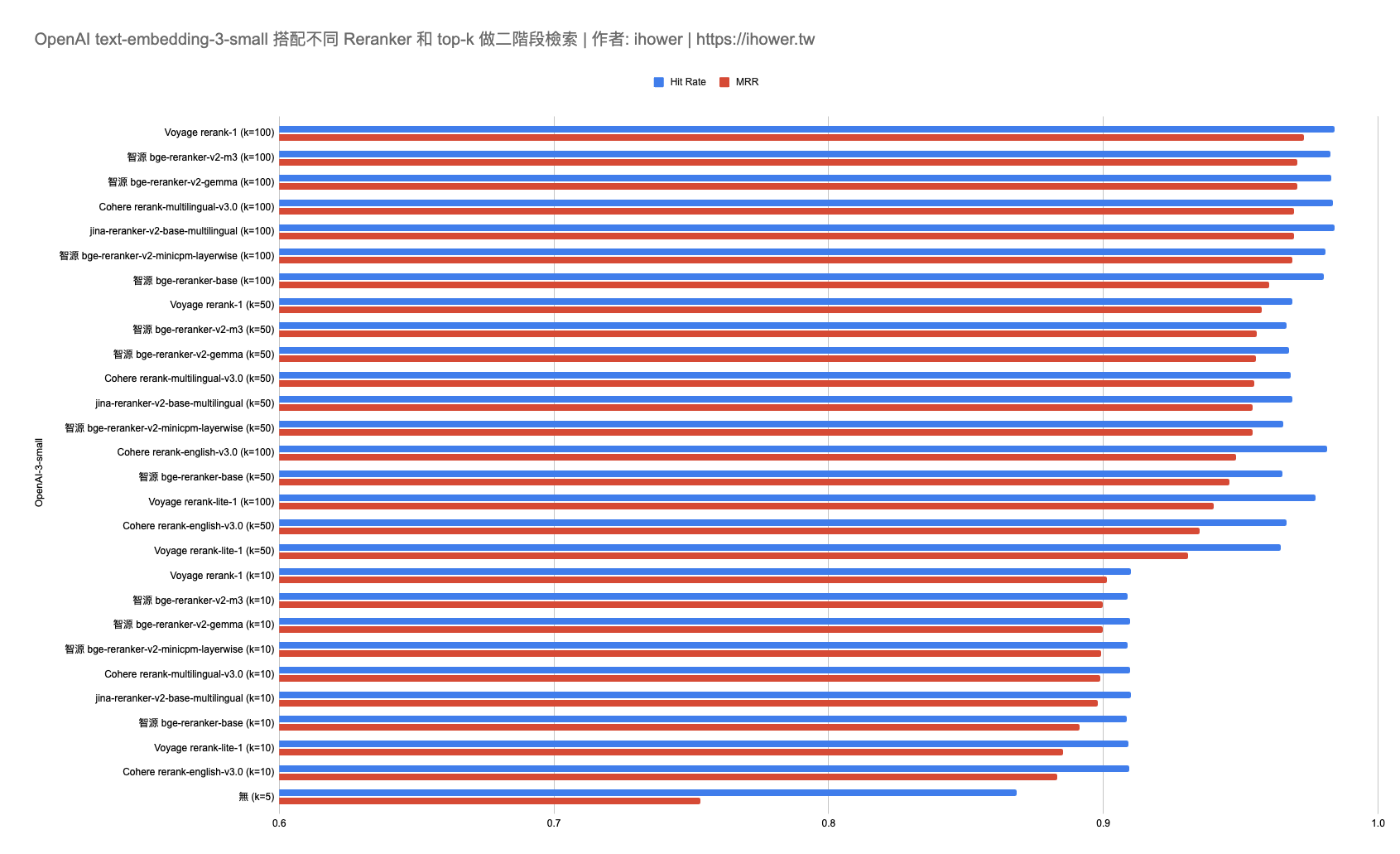
OpenAI text-embedding-3-small 搭配不同 Reranker 和 top-k 做二階段檢索
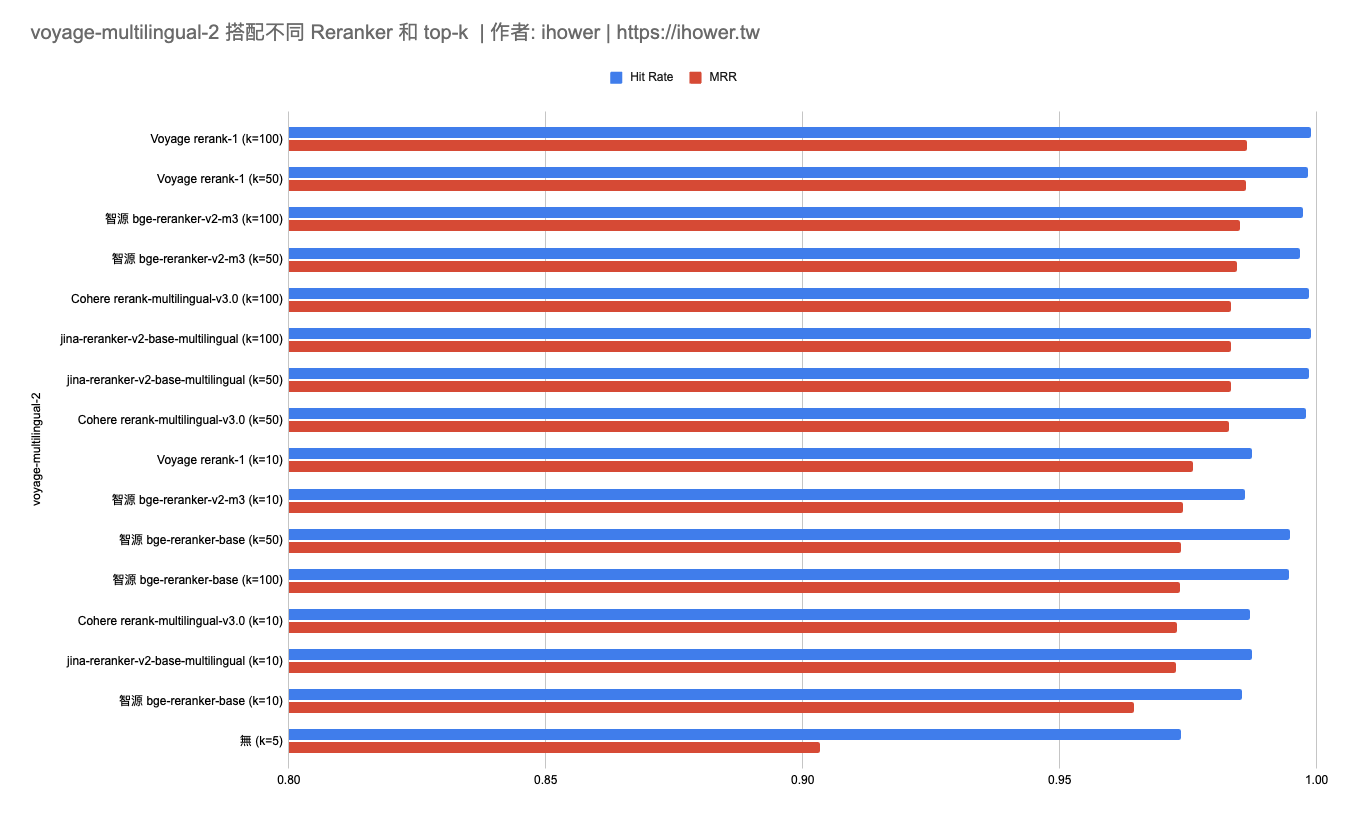
voyage-multilingual-2 搭配不同 Reranker 和 top-k 做二階段檢索
全部排名

收穫幾點心得
- 驚人的準確率: voyage-multilingual-2 embedding 搭配 Voyage rerank-1 (k=100) 成功提升到命中率 99.88% 了,3393題只有4題沒有把正確 context 選進 top 5,而且絕大部分都是 top 1
- 使用 Reranker 進行二階段排序確實能顯著提升命中率。即使是較弱的 Embedding 模型例如 OpenAI small ,在首輪 top-k 100 的情況下重排取前 5,也能達到 98% 的超高準確率,超越所有只用 Embedding 模型的一階段檢索。
- 第一階段 top-k 值越大最後的結果越好,當然限制是 Reranker 的 latency 和 API 成本。用 top-k 10 的確太小了。若文件 chunk 是 500 tokens 可用 top-k 100,若 chunk 是 1000 tokens 可用 top-k 50,如此才可以充分發揮 Reranker 模型的優勢。
- 或是考慮做成動態 top-k 來節省成本: 可根據第一階段搜尋的相似性分數,超過某個低標才進去第二階段重排
- 重排可將 MRR 大幅提升到接近命中率,這代表重排之後很多正確答案就被排到第一位置,這對後續 LLM 生成會有幫助。而且若 LLM context window 有限或想節省 LLM tokens 成本,透過 reranker 重排後取 top 3,也可以有效節省 RAG 耗費的 tokens 量
- 順道一提,重排也可以用在合併多種第一階段搜尋結果列表,例如將用戶查詢,透過 LLM 做一次 Query Expansion 平行搜索出多個結果列表,去除重複後再合併丟進 Reranker 重排
- 對於完全不支援中文的 Reranker 模型,例如 cross-encoder/ms-marco-MiniLM-L-6-v2,當 top-k 增加時,命中率反而下降,排的越多性能越差,笑死
- 不同於 Embedding 模型的成本在前期準備索引階段,Reranker 模型呼叫 API 成本在後期用戶 query 的用量
- 同理,也因為重排發生在用戶 query 當下,因此 Reranker 的速度蠻重要的,幾百毫秒我還可以接受,超過 1秒 我不行
- 開源模型只有 bge-reranker-base (n=10) 我在本機 MBP pro m2 還可以跑,其他需要使用 GPU 不然會太慢,我評測是用 Google Colab 開 A100 GPU 去跑 bge-reranker 系列。
- 綜合幾個選 Reranker 的 trade-off 因素: 搭配的 embedding 模型、準確率性能、速度、價格、第一階段 top-k 選多少,第二階段 top-n 選多少、模型最大輸入長度、API 計費方式或是開源部署成本。
結論
Reranker 做的人比較少,有做中文的選擇又更少了,基本就四家 Voyage, Cohere, Jina 跟開源的 bge 系列:
- 性能: Voyage > bge-m3 > Cohere > Jina
- 速度: bge-m3(有 A100 GPU 的話) > Cohere > Voyage > Jina > bge-m3 (只有 CPU 的話)
- API 價錢: Cohere > Voyage > Jina
- 以 Voyage 費率 USD 0.05 per 1M tokens 來估算,若 chunk 是 500 tokens 加上第一階段 top-k 100 的話,單次重排的費用是 0.0025 美金 = 0.08 台幣
- Jina 費率是 USD 0.02 per 1M tokens
從成本上探討:
- Voyage 跟 Cohere 都是頂級 Reranker,最大差別其實是 API 計價方式
- Cohere API 的計價很特別,是用搜索次數每一千次 USD $2 ,而 Voyage 跟 Jina 都是算 tokens 數。我覺得用 tokens 計價比較有彈性有省錢空間。
- 我得出的公式秘訣是若文件 chunk 的 tokens 數乘上 top-k 超過 4 萬,選 cohere 比較便宜,反之選 voyage 便宜
- Jina API 雖比較便宜,但是 API 是最慢的,即使只有 10 chunks 也要花個 1 秒 (整個檢索階段和網路往返),100 chunks 要 2 秒,有點可惜
- 至於開源模型,你需要部署 GPU 才能把重排速度壓到 1 秒以內
從應用場景探討:
- 如果你有很多很多文件,但是用戶查詢量其實不算多,例如企業內場景
- 這樣適合用便宜的 embeddings 模型,搭配 top-k 100 做重排取前3前5,把成本花在後期 query 動態階段
- OpenAI text-embedding-3-small + Cohere 或 Voyage 的 Re-ranker
- 如果你文件不算多,但是總用戶查詢量比較多,例如 B2C 場景
- 這樣適合 Embeddings 模型用高級的,Reranker 可能就低配省點,把成本花在前期固定成本
- voyage-multilingual-2 + Voyage Re-ranker (把 top-k 取小一點節省成本)
在這個系列實測之前,我對 Embedding 準確性的想像大概就是一個九 90%,沒想到 Voyage embedding 可以做到兩個九 99% ,並且加上 Reranker 之後,還可以再提升到三個九 99.9%,真的是很猛。
當然,RAG 系統有很多環節,至少 Embedding + Reranker 這部分是可以很準的。最後 RAG 輸出結果若不好,很可能是其他環節的問題要改善,例如切塊(chunking) 或 LLM 生成輸出階段。
更多細節補充
程式碼放在 github 上了: github.com/ihower/zh-tw-embedding-model-benchmark 找 reranker-{provider}.py
- Reranker 模型的 context length 長度限制是 query 跟 document chunk 加起來。通常用戶 query 比較短啦,不太會超過 100 tokens。至於 document chunk 通常在 500~2000 之間比較常見
- Voyage reranker
- 輸入支援到 8000 tokens,超過預設會截斷
- API 是用 tokens 數算費用
- 支援多語系的 rerank-1 模型是 0.05 per 1M tokens (對比 gpt-3.5 是 0.5)
- rerank-lite-1 模型是 0.02 per 1M tokens
- Cohere reranker
- 輸入支援到 4096 tokens,超過自動幫你拆 chunks,每個 chunk 算相關性分數,然後取最高分給你
- API 費用是照呼叫次數的,每 1000 次 $2 元
- 每次呼叫至多100份文件,510 tokens 以內算一份,超過要多算一份
- 因此若 chunk 只有 500,建議就 k = 100 份給他,如果 chunk 是 1000,建議 k = 50。因為你 k 就算少丟一點也一樣價錢,只差在 latency 慢一點點而已
- Cohere API 的速度相比其他家是最快的,k = 100 也可以在 600ms 左右完成
- Jina reranker
- jina-reranker-v2-base-multilingual 有開源但授權是 CC-BY-NC-4.0 無法商用
- 輸入長度上限是 1024 tokens,超過幫你拆 chunk 分開算,猜測跟 Cohere 一樣取最高分
- API 價格是 0.02 per 1M tokens 比較便宜,但最大缺點我認為是 API 速度太慢了,即使是 top-k 10 也要 1 秒,top-k 100 要 2 秒了
- 開源的 bge-reranker 系列
- bge-reranker-base 跟 bge-reranker-large 輸入長度限制是 512 tokens,超過截斷
- bge-reranker-m3 雖然輸入 tokens 最大到 8k,但建議小於 1024
- huggingface.co/BAAI/bge-reranker-v2-m3/discussions/8 寫說 “本身基座模型支持最大8192 tokens。但微调的时候使用了1024 tokens,因此超过1024 tokens效果可能有下降”
- bge-reranker-v2-gemma 跟 bge-reranker-v2-gemma 這兩個模型照文件寫性能更高,但我的評測看不出來,而且這兩套模型大小比 m3 大好幾倍,是用不同技術訓練出來的,就算是 A100 去跑 top-k 100 也不夠快,恐需要 H100,玩不起。
- 總之,要實用需要部署 GPU 速度才能接受
費用
- 跑一次評測共有 3493 題,所以 Cohere API 每次測試花了 (3,762 / 1,000) × 2 = $7美金,總共做了 15次給不同 embedding 模型和 top-k 組合,花了 105 美金
- Voyage API 因為是照 tokens 計費,而我的文件 chunk 只有 500 左右,因此在 top-k 50 跟 10 的場景反而比較便宜。整個實驗(top-k 10, 50, 100)全部大約花了 50 美金。
- 為了跑 bge-reranker 模型,買了 Google Colab 運算點數來用 A100 GPU,花了 20 美金
LLM-based Ranker (7/25 新增內容)
除了上述 Cross-Encoder 的 Reranker,也有人在研究直接使用 LLM,用下 prompt 的方式做相關性重排。其中最有名的就是 RankGPT 了,包括 code 和 paper。
RankGPT 的 prompt 長這樣:
system: You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.
user: I will provide you with 5 passages, each indicated by number identifier []. Rank the passages based on their relevance to query: {這裏放query}
assistant: Okay, please provide the passages.
user: [1] {這裏放文件1}
assistant: 'Received passage [1].
user: [2] {這裏放文件2}
assistant: 'Received passage [2].
user: [3] {這裏放文件3}
assistant: 'Received passage [3].
user: [4] {這裏放文件4}
assistant: 'Received passage [4].
user: [5] {這裏放文件5}
assistant: 'Received passage [5].
user: Search Query: {這裏放query}. Rank the 5 passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain.
assistant: [3] > [1] > [5] > [4] > [2]我也用了 gpt-4o-mini 做了 top-k 10 取 5 的 reranker 評測,結果還不差,結果補在 google spreadsheets。3493 題共花了 $2.66 美金,每題的 input tokens 數大約是 4k~5k (有10份文件),速度做1題大約花1秒。
不過如果是 top-k 50 的話,每題要 4s (太慢了不實用),每題 tokens 數大約 22k,輸出結果挺不穩定的,就是50份文件排序,出來的結果常會沒有排好排滿 50 份文件,可能只有前 6, 前 10, 前 41 等等。
感想是: 有潛力,但就成本、速度和穩定性上,個人覺得可能不是首選。有潛力指的是因為 LLM 比較聰明麻,因此語意理解和泛化能力應該有比 Cross-Encoder 強。但是 LLM 就是個相比 cross-encoder 比較大的模型,因此跑起來的成本和速度,都比較大,而且輸出也比較不穩定(輸出出現空結果、沒有重排完整、或是不合法的輸出等)。
Google Research 有篇 paper 改採用 pairwise 的方式(兩兩相比,而不是像 RankGPT 是一次全部列表去給 LLM 重排)來做: Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting,效率似乎更好更穩定,也可以用更小更快的開源 LLM 模型來做,效果也不錯的樣子。但因為沒有 github repo 有 code 我可以直接跑,所以只好之後有空再實作評測了。
—
此評測 Facebook 貼文討論 傳送門 ↗️ (歡迎按讚、追蹤、分享)
github.com/ihower/zh-tw-embedding-model-benchmark/blob/main/reranker-bge.py
關於上面的bge reranker
大大在程式碼評估reranker時, 是一次把所有pairs的內容都丟進去
但BAAI/bge-reranker-v2-m3的token最大是1024, 這樣不會塞不下去嗎?
還是這個限制是指各個query+chunk的長度?
補充: 這樣看起來batch似乎沒有長度限制?只要query+chunk不要超過最大token就好了嗎?
yes, tokens 限制是指各個 query+chunk 的長度,超過做截斷,或是 Cohere API 會自動幫你拆小 chunks 每個算分,然後取最大值。
至於 batch 的限制,API 恐有總 pairs 的上限,例如 Cohere API 至多傳 1000 份 pairs (每個 pair 510 tokens 以內,超過多算一份)