看了一場 Augment Code (也是一家做 AI IDE 的廠商) 來講 “Agentic 檢索” 對比 “傳統 RAG 檢索” 的演講,蠻有啟發的。
在 AI Coding 領域,簡單的工具正在擊敗複雜的 RAG 系統。
AI Coding 的演進歷程
AI Coding 的演進是這樣:
- 2023: Code completion 補全時代,例如 Github Copilot
- 2024: 出現側欄 chatbot 來寫這個檔案的 code
- 2025: 進到 Agent 時代,例如 Claude Code 可以跨多個檔案寫 code
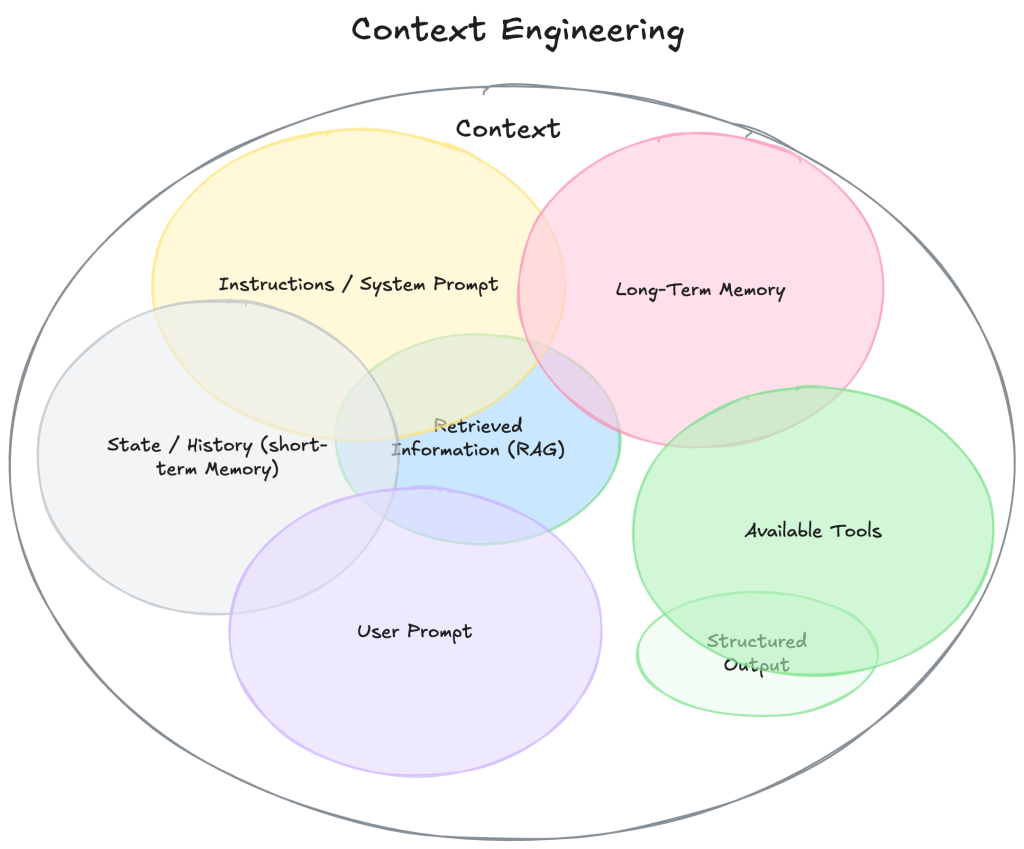
隨著每次演進,IDE 底層檢索的複雜度越來越高。我們知道 LLM 需要正確的 context 才能良好運作(也就是 context engineering),因為需要設計一套檢索系統,找出當下模型所需要參考的程式碼。
像 code completion 只需要超低延遲的簡單檢索即可,chatbot 時代需要理解更複雜的抽象問題,而 agent 就必須理解整個專案的許多不同部分。
他們對 AI Coding 領域的驚人發現是: 簡單的工具就夠了,Augment 團隊在 SWE-Bench 拿下第一名,論文中寫道:「我們探索了新增各種基於嵌入的檢索工具,但發現對於 SWE-Bench 任務來說,這並不是瓶頸。用 grep 和 find 工具就足夠了」。
近期很夯的 Claude Code、OpenAI Codex、Gemini CLI 也通通沒有用 embedding 模型來做檢索。
程式碼檢索為什麼 grep/find 就夠用? 因為程式碼有很多高訊號的關鍵字詞彙,這些結構化的關鍵字讓 grep 搜尋變得非常有效。