8. 什麽是 HTTP ?
身為一個 Web 工程師,最需要熟悉的就是應用層的 HTTP 協議了,這是目前最廣為流行的應用層協議。
HTTP 全稱 Hypertext Transfer Protocol(超文本傳輸協議),是由客戶端發送 HTTP Request (請求)到伺服器端,然後伺服器端返回 HTTP Response (回復)。HTTP 一定是先從客戶端開始的,伺服器端不能直接發送信息給客戶端。
什麽是 Hypertext (超文本)呢?意思是擁有超鏈接(一點就跳去另一個網頁)能力的文件。
以下是一個 HTTP Request 的具體長相,當你在瀏覽器輸入 http://ihower.tw 時,瀏覽器就會將以下的信息包進 TCP/IP 封包內,然後透過互聯網傳到伺服器:
GET / HTTP/1.1
Host: ihower.tw
這個 Request 只有 Header,沒有 Payload。
HTTP 伺服器在接收到以上的信息後,會回傳以下的 HTTP Response 給瀏覽器:
HTTP/1.1 200 OK
Content-Type: text/html
<html>
<h1>這是HTML源碼</h1>
<p>....</p>
</html>
這個 Response 的前兩行是 Header,空一行之後是 Payload,也就是 HTML 內容。
豆知識:互聯網(Internet) 和 Web(萬維網) 的技術差別是? 用 TCP/IP 技術的叫做互聯網,用 HTTP 技術的叫做萬維網。萬維網當然也是互聯網的一種,但不是每個互聯網的應用都使用 HTTP 協議,例如 email 郵件系統使用 SMTP 協議。
curl 工具
curl 指令可以在命令行中發送 HTTP Request,示範如下:
curl -v https://ihower.tw
* Rebuilt URL to: https://ihower.tw/
* Trying 104.155.217.243...
* TCP_NODELAY set
* Connected to ihower.tw (104.155.217.243) port 443 (#0)
* TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
* Server certificate: ihower.tw
* Server certificate: COMODO RSA Domain Validation Secure Server CA
* Server certificate: COMODO RSA Certification Authority
> GET / HTTP/1.1
> Host: ihower.tw
> User-Agent: curl/7.51.0
> Accept: */*
< HTTP/1.1 302 Found
< Server: nginx
< Date: Tue, 18 Jul 2017 14:08:22 GMT
< Content-Type: text/html; charset=UTF-8
< Transfer-Encoding: chunked
< Connection: keep-alive
< Location: /blog/
< Strict-Transport-Security: max-age=31536000
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
<!DOCTYPE html>
<html lang="en">
<head>
略
</head>
<body>
略
</body>
</html>
* Curl_http_done: called premature == 0
* Connection #0 to host ihower.tw left intact
其中 > 的部分就是完整的 Request 封包,< 的部分就是完整的 Response 封包。
httpie
要彩色的話,可以用 httpie 工具
可用 brew install httpie 進行安裝
9. 瀏覽器的 HTTP 工具
和 TCP/IP 二進制的 Header 不同,HTTP Header 是肉眼可以閱讀的文字(plain-text),讓我們詳細暸解一下這些 Header 的作用。
瀏覽器 Inspector
使用 Google Chrome 的 Inspector 可以觀察 HTTP Networking 的情形:
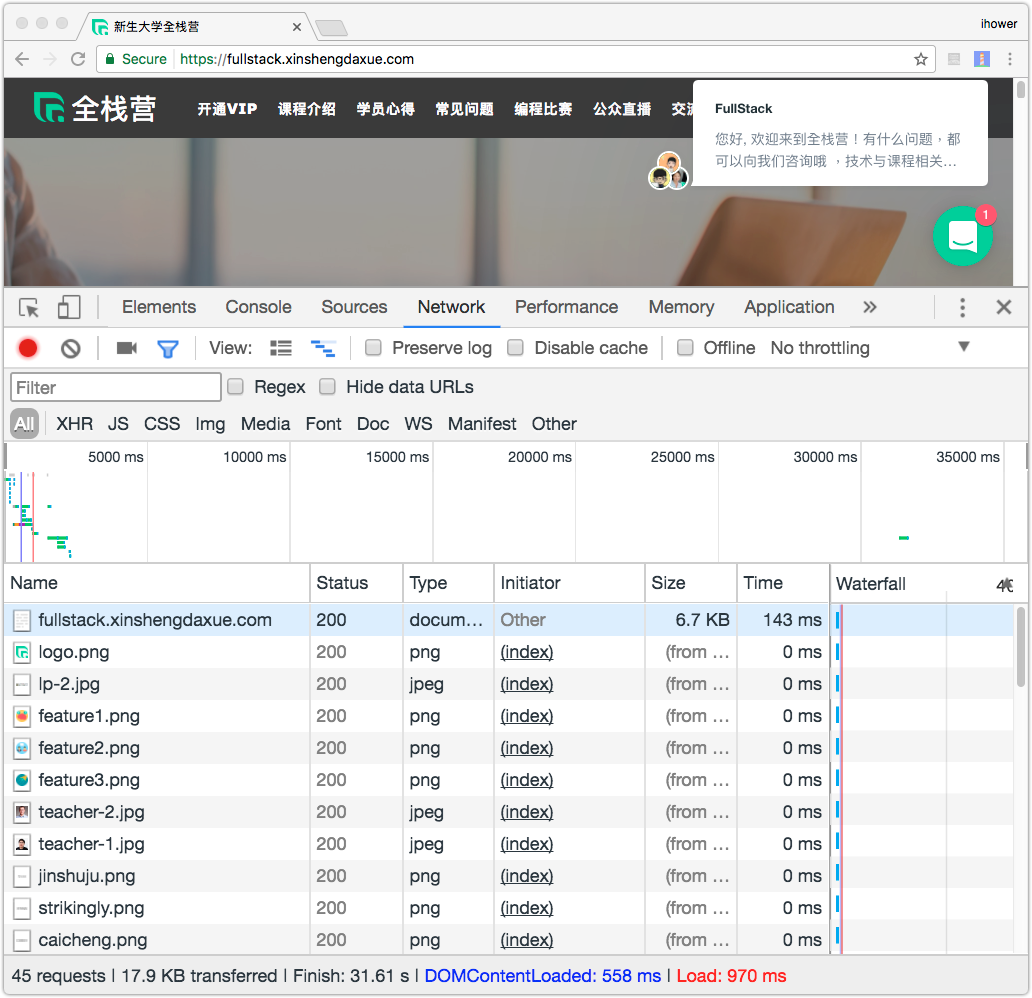
每一行就是一個 HTTP Request,你會發現瀏覽器要完整加載一個網頁(HTML Page Load),必須要發送非常多的 Request。第一個 Request 拿 HTML,接著瀏覽器會解析 HTML 內容,找出還需要哪些 CSS/JavaScript 和圖檔等資源,然後再發送 HTTP Request 去抓取這些資源。
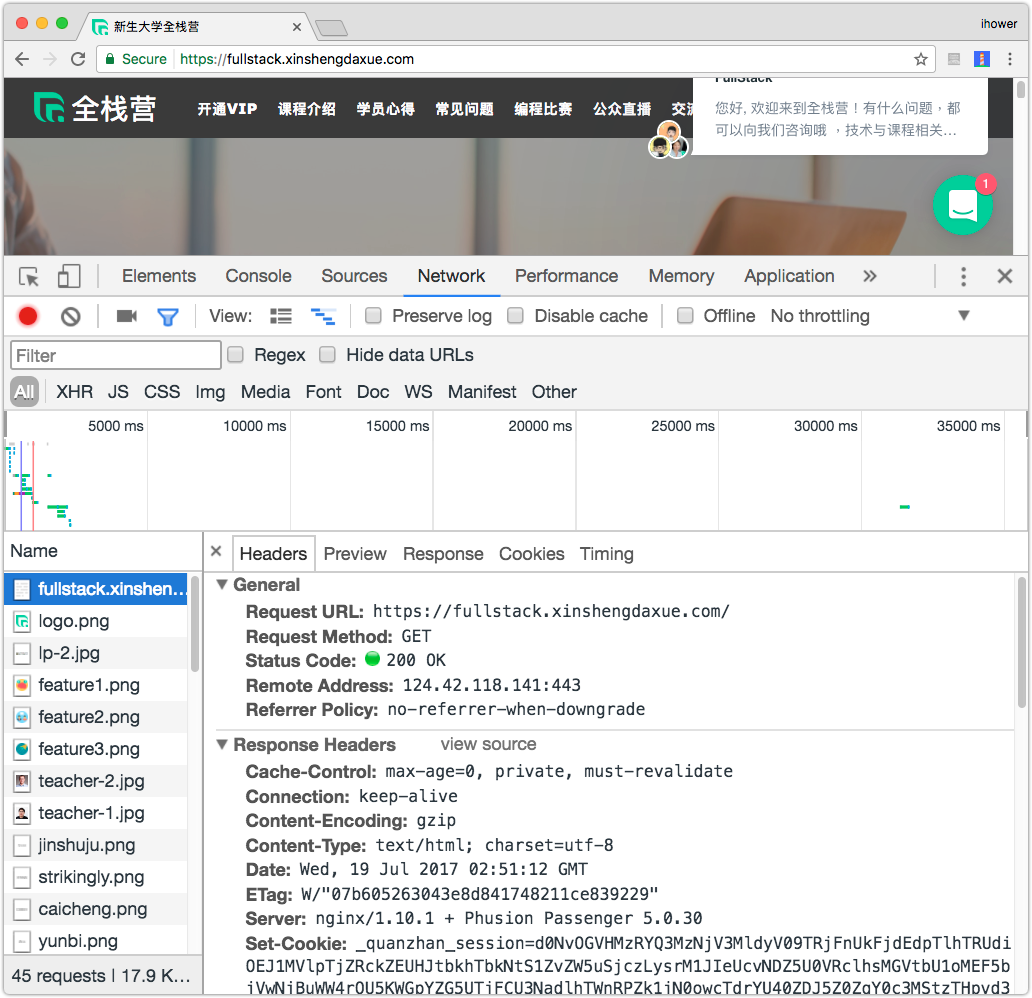
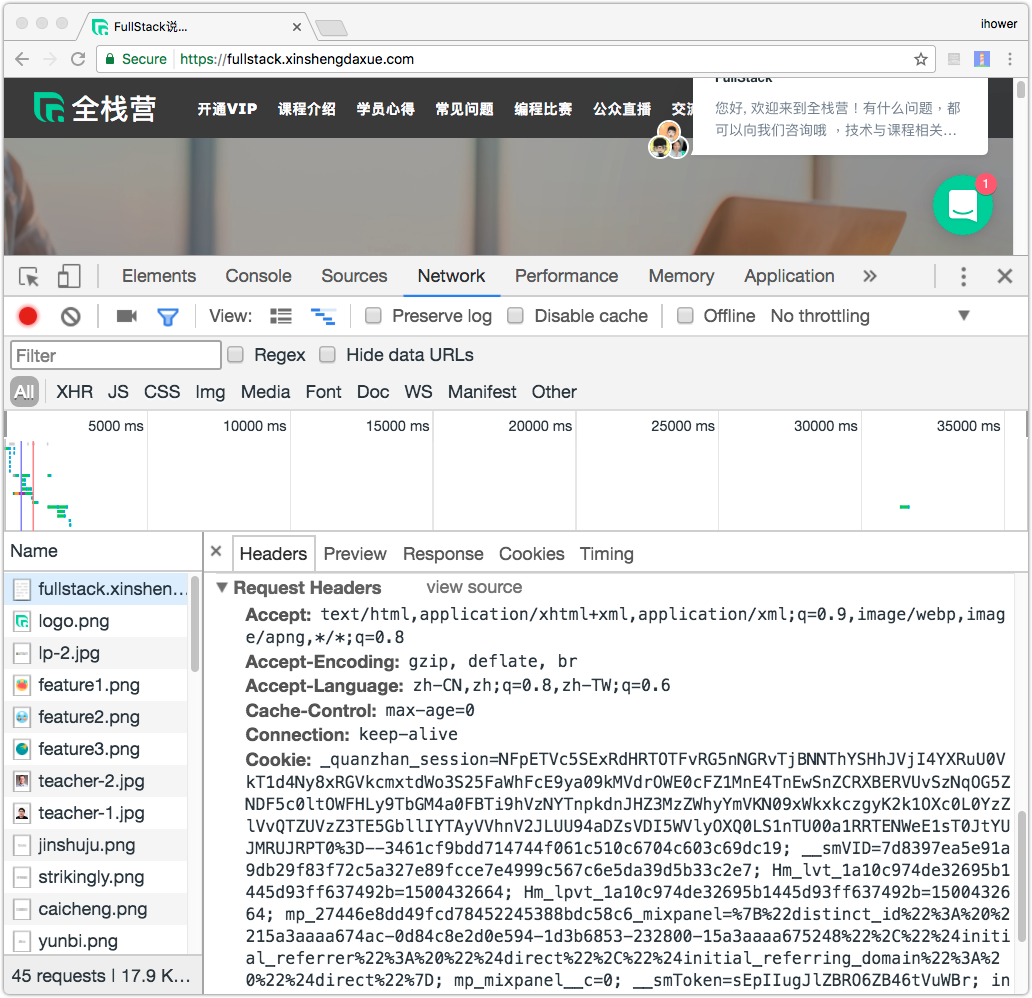
可以進一步觀察每一個 Request 的細節,包括 Request Header 和 Response Header。
瀏覽器 Extension
在 Web API 設計實作教程中,我們有安裝一個 Chrome Extension 叫做 Postman,這就是一個萬用的表單工具,可以讓我們在瀏覽器中發送自定義的 HTTP Request。
首先進入 Chrome 選單上的 Windows > Extensions,然後安裝 Postman:
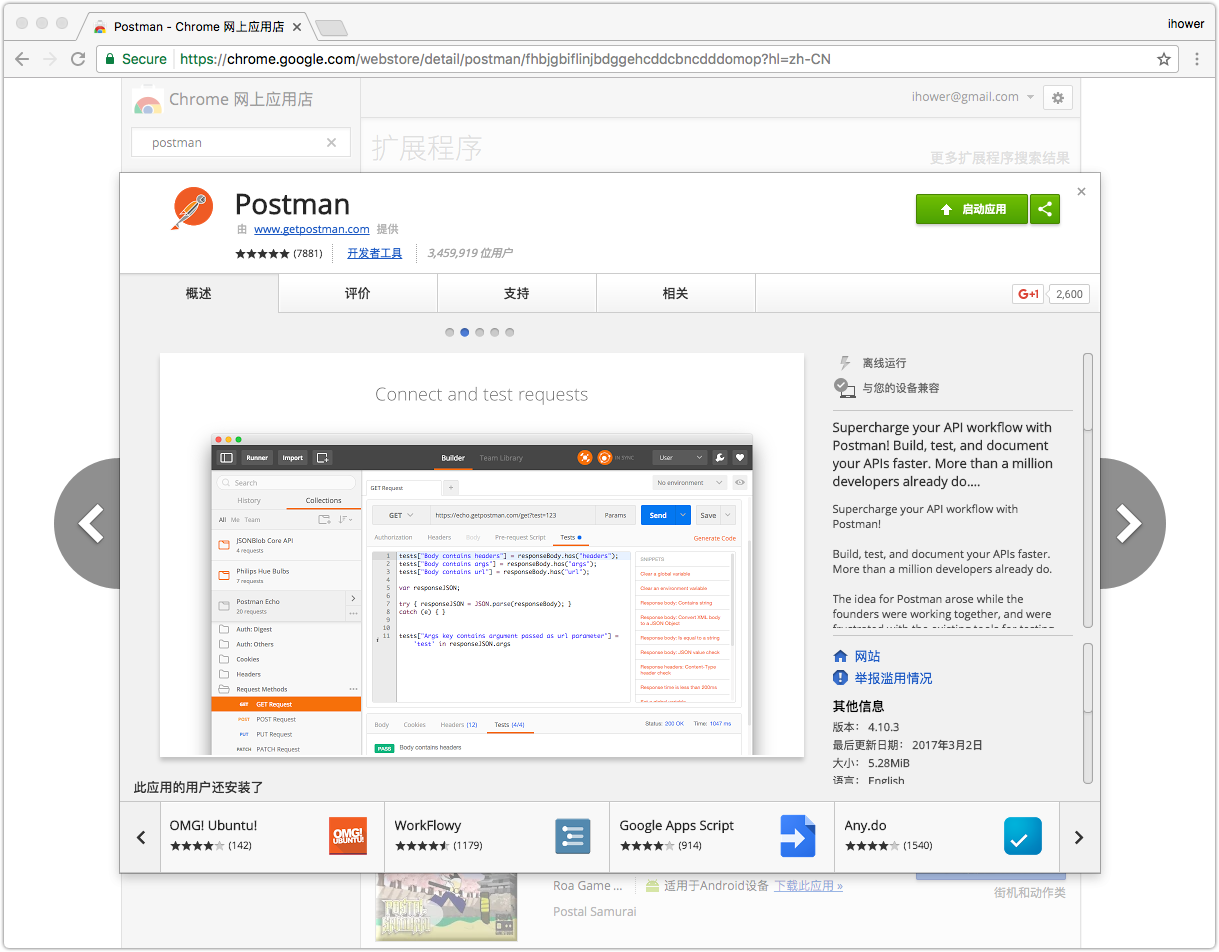
透過這個工具,我們可以指定 URL 地址、HTTP 方法和要傳遞的參數。
10. 認識 HTTP 封包
認識 HTTP Request
一個 HTTP Request 包括幾個成分:
- HTTP 方法(Method)
- 網址,包括 URL + parameters
- HTTP 首部 (Headers)
- 信息內容 (Message Body),GET 方法沒有這個部分
舉例來說
> GET / HTTP/1.1
> Host: ihower.tw
> User-Agent: curl/7.51.0
> Accept: */*
>
其中第一行的第一單字就是 HTTP 方法,第二個單字是網址,第三個單字是 HTTP 的版本,目前通行的版本是 HTTP 1.1
第二行之後是 HTTP Header,是 key: value 的格式,例如 Host 是 ihower.tw。
HTTP 方法
HTTP 方法常見有以下幾種:
- GET: 安全(Safe)且 冪等(Idempotent),用來讀取數據
- POST: 不安全(Non-safe) 且不是冪等(non-idempotent),用來新增數據或執行某個操作
- PUT: 不安全(Non-safe) 但冪等(non-idempotent),用來置換數據
- PATCH: 不安全(Non-safe) 且不是冪等(non-idempotent),用來修改數據
- DELETE: 不安全(Non-safe) 但冪等(non-idempotent),用來刪除數據
在瀏覽器中輸入網址時,會用 GET 方法。網頁中的 a 超連結,會用 GET 跳到下一頁。網頁中的 form 表單,預設是用 POST 送出。在 Ajax 中,我們可以用 JavaScript 自行指定要用哪一種 HTTP 方法。
這裡安全(Safe)的意思是這個操作不會修改到伺服器的數據。但這只是語意上的意思,不代表伺服器的實作。例如 GET 某一個網頁時,伺服器還是可以實做瀏覽量(Page view)功能,每次有人瀏覽就在資料庫加一。但是我們並不會因此就改成用 POST 或 PATCH 方法,因為從用戶的立場來說,瀏覽網頁並不預期會修改或新增數據。
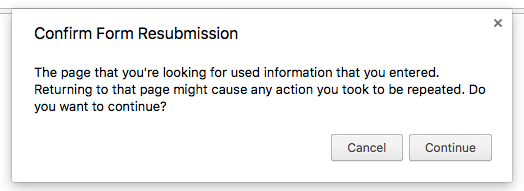
另外,因為互聯網都會假設 GET 是可以重復讀取並快取的,而 POST 不行。因此搜尋引擎只會用 GET 抓資料,像這篇文章就鬧了笑話,這個人用 GET 來刪除資料,造成Google 爬蟲一爬就不小心刪除了,他還以為是 Google 故意駭他…lol 另外,像瀏覽器的表單送出是用POST,如果我們在action 中不redirect (也就是讓瀏覽器去GET 另一頁),而是直接render 返回,那麽如果用戶重新整理畫面的話,瀏覽器會跳出以下的警告視窗,要求用戶確認是否再POST 一次,因為這可能會造成重復操作(重復新增)。如果是 GET 的話,重新整理就不會有這種警告了。
冪等(Idempotent) 的意思是如果相同的操作再執行第二遍第三遍,結果還是跟第一遍的結果一樣 (也就是說不管執行幾次,結果都跟只有執行一次一樣),例如點刪除第二次,或是點第三次,最終結果跟點完第一次是一樣的,那筆數據已經被刪除了。這個特性對支援離線(offline)功能的軟體比較重要,這表示這個操作如果失敗,是可以放心重試(retry)的。不過瀏覽器預設是不支持離線功能的,沒連上網無法瀏覽和操作網站。像桌機或手機軟體才會優先考慮離線的場景。
最後,PUT 和 PATCH 看起來也很像?在 Rails 中 PUT 和 PATCH 的確沒有差別,但根據 HTTP 規格有語意上的差異,詳細可以參考 HTTP Verbs: 談 POST, PUT 和 PATCH 的應用 一文。
Header 首部
常見的 Request Header 例如:
Host: ihower.tw
User-Agent: curl/7.51.0
Accept: */*
- Host 指的是請求的網域名稱。這樣因為同一個 IP 地址的 HTTP 實體伺服器上,可以同時有不同網站。但要如何區分呢?它們的 TCP/IP 首部上的 IP 地址是一樣的數字,抵達伺服器後也用一樣的 Port (HTTP 用80、HTTPS用443),因此一定要用不同的網域名稱來做區分,例如 https://aihao.tw 和 https://uptime.tw 其實是在同一臺主機上,IP 地址是一樣的。但是透過 Host 的不同,HTTP 伺服器就可以區分是要打開那一個網站。
- User-Agent 是用戶使用的軟體,不過由於歷史因素,這些 User Agent 字串都蠻醜的。另外,User-Agent 也不代表客戶端真的是用這個軟體,這是可以自行修改的。
- Accept 指的是希望伺服器回傳的格式。
*/*是都可以的意思,像 Chrome 瀏覽器的 GET 操作預設會用text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,表示第一優先是text/html格式。
HTTP 並沒有規定 Response 一定是什麽格式,所以在 Request Header 會用 Accept 註明希望什麽格式,等等回傳的 Response Header 中也會寫清楚是什麽格式。
如果是 HTML 表單用 POST 送出,瀏覽器則會用 application/x-www-form-urlencoded 或 form-data 格式,詳見 四種常見的 POST 提交數據方式
信息內容 Message Body
GET 沒有信息內容,要用 POST/PATCH/PUT/DELETE 才會有信息內容。另外,也因為瀏覽器的網址(URL)是有長度限制的,所以如果 HTTP Request 要帶很多數據時,就不能用 GET。所以 HTML 表單的送出預設是用 POST。
HTTP Response
一個 Response 包括幾個成分:
- 狀態碼 (Response Status)
- 首部 (Response Headers)
- 信息內容(Response Body)
舉例來說
HTTP/1.1 200 OK
Content-Type: text/html
<html>
<h1>這是HTML源碼</h1>
<p>....</p>
</html>
HTTP/1.1 是 HTTP 規格的版本、第二個單字 200 是 HTTP 狀態碼數字、第三個單字 ‘OK’ 是狀態碼。
隔一行後,就是 Response 的信息內容,這個內容物可以是任何格式,例如 HTML 或 JSON 或是二進制的圖片等等。這個會在 Headers 裡面用 Content-Type 告所我們這是什麽格式。
HTTP Status Code
- 2XX: 成功,例如 200
- 3XX: 轉向,例如 301 (永久轉向)、302 (暫時轉向)
- 4XX: 客戶端的問題: 例如 404
- 5XX: 伺服器的問題: 例如 500
完整的HTTP 狀態碼列表,看起來很多,不過一般不會區分這麽細。對瀏覽器來說 200、301、302 就夠了。很多狀態碼的設計是針對網路設備、設計 Web API 的時候使用,而不是瀏覽器場景。
HTTP Headers
常見的 Request Header 例如:
Content-Type會指名信息內容的格式, Response Body 是沒有限制格式的,例如 HTML 是text/html; charset=UTF-8。在 Web API 教程中用application/json,如果是JPG圖片則會是image/jpeg。完整的內容格式列表請參考MIMELocation搭配 301 或 302 轉向的時候使用。例如當瀏覽器看到 301 狀態碼的時候,就會用Location寫的位址來做轉址,瀏覽器會跳去 Location 指定的網址。如果是你自己寫的客戶端程序,看到 301 或 302 不會自動跳轉的喔。例如輸入curl -v http://ihower.tw,只會告訴你請轉址到https://ihower.tw,但不會自動curl -v https://ihower.tw。Accept-Encoding: gzip, deflate, br這個 Header 告訴瀏覽器信息內容經過壓縮,請解壓縮。現代 HTTP 伺服器都有這樣的功能可以打開,可以大大加速下載速度。
現代瀏覽器支援一些增加安全性的 Header,例如 Strict-Transport-Security、X-Content-Type-Options: nosniff、X-XSS-Protection等等,對網路安全有興趣的請進一步參考:
- HTTP Headers 的資安議題 (1)
- Content-Security-Policy - HTTP Headers 的資安議題 (2)
- HttpOnly - HTTP Headers 的資安議題 (3)
HTTP Header 還有一些是告訴瀏覽器和路由路如何做快取、哪些信息可以快取哪些不行,例如 Cache-Control、ETag 和 Last-Modified 等等,讓瀏覽器可以不需要重復抓取一樣的內容。有興趣的請進一步參考 HTTP Caching。在正式的部署中,我們也會設定靜態檔案(CSS/JavaScript/圖檔等)可以快取,告訴瀏覽器可以放心地快取這些靜態檔案,這也是因為 Rails 的 Asset Pipeline 會將靜態檔案的檔名修改成根據內容加上 digest 編碼,因此只要靜態檔案內容有修改,檔名就會變更。那瀏覽器就會重新下載到最新的檔案,而不怕繼續用舊的快取盤案。
HTTP 的無狀態(Stateless)特性,以及用 Cookie 做狀態管理
在 HTTP 的設計中,每個 Requests 之間都是完全獨立的(和前後 Request 相比),也就是說每個 Request 必須帶有完整的參數來完成操作。
那要如何識別登入的用戶呢? 每個 Request 都要自帶可以識別的資訊,例如瀏覽器會使用 Cookies 這個功能。伺服器透過 Response Header 的 Set-Cookie 來告訴瀏覽器要記住一些數據,然後瀏覽器就會在之後的 Request 都帶有 Cookie 這個 Header。
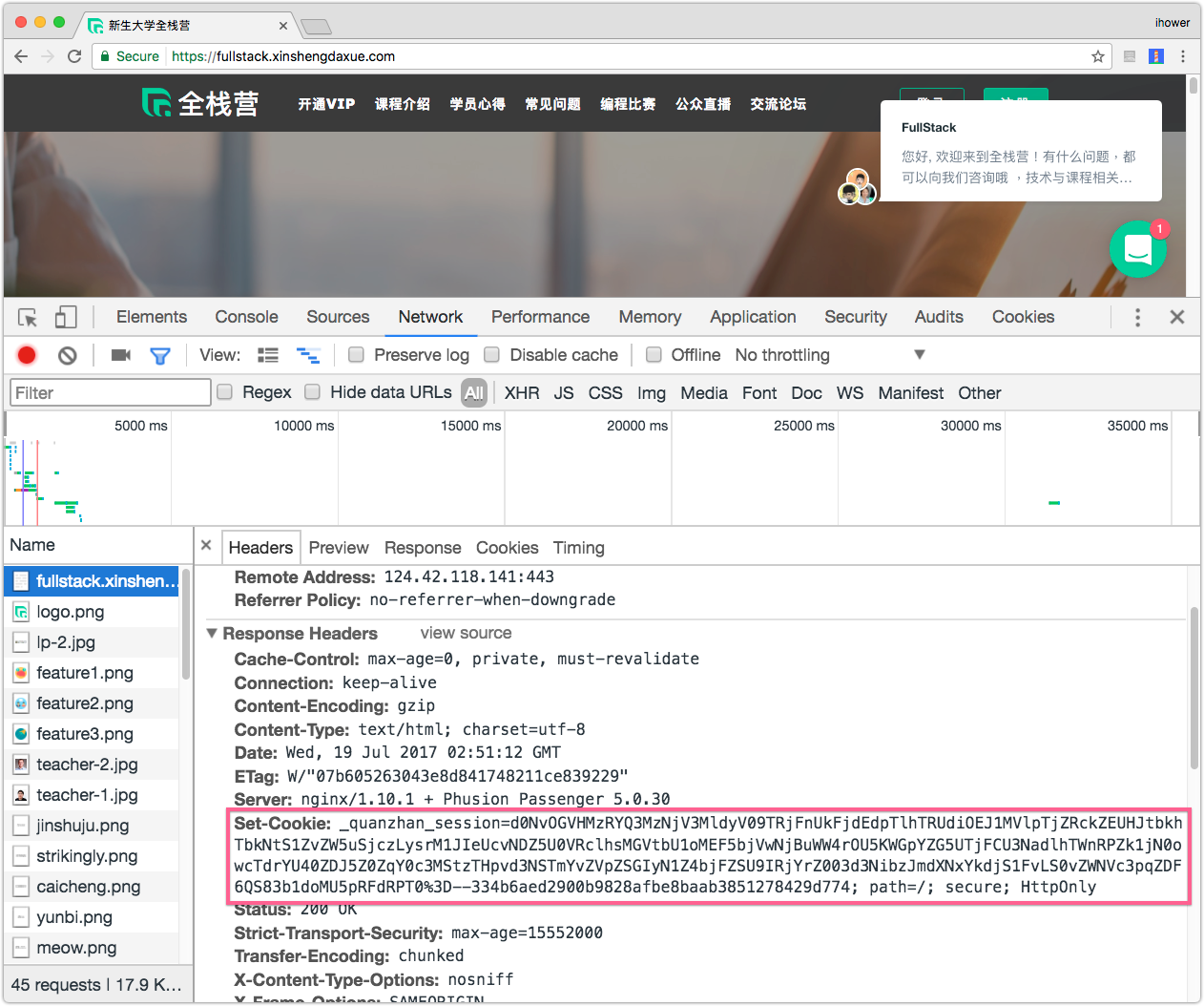
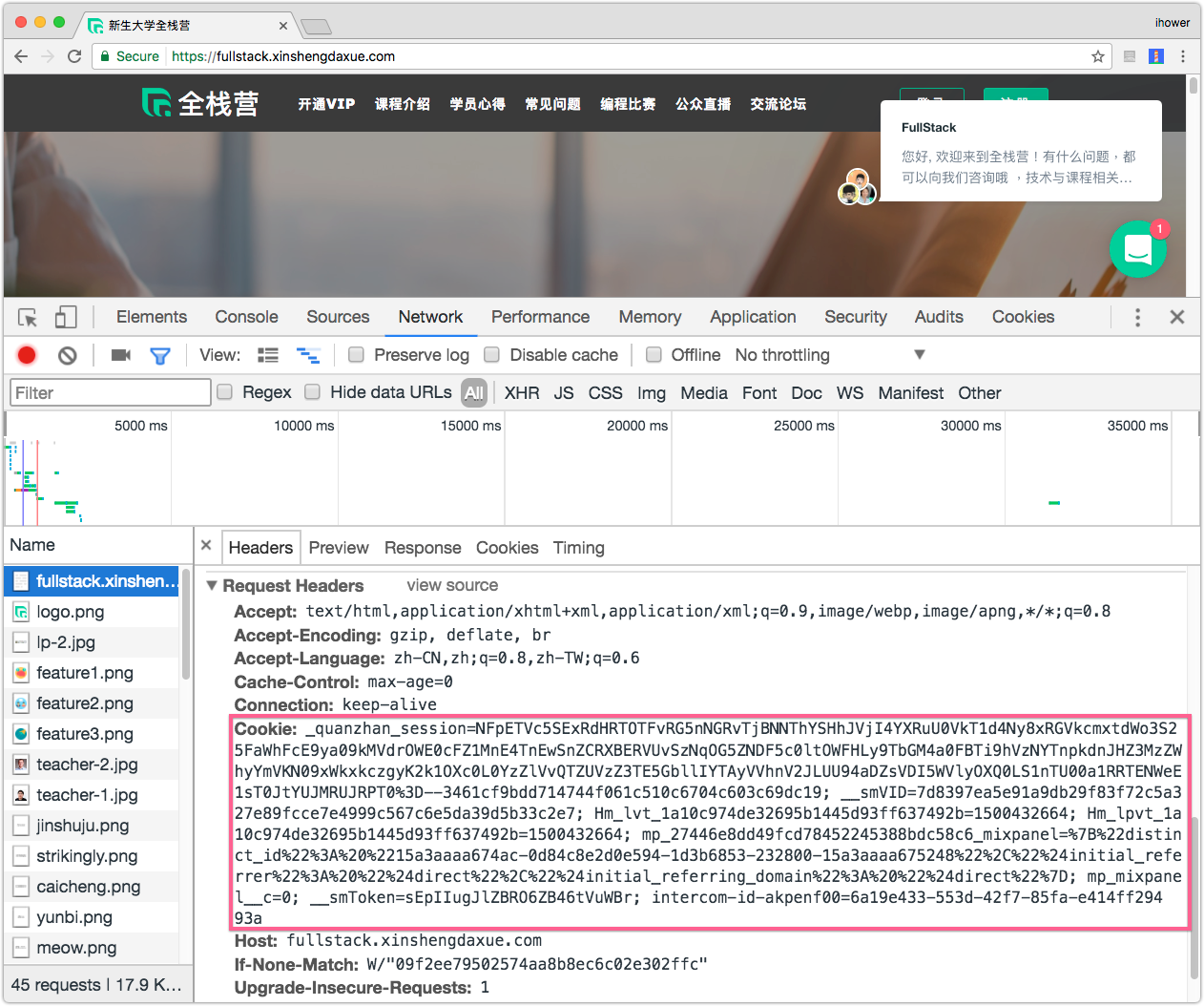
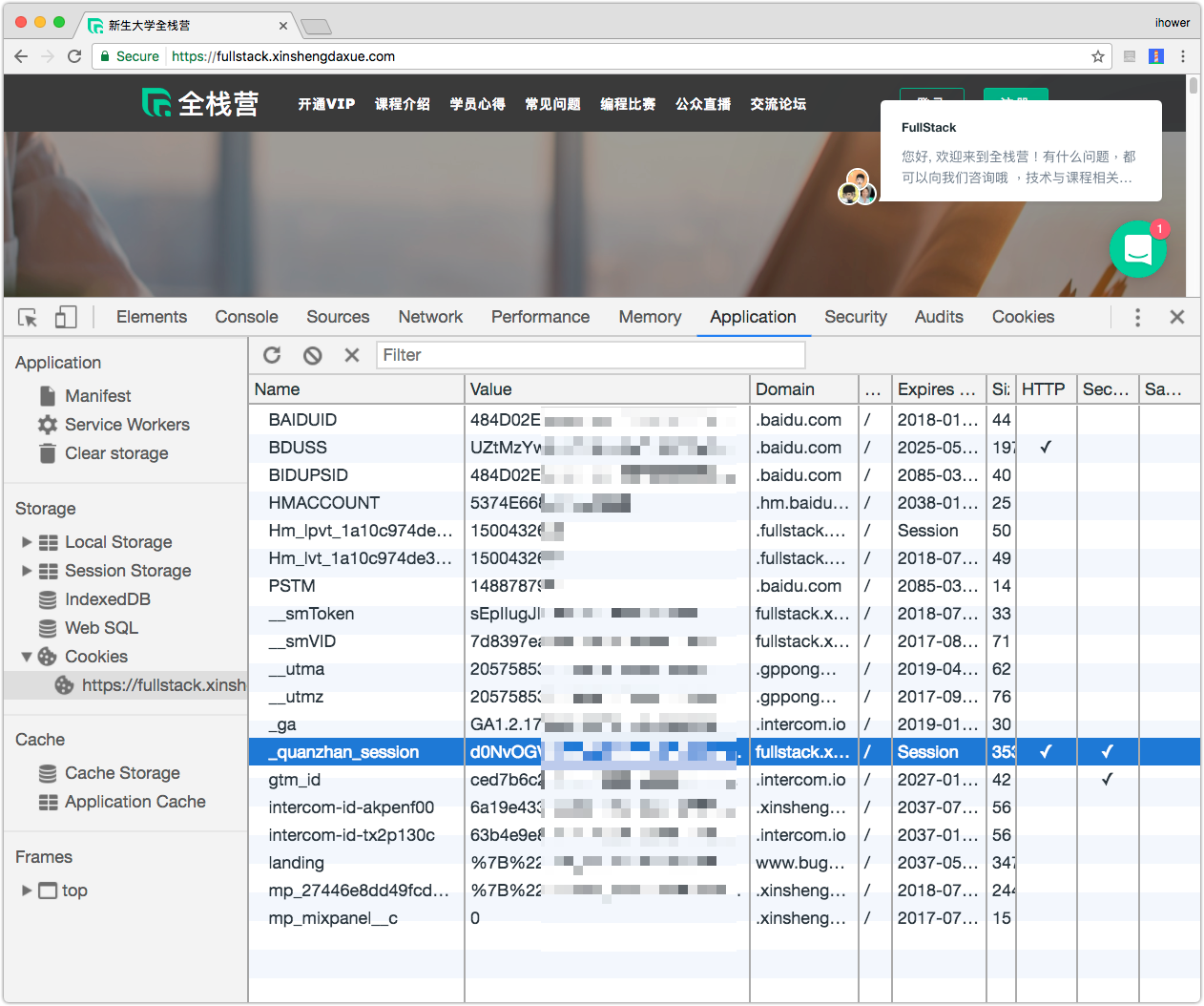
另外,Cookie 只會向同一個網域送出,這是瀏覽器的安全同源政策 Same-origin policy,例如在 www.tenlong.com.tw 設定的 Cookie,瀏覽器只會向 www.tenlong.com.tw 送回 Cookie。
畫面中還有看到 baidu 和 intercom 的 Cookie,這是因為網頁上有安裝 百度統計 來統計用戶流量,以及 Intercom 來做即時線上客服。這兩個是 JavaScript 插件放在 HTML 上的,你可以在網頁上放其他網域的 JavaScript/CSS或圖片。
11. 什麽是 URL
讓我們進一步瞭解瀏覽器中的「網址 URL(Uniform Resource Locator)」是什麽:
以 http://www.example.com/home 舉例:
- 協議用 http
- 伺服器主機(Host)是
www.example.com - URL 路徑(path)是
/home - Port 號碼: http 預設是 80,https 預設是 443。這可以自訂例如
http://www.example.com:3000
什麽是 Query Strings/Parameters? 可以用來額外傳遞一些參數給伺服器,例如 http://www.example.com?search=ruby&results=10,其中:
?是保留符號,query string 的開頭&是保留符號,分隔 Parameter Name/Value,例如 search=ruby 和 results=10- GET 或 POST 都可以用 Query Strings 的寫法來傳遞參數,但 GET 比較常見,因為 GET Request 也只能用這種方式傳參數給伺服器 (GET 沒有 body)
但是用 Query String 有一些限制:
- Query strings 有長度限制 (因為整個 URL 長度有限制,太長會被截掉),因此如果參數真的很多,有時候就算是查詢,也會改用 POST 做(例如進階查詢功能,參數多到 GET 的網址放不下)
- 不適合傳敏感信息,例如帳號密碼或信用卡號碼等等,因為放網址太明顯了,用戶甚至可以加入書籤等等。
- 空白和特殊字符必須做逸出編碼(encoded)
當作網址的參數都必須要經過編碼,這有一套規則 URL Encoding ),例如:
- 空白變成
%20 !變成%21+變成%2B#變成%23- 其他還有
/?:@&等等
這就是為什麽有時候網址列很長又很醜的原因。中文字也需要經過編碼 (但現代瀏覽器會自動做轉換,所以中文字看起來可以使用,但只是因為瀏覽器幫忙編碼處理了)。
12. 什麽是 HTTPS 和 HTTP/2
HTTPS
近年來由於上網安全意識的提升,越來越多的網站使用 HTTPS 加密連線,網址像這樣:
沒有加密的 HTTP 連線,可以透過監聽網路封包,就可以知道瀏覽器傳輸的內容。例如在咖啡廳上網,駭客可以透過監聽無線網路,看到你上網的一舉一動。有些咖啡廳可以在網頁中置入廣告 Banner,就是因為連線是走 HTTP 未加密的關系,所以很容易就可以修改網頁內容。
在 Rails 網站安全教程中,我們會介紹這個加密的原理
詳細也可以先參考以下文章:
HTTP/2
HTTP/2 是 2015 年制定的最新 HTTP 標準,語意和功能都與 HTTP 1.1 是相容的,主要是改善加載網頁的效能,詳細請參考老師之前寫的一篇文章 更快更安全: 每個網站都應該升級到 HTTP/2。
13. 總結瀏覽器的 Request/Response Lifecycle
好,讓我們總結復盤一下教程一開始的問題:當我們在瀏覽器輸入一個網址到顯示出網頁,背後發生的事情:
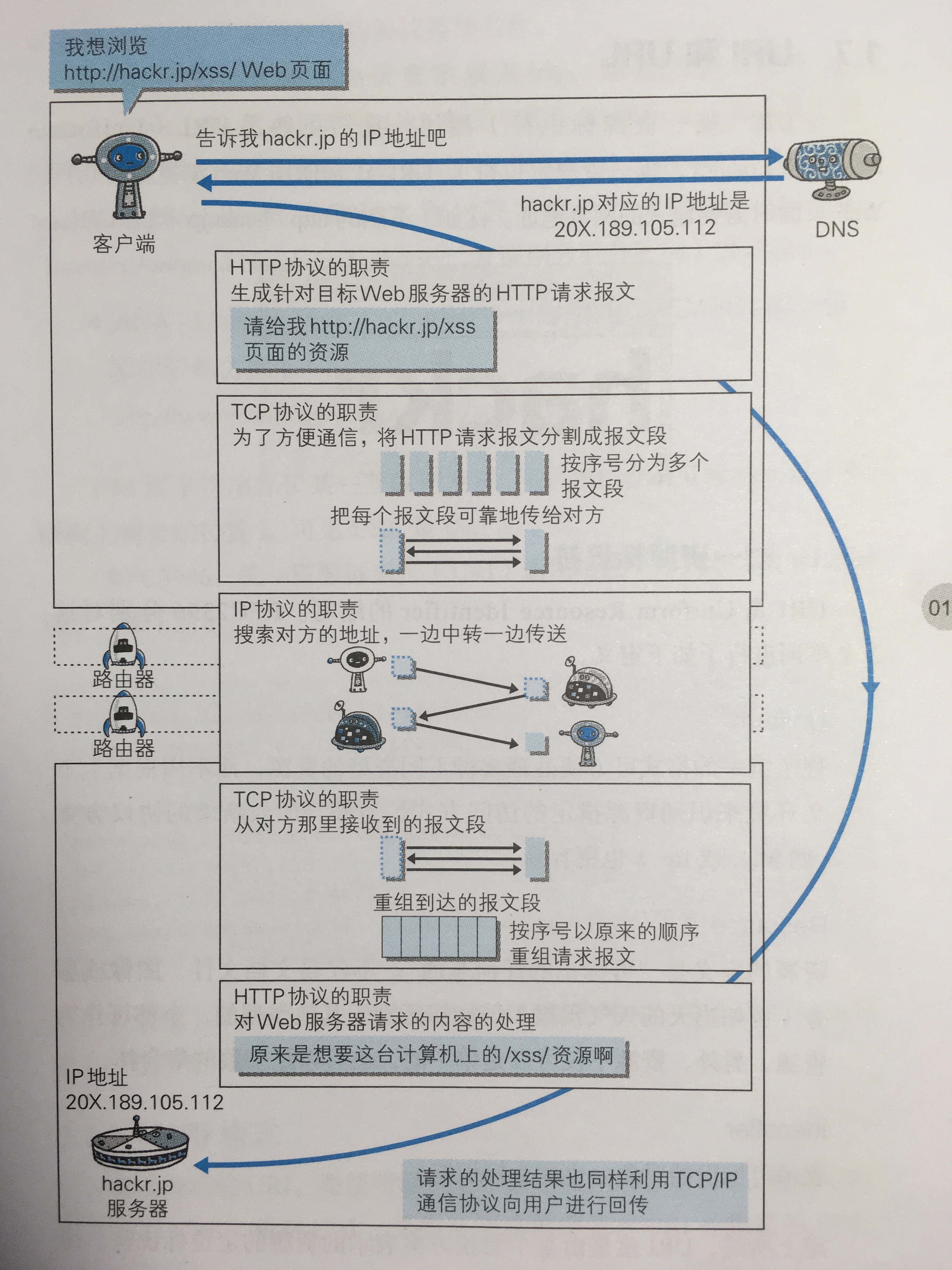
(圖片取自圖解 HTTP, 人民郵電一書)
文字版說明:
- 在網址列輸入網址,或是點網頁上的超連結
- 瀏覽器解析這個 URL 找出 protocol、host、port 和 path
- 如果是 HTTP,則組出 HTTP request 封包
- 查詢 DNS 用 host 找出對應的 IP 位址,組出 IP 封包
- 組出 TCP 封包並打開一個 TCP connection 到上述 IP 位址和 Port
- 送出 HTTP Request 封包
- Web 伺服器(例如 Nginx)接收到 HTTP Request 封包後,解析其中的內容(特別是其中的 path)來決定如何回應:
- 如果是靜態內容,也就是 HTTP Response 不會根據不同用戶、不同時間等任何因素而改變,例如圖片、影片、CSS、JavaScript 等等。那麽 Web 伺服器會直接將該檔案回傳給瀏覽器。
- 如果是動態內容,也就是會根據不同登入的使用者、時間等參數來回傳不同內容,那個 Nginx 會將 HTTP Request 交給應用程序處理,例如 PHP、Ruby、Python、Node.js、Java 等程序,由該程序動態地根據不同參數和條件,搭配資料庫來撈取資料,然後組合出 HTML 網頁包成 HTTP Response 經由 Nginx 回傳給瀏覽器。
- 瀏覽器接收到這個 HTTP Response,開始解析這份 HTML 網頁成為 Document Object Model (DOM) 一種樹狀的資料結構來對應 HTML 的標籤節點。
- 瀏覽器會依序檢查 HTML 原始碼中,需要下載的資源網址 URL,例如 CSS、圖片、JavaScript 等等,就會再發 HTTP Request 請求下載回來 (依照上述步驟二到九)
- 如果下載到 CSS 樣式表,就會去裝飾對應的 DOM 節點
- 如果下載到 JavaScript 程序碼,則會執行它。瀏覽器上的 JavaScript 程序可以操作 DOM 節點,通常會用 jQuery 函式庫來做,來達到一些網頁動態特效。
- 直到所有資源都下載完畢,瀏覽器執行完 CSS 和 JavaScript,才算大功告成完成(Page Load)。如果你又點擊網頁上的超連結,則又回到步驟一。
14. 推薦閱讀
網路時代每一個軟體都需要連網功能。身為一個軟體工程師,多瞭解網路原理的話,對於網路相關問題的設定和故障排查,會有很大的幫助。這份教程文字有點多,建議你還可以搭配以下閱讀資料,多方理解:
- DNS 原理入門
- HTTP 協議入門
- 你應該知道的HTTP基礎知識
- 網路協議——寫給每個懂點編程的同學
- 圖解 HTTP, 人民郵電出版社
- 網路是怎樣連接的, 人民郵電出版社
- Introduction to HTTP
- 圖解 HTTP, 人民郵電出版社
- Coursera Startup Engineering