資料庫:基礎篇
- 目標讀者: 應用程式初學開發者,特別是 Application Developer
- 目的: 了解關聯式資料庫和 SQL 語法
- 程式語言雖然有提供 ORM 函式庫方便操作資料庫,但是了解 SQL 仍是非常重要的基礎。因為忽略了 SQL 知識,非常可能造成效能問題。
- 以 Web 後端工程師為目標的同學,需要多加熟悉基本 SQL 和資料庫設計
- 對資料分析應用有興趣的同學,例如製作報表等等,更需要會學習使用進階的 SQL 查詢
- Mobile 應用則可用於離線 App 或本地快取用途
前言
程式語言雖然有提供好用的 ORM 庫來操作資料庫,但是瞭解 SQL 仍是非常重要的基礎。因為忽略了 SQL 知識,非常可能造成效能問題。 另外,數據分析相關的應用,例如製作報表等等,也需要更加熟悉進階的 SQL 查詢語法。這堂課將教大家熟悉基本 SQL 和資料庫設計。
1. 什麽是資料庫?
資料庫的作用就是為了保存數據。
程序運行時的數據會放在記憶體之中,但是只要程序結束或關機就會消失了。需要永久保存數據的話,就會存放在硬盤上。我們在編程基礎課程曾經學過,可以利用檔案來將數據放在硬盤上。不過如果數據又多又雜,存成檔案要怎麽命名、檔案要用什麽格式才方便之後查詢,這些都是問題。
資料庫就是為了解決這些問題而發明了,除了可以保存大量數據,資料庫還提供了方便的查詢(Query)機制,以及提供 CRUD(Create, Read, Update, Delete) 操作。
關聯式資料庫
資料庫有很多種,其中一種叫做「關聯式資料庫」 (RDBMS: Relational Database Management System) 是目前最普遍最多人使用的一種資料庫。這種資料庫包括開源的 SQLite、MySQL、PostgreSQL,以及需要付費的 Oracle、Microsoft SQL Server 等等,簡單介紹如下:
SQLite3
SQLite 是一套輕量級的關聯式資料庫,也是 Rails 開發時預設的資料庫。這種資料庫並不是單獨的伺服器,而是會被集成在我們程序(也就是 Rails)之中,它的一個資料庫就是一個檔案,在 Rails 中也就是 db/development.sqlite3 這個檔案。
SQLite 主要是單機用途,在行動裝置、手機上比較常使用,並不適合多人連線使用的場景。因此在實際部署 Rails 到伺服器時,我們會需要換成 PostgreSQL 或 MySQL 等資料庫伺服器。
Mac 本身就有內建 SQLite3,請下載 DB Browser for SQLite 這個 GUI 軟體,就可以打開 SQLte3 的資料庫檔案。
MySQL
MySQL 是目前最流行的開源資料庫,容易上手、資源多、效能好、支援的廠商多,是最多網路公司使用的資料庫。跟 SQLite3 不同,這是一個資料庫伺服器,除了安裝還必須要執行 MySQL 伺服器跑在背景,要連線 MySQL 也必須提供資料庫的帳號密碼。
Mac 上用 brew install mysql 就會安裝 MySQL,推薦再安裝 Sequel Ace 這套 GUI 軟體。
PostgreSQL
PostgreSQL 也是非常流行的開源資料庫,經常與 MySQL 相提並論。和 MySQL 相比,PostgreSQL 的功能比較多,但是在超級大量數據的場景下,不如 MySQL 有更多的的分佈式伺服器經驗。
Mac 上用 brew install postgresql 就會安裝 PostgreSQL 伺服器。GUI 的話,可以考慮安裝 pgAdmin。
Oracle 和 MS SQL Server
這兩家公司提供的資料庫系統,則是需要付費的。通常是非軟體開發專業的大型企業(例如銀行、保險業等等)會採購的產品。這種需要付費的資料庫有更好的自調優功能。
2. 關聯式資料庫的特性一: Schema
在關聯式資料庫中,有一些共通的特性,第一個就是 Schema 綱要:
Schema 綱要
所謂的 Schema 綱要就是使用資料庫存數據前,需要先定義 Tables(表) 和 Columns(欄位):
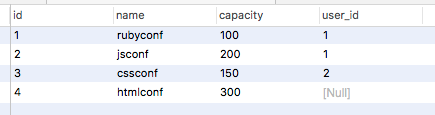
例如在這張 Table,有 id、name、capacity、user_id 等欄位,其中每一行(row)就一筆數據(data)。
相信大家用過試算表(Microsoft Excel 或 Apple Numbers),這跟試算表看起來蠻像的:
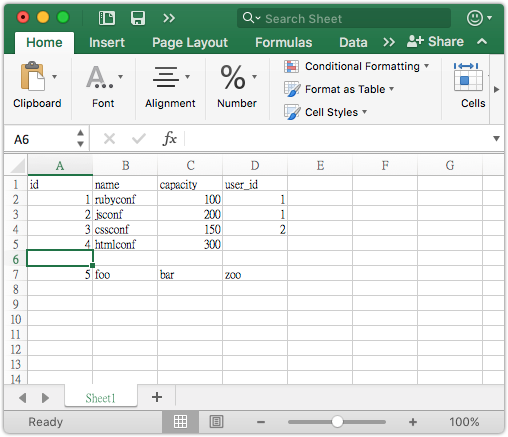
在試算表中,每一格都可以隨便你填什麽,但是 Schema 綱要不一樣。我們需要定義數據型別(Data Type)。每個欄位(Column)都要指定格式,只有符合格式才能存進資料庫。不同資料庫的數據類型大同小異,大體上都有:
- 字串:varchar 或 text。varchar 預設是 255 字符、text 預設是 65535 字符。如果你要開一個欄位來存長篇文章,text 可能會不夠存,需要在額外指定長度。
- 數字: Integer, Decimal, Float
- Blob 二進制: 可以存放檔案。但是通常不建議把檔案直接塞資料庫,一來資料庫塞太大不容易備份和管理、二來沒有什麽好處,因為你也沒辦法針對二進制檔案進行條件搜尋和過濾。人們對於讀檔案也有心理準備會比較慢。所以通常只會在資料庫裡面紀錄檔案的 metadata 例如檔名、大小、MimeType 等等,而實際的檔案則放在檔案系統上,或是上傳到七牛或AWS S3等空間。
- Boolean 布林
- Date 日期
- Time 時間
- Datetime 日期時間
在 Rails Migration 之中,就是在定義這些表的欄位是什麽格式,例如:
create_table :events do |t|
t.string :name
t.text :description
t.integer :capacity
t.integer :user_id, :null => false
t.timestamps
end
在Rails 實戰聖經有一份對照表。Rails 會根據資料庫的不同,自動對應使用不同的數據型態。
除了定義 Data Type,你還可以在 Schema 中定義限制 (constraint),最基本就限制是 NOT NULL 必填不能為空。
資料庫還可以設定更多數據驗證,不過你會發現這跟我們在 Rails model 中的 validations 的作用是一樣的。所以通常我們偏好在 Rails 裡面做驗證,而不是在資料庫這層做。優缺點是:
- 在 Rails 做比較有彈性,可以用 Ruby 來寫驗證邏輯
- 在 DB 層做是硬條件,無法跳過這個驗證
早期的資料庫非常重視 Data/Entity Integrity 資料驗證,這是因為早期的資料庫用戶,就是直接操作資料庫。但是對近年來的網路公司來說,用戶不會直接操作資料庫,而是都會經過網站應用伺服器(例如 Rails),用我們寫好的功能間接地使用到資料庫,因此我們可以在應用層驗證好數據即可。
3. 關聯式資料庫的特性二: SQL 標準語法
關聯式資料庫都支援使用一種叫做 SQL (Structured Query Language) 的結構化查詢語言。我們會用這種語法來操作資料庫,例如:
INSERT INTO events VALUES ("RubyConf", 100);
這個 SQL 句會插入一筆數據到 events 表。
SELECT * from events;
這個 SQL 句告訴資料庫拿出 events 表的所有數據。在 Rails 之中雖然我們沒有直接撰寫 SQL 句子,其實是 Rails 內部是自動幫我們轉換好了,例如剛剛的句子,我們是寫這樣的 Ruby 代碼:
Event.create( :name => "RubyConf", :capacity => 100)
和
Event.all
在 Rails 內部則會自動轉換成 SQL 句,來向資料庫進行操作。在稍後的章節我們會詳細介紹這個 SQL 語言,你必須進一步瞭解 SQL 語言,才能夠完整瞭解 Rails 是如何操作資料庫的。
4. 關聯式資料庫的特性三: ACID
關聯式資料庫的另一個重要的特性是 ACID,也就是 Atomicity, Consistency, Isolation, Durability。在解釋個別的意義前,我們先介紹一個關聯式資料庫的功能,叫做 Transaction 事務。
請想像這樣的場景:當你再做銀行轉帳時,A 的餘額會減少、B 的餘額會增加,如果這是兩個 SQL 操作的話,我們如何能保證這兩個 SQL 操作必須是一起成功的?不能發生 A 錢變少了,但是 B 沒有收到錢的情況。或是考慮一個更極端的場景,如果你和別人同時同一秒鐘互相轉帳,資料庫會不會算錯餘額?
要達成這種跨 Tables 多個 SQL 操作必須同時完成(或失敗)的需求,就必須用上 Transaction 事務。語法是用 BEGIN; 和 COMMIT; 把 SQL 句包裹在一起,例如:
BEGIN;
INSERT INTO histories (user_id, amount) VALUES (1, -100);
INSERT INTO histories (user_id, amount) VALUES (2, 100);
UPDATE accounts SET balance=200 WHERE id=1;
UPDATE accounts SET balance=300 WHERE id=2;
COMMIT;
每個 SQL 句必須用分號
;代表結束
這樣 BEGIN; 和 COMMIT; 中間的所有 SQL 句,就會一起遞交給資料庫,要麽一起成功、要麽一起失敗。
非常多場景會用到這個 Transaction 功能,來保證數據的正確性。在 Rails 中,每個 model 的 save 其實都會用 Transaction 包起來,包括 model 裡面的所有 callback 都會在同一個 Transaction 事務裡面。
如果是跨 model 的話,你也可以用 ActiveRecord::Base.transaction 來包裹 Transaction 事務,例如:
ActiveRecord::Base.transaction do
A.save
B.save
C.save
end
ACID
ACID 其實就是在說明 Transactin 的能耐,以下取自 wikipedia:
- Atomicity 原子性:一個事務(transaction)中的所有操作,要麽全部完成,要麽全部不完成,不會結束在中間某個環節。事務在執行過程中發生錯誤,會被回滾(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。
- Consistency 一致性:在事務開始之前和事務結束以後,資料庫的完整性沒有被破壞。這表示寫入的資料必須完全符合所有的預設規則,這包含資料的精確度、串聯性以及後續資料庫可以自發性地完成預定的工作。
- Isolation 隔離性:資料庫允許多個並發事務同時對其數據進行讀寫和修改的能力,隔離性可以防止多個事務並發執行時由於交叉執行而導致數據的不一致。事務隔離分為不同級別,包括讀未提交(Read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(Serializable)。
- Durability 持久性:事務處理結束後,對數據的修改就是永久的,即便系統故障也不會丟失。
透過 Transactions 事務功能,關聯式資料庫可以在多人連線同時執行多個 SQL 句的情況下,也可以保證數據最後的正確性。
5. SQL 語言: DDL
關聯式資料庫使用 SQL(Structured Query Language) 語言,每個 SQL 句子叫做 SQL Query 或 SQL Statement。我們可以用 CLI 指令或 GUI 軟體,用 SQL 語言對資料庫進行查詢和操作。
SQL 分成 DDL 和 DML 兩種,都是用分號 ; 結尾。
Data Definition Language, DDL
如何告訴資料庫去定義 Schema 綱要? 也是使用 SQL 語法,這類型的 SQL 就做 DDL(Data Definition Language)
建立、刪除和更名資料庫
每家方法不太一樣,建議可以用 GUI 進行即可。PostgreSQL 和 MySQL 都是資料庫伺服器,可以管理很多不同資料庫,例如你可以架很多 Rails 網站,但是只需要一個資料庫伺服器,裡面建立不同資料庫即可。
建立資料庫時,請注意選擇編碼(Encoding)。PostgrSQL 可用 utf-8、MySQL 可用 utf8mb4 編碼。
在 SQLite3 的話,直接在 Terminal 用 CLI 指令 sqlite3 your_db_name.db 就會打開(或產生) 一個資料庫檔案。直接砍掉檔案就是刪除資料庫。
MySQL 的話,指令式
mysql -u root -p。PostgreSQL 的指令是psql <database_name>。
以下用 SQLite3 示範。
建立 Table
以下 SQL 會建立 events 表,並新增三個欄位 name, capacity 和 date。預設是欄位允許 NULL,除非加上 NOT NULL。
CREATE TABLE events (name VARCHAR(50) NOT NULL, capacity INTEGER, date DATE);
你可以用 SQLite3 的 GUI DB Browser for SQLite 打開 demo.db 這個檔案:
用 GUI 進行 Schame 操作會比較簡單,在 Rails 的話,則是統一都用 Migrations 機制來變更 Schema。
修改 Table
- 改名 Table,例如
ALTER TABLE persons RENAME TO people; - 新增字串,例如
ALTER TABLE people ADD COLUMN status VARCHAR(50); - 修改和移除欄位:SQLite3 沒支援,需要開一個新 table 然後把資料複製過去
刪除 Table
語法是 DROP TABLE IF EXISTS people;
通常不會讓終端使用者可以動態新建 table 和修改 schema。資料庫的 Schema 比較像是你程式的一部分,我們的代碼會依賴於 Schema 設計。另外也有效能的考量,變更 Schema 是很耗時的操作,特別是數據量已經很多的情況下,修改 Schema 會鎖住整個 Table 影響網站運作。
Migration 機制
資料庫 Schema 不是一成不變的,會隨著軟體變更升級也會有修改的需要。因此,在一些軟體中會實作一種叫做 Migration 的功能,透過 Schema Migration 紀錄目前的 schema 版本。開機的時候檢查目前程式的版本和資料庫裡面的版本是否相同,不同的話,執行 Migration 更新 schema。這些 Migration 代碼也會放進版本控制系統 Git 裡面,這樣整個團隊的開發者和不同伺服器上,都可以利用 Migration 來一致管理 Schema。
這個功能就是大家熟悉的 Rails Migration。
6. SQL 語言: DML
操作數據的 SQL 就是 DML(Data Manipulation Language),也就是做 CRUD 的操作。
新增資料
以下 SQL 會新增數據:
INSERT INTO events (capacity, name) VALUES (200, "JSConf");
這個對應的 Rails 語法是
Event.create( :capacity => 200, :name => "JSConf")
插入多筆 INSERT INTO events (capacity, name) VALUES (300, "COSCUP"), (300, "OSDC.TW");
接下來你也可以在 GUI 的視窗中,練習輸入 SQL 句:
查詢資料
撈全部 events 資料 SELECT * FROM events;
對應的 Rails 語法是
Event.all
只撈出指定的欄位 SELECT name, capacity FROM events;
對應的 Rails 語法是
Event.select(:name, :capacity).all
欄位前段可以補上表的名稱 SELECT events.name, events.capacity FROM events;
遞增排序 SELECT name, capacity FROM events ORDER BY capacity; 或 SELECT name, capacity FROM events ORDER BY capacity ASC;
遞減排序 SELECT name, capacity FROM events ORDER BY capacity DESC;
分頁 SELECT name, capacity FROM events ORDER BY capacity DESC, name ASC LIMIT 20 OFFSET 20;
修改資料
以下 SQL 會修改數據
UPDATE events SET capacity=10; 這會修改 events table 的所有數據把 capacity 改成 10
對應的 Rails 語法是
Event.update_all( :capacity => 10 )
UPDATE events SET capacity=100 WHERE name="RubyConf"; 用 WHERE 可以指定只有修改 name 是 “RubyConf” 的數據
對應的 Rails 語法是
Event.where( :name => "RubyConf" ).update_all( :capacity => 100)
UPDATE events SET capacity=100, name="RubyConf 2015" WHERE name="RubyConf"; 修改 capacity 和 name
對應的 Rails 語法是
Event.where( :name => "RubyConf" ).update_all( :capacity => 100, :name => "RubyConf 2015" )
在 Rails 中,比較常見只修改一筆,例如:
@event = Event.find(123)
@event.update( :capacity => 200)
對應的 SQL 會是
SELECT * FROM events WHERE id = 123;
UPDATE events SET capacity=200 WHERE id=123;
刪除數據數據
以下 SQL 會刪除數據
DELETE FROM events; 會全部刪除
對應的 Rails 語法是
Event.delete_all
DELETE FROM events WHERE name="RubyConf"; 只刪除
對應的 Rails 語法是
Event.where( :name => "RubyConf" ).delete_all
在 Rails 中,比較常見只刪除一筆,例如:
@event = Event.find(123)
@event.destroy
對應的 SQL 會是
SELECT * FROM events WHERE id = 123;
DELETE FROM events WHERE id = 123;
查有哪些 tables 和 columns
各家語法不一樣:
- SQLite3:
.tables和.schema tablename - MySQL:
show tables和describe tablename - PostgreSQL:
\dt和\d tablename
這些查詢在 Rails 啟動的時後,其實也會幫我們做。你可以在 rails console 中對 model 執行 columns 方法,例如 Event.columns 就會反射出這個表有哪些欄位。
條件查詢
以下是一些範例來做條件查詢:
SELECT * FROM events WHERE date = '2015-03-15';- 條件或
SELECT * FROM events WHERE date = '2015-03-15' OR date = '2015-03-16'; - 某個區間
SELECT * FROM events WHERE date BETWEEN '2015-03-15' AND '2015-03-30'; - 條件且
SELECT * FROM events WHERE date = '2015-03-15' AND capacity >= 100; - 模糊比對
SELECT * FROM events WHERE name LIKE '%Ruby%'; - 不可為空
SELECT * FROM events WHERE description IS NOT NULL;
條件比對時,小心大小寫(Case insensitive)不同資料庫預設不同。MySQL 是不分大小寫(case insensitive)、PostgreSQL 會區分大小寫(case sensitive)。
Indexes 索引
WHERE、ORDER 條件欄位最好都要加上資料庫索引(Index),例如範例中的 date 字串,如果沒有索引的話,會是 O(n) 的效率(這裡又叫作 Full Table Scan,需要掃過整個表的意思),資料庫越多數據會越慢。如果有索引的話,會是 O(logn),在數據量大的情況差非常多。
模糊搜尋 LIKE 查詢都會變成 Full Table Scan,沒辦法用資料庫索引,在實戰應用章節中教過的 ransack gem 搜尋是用 LIKE 語法,在幾萬筆數據內效能還能接受,再大的數據量就需要用另外的 Full-Text Searching 引擎了,例如 ElasticSearch。
加索引的 SQL 語法:
- 加索引
CREATE INDEX events_user_id_idx ON events(user_id); - 索引並且值是唯一
CREATE UNIQUE INDEX xxx_idx ON xxx(yyy);
在 Rails Migration 中要加上索引的話,可用 add_index 語法,例如 add_index :events, :date。
將欄位設成 unique 跟設成 unique index 是一樣的
當然也不是所有欄位通通都加上索引就好了,因為加索引會讓寫入數據變慢(因為要建立索引,也會增加儲存空間),但是查詢時會加快。