Hello! 各位 AI 開發者大家好 👋
變成月刊了,這期內容繼續深入探討 AI 工程的核心: 評估、Context Engineering、Agent 和 RAG。
閱讀全文〈愛好 AI Engineer 電子報 🚀 AI Evals 大辯論和 MCP Registry 發布 #32〉😆 👨🏻💻 ✨ 🚀 💰
Hello! 各位 AI 開發者大家好 👋
變成月刊了,這期內容繼續深入探討 AI 工程的核心: 評估、Context Engineering、Agent 和 RAG。
閱讀全文〈愛好 AI Engineer 電子報 🚀 AI Evals 大辯論和 MCP Registry 發布 #32〉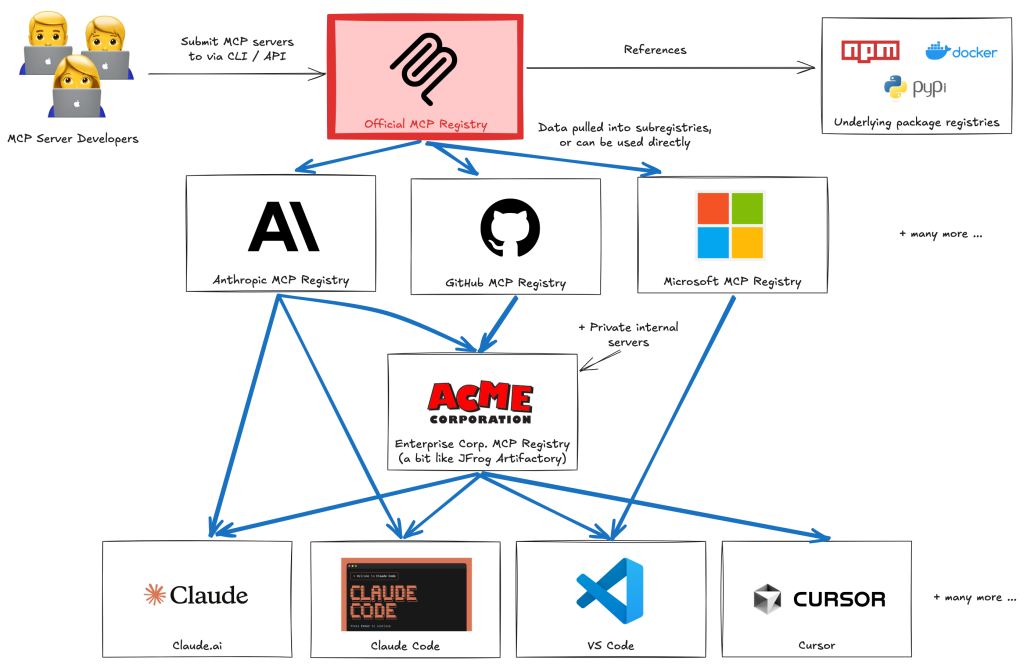
看到 MCP 官方出了一個 Registry [1],GitHub [2] 也出了一個 Registry,這是在打架嗎?
不是的,讓我解釋一下 MCP Registry 的架構。
閱讀全文〈官方 MCP Registry 上線〉
最近看到一場關於 AI Evals 的精彩論戰,爭論焦點不在模型訓練層面的評估(這個大家都有共識要做),而是 AI 應用層面到底要做多少評估。這讓我想起自己在軟體開發的經驗: 如何寫測試也是我曾關注的問題,但說實話,我從來不追求 100% test coverage。即使 Ruby 社群也強調每件事都要有測試涵蓋,但我還是比較考量成本效益,自動化測試對我來說是值得做才會做的事。
現在 AI Evals 也處於類似階段。我去年就開始關注並分享如何做評估,但要求每個面向都 100% 有評估其實是不實際的。AI 是機率性軟體,評估難度更高,AI 的輸出好不好也非常有主觀成分,目前怎麼做很依賴實務經驗交流。最近剛上完 AI Evals For Engineers & PMs 課程,有了新的體會。首先,「評估驅動開發」(指先寫評估再開發) 竟然可能是錯的方向 – 對於沒有標準輸出的 AI 任務,你無法無限投資在評估上。
閱讀全文〈AI Evals 大辯論: 從 Claude Code 訪談引發的反思〉
Hello! 各位 AI 開發者大家好 👋
我是 ihower,這期不小心變成月刊了,暑假真是過太快了。
幫分享今年的 PyCon Taiwan 在臺北文創,總共有 3 種形式的演講與 6 種不同性質的交流活動。
時間是 2025/9/5 – 9/7 👉 活動資訊與購票
Anthropic 最近才釋出了他們在 2025/5/22 開發者大會的完整影片,當時的重頭戲是 Claude 4 模型發布。其中有兩場關於 prompting 教學的演講內容很不錯,這兩場演講從基礎 Prompt 到針對的 Agent 的 prompting ,展現了 prompt engineering 的不同層次,推薦大家一看。以下是我的解讀整理。

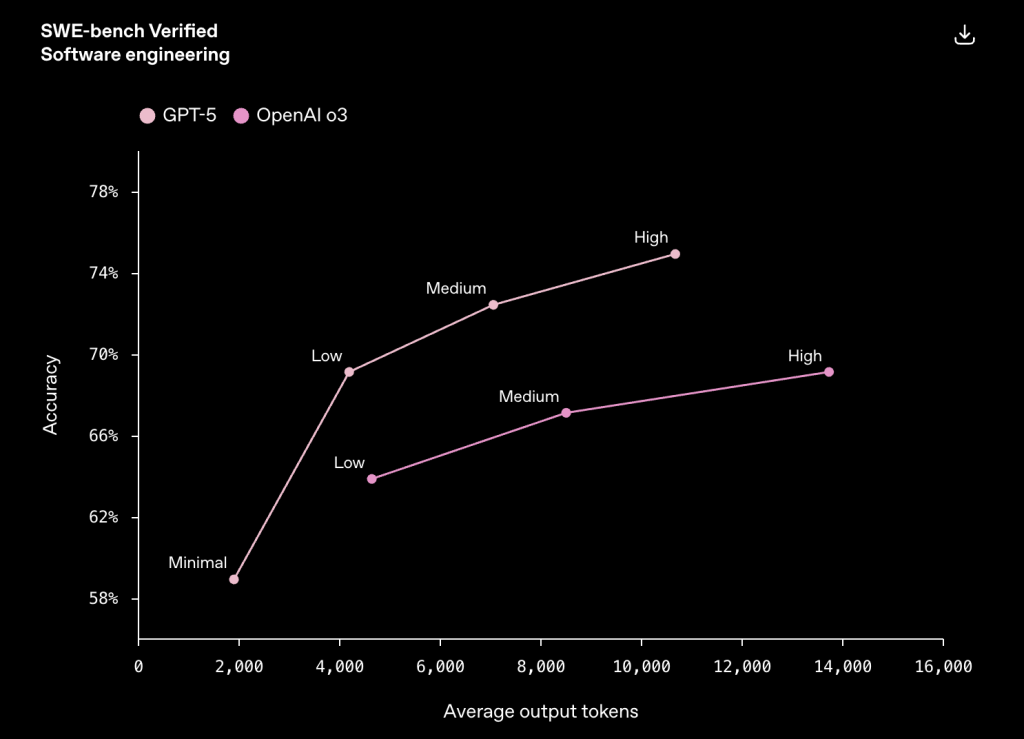
OpenAI 於 2025/8/7 推出 GPT-5,包括 ChatGPT 和 API 都同時上線,這裡針對 AI 開發者快速解惑與整理重點。
首先,ChatGPT App 的模型與 API 平台上的模型,並非一一對應,這點常讓開發者搞混。讓我說清楚。在 ChatGPT App 裡,其實是一個系統,包含: