關於 TCP 是什麼就不多說了(回去翻網路概論吧),重點在於TCP如何影響 HTTP Performance ? 承上一篇,這本書列出五項 TCP 重點 :
我們先定義一個 HTTP transaction 表示一個 request command 跟對應的 response result。
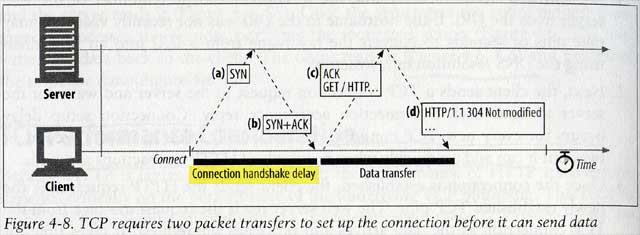
TCP connection setup handshake
在真正傳輸資料前,TCP必須先發SYN及等待SYN+ACK回覆來建立連線,因此小的 HTTP transctions(大部分的 HTTP request 如 GET 用一個 IP 封包就裝的下了 ) 花在建立連線就佔了一半的時間。
TCP slow-start congestion control
TCP 在建立連線後,會先用比較慢的速度,等收到下個ACK之後才乘2加快直到上限。
TCP’s delayed acknowledgment algorithm for piggybacked acknowledgments
因為ACK封包很小,為了有效率地使用網路,TCP會弄個 buffer 來讓ACK等著跟資料封包一起發送,若在 100~200 milliseconds 中等不到才會ACK單獨發送。不過在HTTP的 request-replay 的架構下,降低了等到有相同方向資料封包要送的機會,因此造成了HTTP重大delay。
Nagle’s algorithm for data aggregation
TCP 允許一個封包不用裝滿就可以發送,因此會有封包很多但是都很小的情況發生。為了有效率地使用網路,因此這個 Nagle’s algorithm 會使用 buffer 來等資料滿了或等到別的封包都有了ACK回覆時才發送封包。但是這個演算法會讓HTTP delay因為 HTTP request 常裝不滿呀,而且若還有 delayed ack algorithm 的話會很糟(那邊也等),所以通常HTTP application會關閉這個演算法( TCP_NODELAY )。
TIME_WAIT delays and port exhaustion
這問題在 benchmarking 時比較常發生,一般使用比較不會有這個問題。首先了解到在關閉連線後,記憶體仍會保留用過的雙方 port 跟 IP 紀錄,避免有迷路的封包進來,混亂了下一個使用相同Port的軟體。通常會保留2分鐘,稱作 2MSL。
而在benchmarking的時候,會對server port 80建立很多連線,但是client的ports有限(就說 60000好了),而關閉的連線在2MSL內仍會保留port,也就是說 60000/120 = 500 transactions/sec。因此這會變成不能再快了。要真正測到server,必須多用幾台client或讓server用virtual IP來增加connection的組合。
接著討論HTTP如何最佳化連線,在這之前,先知道 HTTP 在兩個相鄰的 HTTP application 中會用 header 的 connect 參數來傳遞設定值,因此在hop-by-hop的環境中,在forward之前這個參數必須修掉。
HTTP 要面對的delay就是 Serial Tansaction Delays 問題,如果只有先載入HTML,然後依序再傳圖片一圖片二的話,這樣很慢啊,所以這裡有幾招可以處理 :
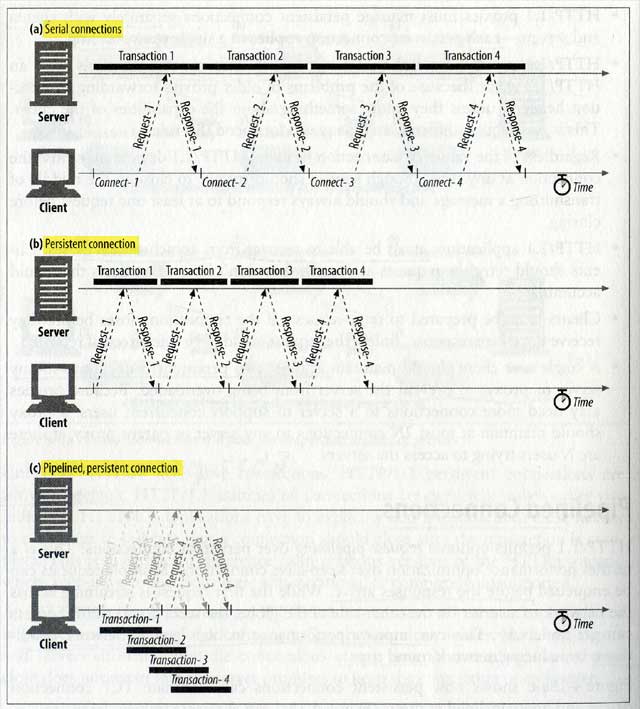
Parallel Connections : 用多個 connections 同步發送 HTTP requests
在收到HTML頁面之後,再同時發送多個連線拿其他的東西。但是注意到如果client的頻寬不夠大,那麼用這招並不會比較快,另外過大的連線也讓記憶體不夠用,尤其對server來說更不樂見,因此通常設成最多4個,而且server可以自由關閉特定client過度的連線。

Persistent Connections : 重複使用 TCP connections 降低 connect/close delay
因為HTML跟圖片常在同一個站,有很高的 site locality,因此HTTP/1.1允許跨HTTP transactions保持open狀態直到client或sever決定close。大大降低 TCP setup和 slow-start的delay問題。
因此光有 Parallel 是不行的,因為每個連線都還有TCP setup跟slow-start的問題,所以必須用Persistent來搭配,但是這招用要小心,不然容易浪費資源。Persistent又分兩種: HTTP/1.0+ “keep-alive” 跟 HTTP/1.1 “persistent”
HTTP/1.0+ (HTTP 1.0後來的擴充) 的 keep-alive 在 header 中使用 Connection: Keep-Alive 表示下一次HTTP transaction仍在同一個connection,因此一但沒了這個參數,就表示要 close connection(所以每個request跟respond都要有 Connection: Keep-Alive 才行)。不過這也不保證client 或 server一定會保持連線。另外 Content-Length 也必須正確計算,不然會失敗。
keep-alive 最大問題出在 Dumb proxy,在舊型或簡單的proxy環境中會有blind relays的問題,書是有詳加解釋,在此略過。重點就是在 HTTP/1.0+ 的環境中,只有在中間沒有 proxy 的情況下,keep-alive 才會開啟。
HTTP/1.1 正式制定Persistent,而且預設就是 persistent connections,所以跟keep-alive剛好相反,是在 header 中使用 Connection: close 表示將關閉連線,同樣也不保證誰一定在收到close之後才close,任何時間都有可能 close。也同樣 Content-Langth 要正確,不然失效。HTTP/1.1 proxy 可以正確支援 persistent connections,但是不對 1.0+ 的 keep-alive 作用。RFC規格中單一client對某server或proxy最多兩個 persistent connections 避免server負擔(因此IE跟Firefox預設就是2)。
Pipelined Connections : 在一個connection 中同步發送 HTTP requests
HTTP 1.1 允許在 persistent connections使用 Pipelining,在 response 回來前,就先發送多個request,在 high-latency 的網路環境中可以大大改善效能。這限定在 persistent 中使用,而且server的 responses 必須依照當初發送的順序回到client(因為HTTP messages沒有記序號啊)。
piplelined的最大挑戰在於server可能在任意時間中斷連線,因此已經發送出來的一大串 requests 必須重新在發送,但是問題在於某些request是有side-effects的(新增修改等),亦無法得知server已經處理了哪些,所以只限定具有 idempotent (無side-effects) 性質的可以用 pipelined (如GET,HEAD),像POST是不應該用pipelined的,且送 nonidempotent request 之前,必須等之前所有request都有response。
另外 Connection Close 又分成 full close 跟 half close。為了Graceful Connection Close,會先關閉 output channel,然後等對方output也關閉之後才關閉自己的input channel (但這也不保證一定會這樣啦)。這是因為如果對方送request來的時候,碰到sever的 input channel 關閉,client 會發生TCP RESET的錯誤,這會讓client清除所有還沒讀取的 buffered data(即使它已經成功從server回來了) ,這在pipelined中特別嚴重。
最後補充一下那篇加速文 :
建議打開 Pipelined : 我查了一下IE系列似乎並沒有實作這個功能(而不是預設關閉),我想是因為比較保守吧(或是偷懶?),在Firefox中也必需手動開啟,我猜想可能還是有不少風險吧(在某些網站GET也是有side-effect啊,要看網站開發者是否堅持GET的本意啊)。另外關於pipelines的功效,早在 1999年W3C 就有實驗證明快很多。其它參考連結 :
- Wikipedia 的 HTTP Pipelined
- Mozilla 的 HTTP Pipelined FAQ
- IE Blog沒找到有文章,只在這篇的comment看到pipelined。
註: 本文插圖引用自 HTTP: The Definitive Guide 一書,版權屬於 O’Reilly Media, Inc.。
11年前的好文~