程式語言的設計
7. 數據類型 Data Type: 基本數據類型
在高階語言中,每個值都屬於一種數據類型,這些數據類型可以概分為兩種:基本數據類型和組合數據類型
為什麽程式語言需要設計數據類型? 因為同樣是 2 bytes 的資料,如果不知道是什麽類型的話,那我們就無從得那 16 bits 的二進制數字代表的意義,可能是字串、也可以是數字。
Data Type 基本數據類型(Primitive Data Type)
基本數據類型包括 String 字串、Integer 整數、Float 浮點數、Boolean 布林、nil 空值等。
String 字串
在程式語言內部,字串就是一個一個字符,用陣列串起來實作的。讓我定義一下什麽是字符:一個英文字母是一個字符、一個中文漢字是字符、一個符號也是一個字符。
但是電腦存儲的是二進制,需要透過編碼(Encoding)才能讓人給這些二進制意義,透過字符集對照表,告訴我們這個二進制編碼對應的字符是哪一個。
最早的字符集是 1967 年美國人發明的 ASCII (American Standard Code for Information Interchange) 美國信息交換標準代碼,用一個 1 byte 的空間,來儲存可顯示的英文字母和符號,以及不可見的控制字符,例如:
二進制 0100 0001,十進制 65,這個編碼代表 A 二進制 0100 0010,十進制 66,這個編碼代表 B … 二進制 0110 0001,十進制 97,這個編碼代表 a …
不過,1 byte 的空間,至多也就是 256 種字符而已,對於非英語系國家是絕對不夠用了。於是各個國家自定義了各自語言的字符集,例如:
這些語言的字符集,使用了 2 bytes 的空間,至多可以容納 65526 種字符,看起來似乎是足夠的。
不過,相信大家可能都碰過亂碼問題,打開一份文件或是網頁,發現都是無意義的字符,這就是因為使用了錯誤的字符集去顯示,解決辦法就是重新選過 Text Encoding 挑到正確的字符集,文字才能正確顯示。
另外,如果想要同一份文件同時顯示漢字、日文、韓文、越南文等等,就沒有一種字符集可以滿足需求耶?
所幸,我們目前使用的業界標準,是 1991 年開始發展的 Unicode 萬國碼,這個計劃定義了全世界所有語言的編碼。在這個計劃下,定義了幾個字符集標準:
- UTF-32 用 4 bytes 來存一個字符
- UTF-16 用 2 或 4 bytes,漢字會是 4 bytes
- UTF-8 用不定長度 1~4 bytes,一個英文字母用 1 byte 存儲,一個漢字會用 3 bytes 存儲
其中 UTF-32 很少使用,因為太浪費空間了。本來一個英文字母用 1 byte 就可以存,改成用 4 bytes 後,前面三個 bytes 都是 0,耗費的空間變成四倍。
蠻多程式語言內部是用 UTF-16 時做字串的,例如 Java 和 Python。
至於 UTF-8 則是目前最為通行的標準,既能表示所有語言,空間上又比較節省。因此廣泛應用在 HTML 和各種文件上。在 Rails 預設產生的網頁,也都是使用 UTF-8 標準。另外,ASCII 剛好是 UTF-8 的子集,有著良好的向後相容性。
關於編碼,可以再參考看看這篇文章 字符,字符集,字符編碼
Ruby 對於各種字符集的支援非常好,每個字串,都屬於一種字符集,預設是 UTF-8:
讓我們執行 irb 實驗看看:
"a".encoding # 得到 <Encoding:UTF-8>
"a".size # 這是 1 個字符
"a".bytesize # 這是1個 bytes
"中".encoding # 得到 <Encoding:UTF-8>
"中".size # 這是 1 個字符
"中".bytesize # 這是3 個 bytes
Ruby 內建支援了 101 種字符集。執行
Encoding.list.map{ |x| x.name }
=> ["ASCII-8BIT", "UTF-8", "US-ASCII", "UTF-16BE", "UTF-16LE", "UTF-32BE", "UTF-32LE", "UTF-16", "UTF-32", "UTF8-MAC", "EUC-JP", "Windows-31J", "Big5", "Big5-HKSCS", "Big5-UAO", "CP949", "Emacs-Mule", "EUC-KR", "EUC-TW", "GB2312", "GB18030", "GBK", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-10", "ISO-8859-11", "ISO-8859-13", "ISO-8859-14", "ISO-8859-15", "ISO-8859-16", "KOI8-R", "KOI8-U", "Shift_JIS", "Windows-1250", "Windows-1251", "Windows-1252", "IBM437", "IBM737", "IBM775", "CP850", "IBM852", "CP852", "IBM855", "CP855", "IBM857", "IBM860", "IBM861", "IBM862", "IBM863", "IBM864", "IBM865", "IBM866", "IBM869", "Windows-1258", "GB1988", "macCentEuro", "macCroatian", "macCyrillic", "macGreek", "macIceland", "macRoman", "macRomania", "macThai", "macTurkish", "macUkraine", "CP950", "CP951", "IBM037", "stateless-ISO-2022-JP", "eucJP-ms", "CP51932", "EUC-JIS-2004", "GB12345", "ISO-2022-JP", "ISO-2022-JP-2", "CP50220", "CP50221", "Windows-1256", "Windows-1253", "Windows-1255", "Windows-1254", "TIS-620", "Windows-874", "Windows-1257", "MacJapanese", "UTF-7", "UTF8-DoCoMo", "SJIS-DoCoMo", "UTF8-KDDI", "SJIS-KDDI", "ISO-2022-JP-KDDI", "stateless-ISO-2022-JP-KDDI", "UTF8-SoftBank", "SJIS-SoftBank"]teless-ISO-2022-JP-KDDI (autoload)>, #<Encoding:UTF8-SoftBank>, #<Encoding:SJIS-SoftBank (autoload)>]
你可以用 encode 轉換編碼到不同字符集:
"中".encode("GB2312") # 得到 "\x{D6D0}" 終端機預設用 UTF-8,因此無法順利顯示 GB2312。\x 是16進制的意思
"中".encode("GB2312").bytesize # 得到 2 bytes
"中".encode("ASCII") # 這樣會報錯 Encoding::UndefinedConversionError: U+4E2D from UTF-8 to US-ASCII 因為漢字無法轉成用 ASCII 存儲
以及用 force_encode 換字符集但不轉換編碼:
"\xD6\xD0".encoding # 因為預設是 UTF-8
"\xD6\xD0".force_encoding("GB2312").encode("utf-8") # 編碼不變,但是告訴 Ruby 說這個是 GB2312,然後再轉回 UTF-8
在 Ruby 之中,預設讀取寫入資料都是用 UTF-8 編碼,但是如果要串接其他系統或資料,就需要知道字符集的知識。例如資料庫要記得用 UTF-8,抓比較舊的外部文件或網頁,如果不是 UTF-8 編碼的話,那就必須處理轉碼問題。
Symbol
Symbol 是 Ruby 語言特有的類型,作用跟字串很像,但是是唯一且不會變動的識別名稱,用冒號 : 開頭,例如 :this_is_a_symbol
為什麽不用字串呢?這是使用 Symbol 執行效能比較好。在 Ruby 語言內部,相同名稱的 Symbol 不會再重復建構、Symbol 本身的方法也比 String 少很多、你也不能修改 Symbol。讓我們進 irb 實驗看看:
puts "foobar".object_id # 輸出 2151854740
puts "foobar".object_id # 輸出 2151830100
puts :foobar.object_id # 輸出 577768
puts :foobar.object_id # 輸出 577768
object_id方法會回傳 Ruby 內部的記憶體位址編號。你會發現兩個字串就算內容相同,也是不同的位址。但是 Symbol 只要內容相同,就是相同位址。這種特性讓 Symbol 的主要用途是作為雜湊 Hash 的鍵(Key)。
Number 數值類型
整數 Integer
電腦內部是用補碼的方式來存儲整數,一個 byte 的空間可以表示 -128~127 之間的數字。在 C 語言中,需要先宣告你要使用多大的數字,例如 short 是 2 bytes,只可以存 -32768 - 32767 之間的整數,int 是 -2^31 - (2^31-1) 之間的整數。
在動態語言例如 Ruby 中不需要先宣告,Ruby 會自動調控使用多少 bytes 來存整數。
在靜態語言中,需要先宣告需要用多大空間的整數,在編譯的時候就會在記憶體中預留空間 (所以執行起來比 Ruby 快啊)。
Float 浮點數
如果要做科學運算、數值分析,會有很多除不盡的小數情況,這時候就會用浮點數 Float,可以表示任意長度的實數。
以 IEEE 單精度浮點數標準 為例,32位元,第一個位元是正負號、8個位元存指數,後23個位元存有效位數,透過2的指數來計算,如此就可以表示非常非常大和非常非常小的數字。
但是符點數有個最大的缺點就是輸入與儲存的值不一定精確、計算後的結果可能會有微小誤差(因為無法剛好用 2 的指數來表示,只能逼近)
舉例來說,0.1 + 0.2 是不等於 0.3 的,你可以進 irb 實驗看看
0.1 + 0.2 # 得到 0.30000000000000004
0.1 + 0.2 == 0.3 # 得到 false
在 JavaScript 語言中,所有數值都是浮點數。
Decimal 十進制數
如果需要小數點,又希望絕對的精確,這時候會用 Decimal 型態,設定整數部分和小數部分的要用多少位數,可以精準表示
在 Ruby 內可以用 BigDecimal
不過,真正重要的其實是資料庫,在 Rails migration 中,如果你要存有小數點的資料,可以用 float 或 decimal 是都可以。但是如果情境是 GPS 定位、匯率等等,已知小數長度是固定的話,這時間建議用 decimal 會比較準確。
例如在 Rails migration 中,最好用 deciaml 而不是 float 來存匯率或經緯度:
# 總共六位數,小位數三位
t.decimal "currency_rate", precision: 6, scale: 3
不然可以你輸入某個經度緯度,存進資料庫再拿出來,可能會差小數碼一些些,但對 GPS 來說可能就差好幾公尺了。
8. 組合數據類型 (Reference/Object Data Types)
組合數據類型,包括 Array、Hash 和程序員自訂的復合資料類型(也就是 Class),這種類型的數據是一種容器,裡面可以放上述的基本數據類型,或是組合其他的組合數據類型。
Array 有序容器,用整數當作索引
在編程基礎中各位應該已經熟悉 Array 的使用,在記憶體裡面,Array 就是用一塊連續的存儲空間。
|1|2|3|4|5|6|7|8|
每個陣列元素,在記憶體裡面的大小是固定的。透過索引,我們可以很快就可計算出該元素在記憶體中的位置。
例如假設每個元素佔 4 bytes,arr[0] 在記憶體位置 100,那 arr[3] 就是 100 + 4*3 在位置 112 了。
Hash Table 雜湊表 (或稱作 Map 或 Dictionary)
一種 Key-Value 的容器,通常用 Symbol 或字串當作索引,要瞭解雜湊 Hash 的原理,需要先知道什麽是雜湊函數。
雜湊函數是一種能將數據變成摘要(digest)的算法,執行 irb,然後輸入以下代碼實驗看看:
require 'digest'
Digest::SHA1.hexdigest '12345678'
得到 "7c222fb2927d828af22f592134e8932480637c0d"
雜湊函數有一些很好的特性:1. 相同的數據,每次都會得到一樣的摘要 2. 即使只有微小差異的內容,摘要也會差異很多,非常分散。
因此,我們將雜湊的 key 丟進這個雜湊函數,得到一組摘要。然後用這個摘要的前幾碼,來把 value 放到記憶體中對應的位置。
例如我們可以設計一個有 26*26 個空間的容器(在記憶體中佔用 26 * 26 * 4 bytes空間),給予編號 aa 到 zz。然後取 key 摘要的前兩碼,把 value 放到那個位置:
|aa|ab|ac|ad|.....|zx|zy|zz|
假設初始位置是 100,如果給一個 key 算出來的雜湊值是 ad,那我們就把值放在 100 + 4*3 在位置 112。
這樣設計的好處是,隨便給一個 key,都可以馬上算出它在記憶體中的位置,非常有效率。
因為只取前幾碼,當然有可能不同的 key 會放在同一個位置。內部實作根據這種情況,會再處理沖突,詳見雜湊表。
組合數據的修改
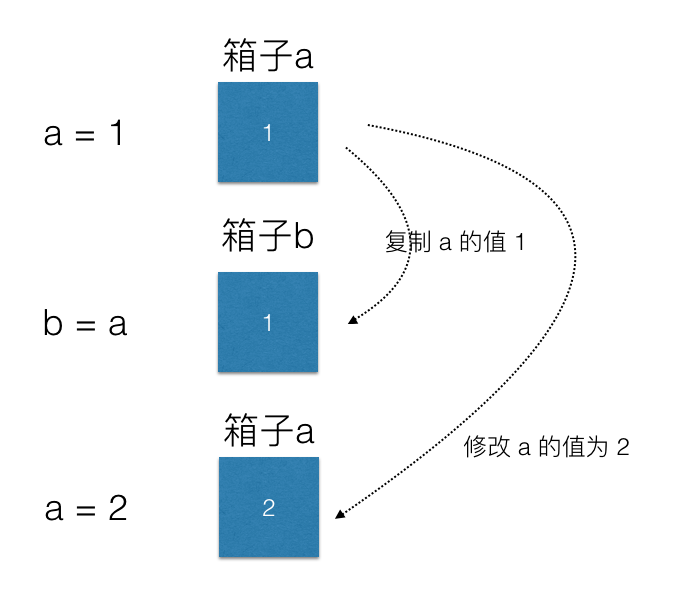
辨識哪些是引用數據類型,是很重要的基本概念,例如
a = 1
b = a
a = 2
請問最後 b 是多少? a 是多少? 這題沒坑,a 就是 2,b 就是 1。 a, b 兩個變數分別佔了記憶體的兩塊空間,當 b = a 時,b 記憶體就被填成當時 a 的值是 1。
同樣的邏輯,讓我們換成 array:
a = [1,2,3]
b = a
a[0] = 9
請問最後 a, b 陣列長怎樣?
令初學者感到意外的是,a 和 b 最後都是 [9,2,3],兩個陣列變數都被修改到了!
這是因為在記憶體裡面,組合數據類型的變數,並不是直接存它的值,而是存一個引用位址(reference),指向另一塊真正存值的記憶體空間。
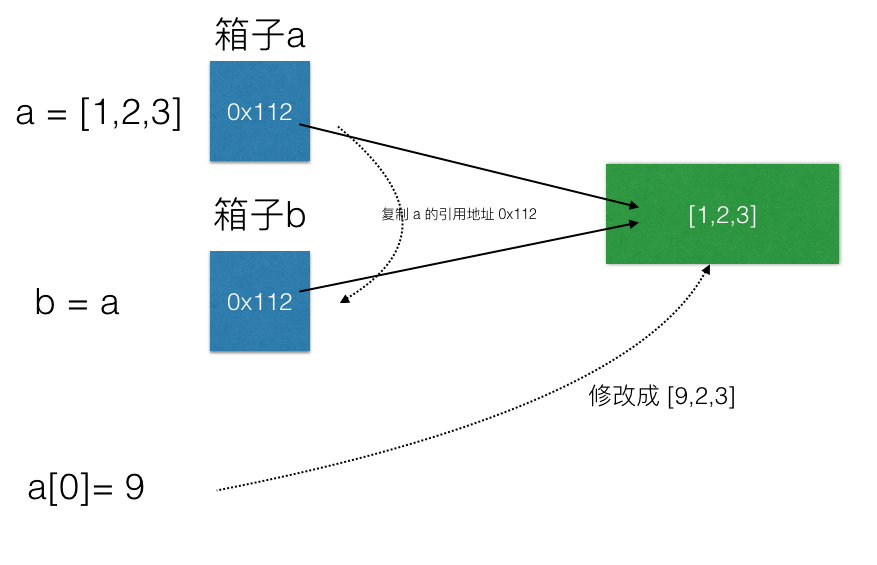
因此當 b=a 時,複製的是引用位址(reference),指向同一塊存有 [1,2,3] 的記憶體空間。當最後 a[0] 時,就會改到同一份數據。
為什麽程式語言會這樣設計呢?這是因為組合數據類型是個容器,這個容器可能存有非常多的數據,複製的成本是很高的。因此在預設的情況下,我們不會真的去複製它的值,而是複製引用而已。
方法調用
方法調用也必須註意參數是基本類型還是引用類型:
def foo(x)
x = 9999
return x
end
x = 1
foo(x);
x
請問最後 x 是多少? 還是 1 喔。在調用 foo 的時候,這個 x 的值被複製到方法的參數 x,所以方法裡面改的 x 變數,跟外面的 x 變數是不一樣的。
def bar(x) {
x[0] = 9999;
}
arr = [1,2,3];
bar(arr)
請問最後的 arr 是多少? 也被修改成 [9999,2,3] 了,調用方法,被復製成為參數的是引用,所以在方法裡面修改 x 就是修改 arr 的值。
會這樣設計的原因,也是因為預設複製引用類型成本太高了。
就地編輯(in-place editing)
在 Ruby 內建的 API 中,有些 API 是「回傳新的副本」、有些是「In-place」做修改(mutate),例如:
Array 的 sort 方法:
a = [5,1,9]
b = a.sort
b 會是排序好的 [1,5,9],但是 a 是沒有變的,還是 [5,1,9]
Array 的 sort! 方法:
a = [5,1,9]
a.sort!
這個 a 直接被修改了,變成 [1,5,9]
對 Ruby 來說,這個
!只是名字的一部分,沒有特別的作用。只是一個慣例提醒你說這個方法會有 副作用(side-effect)。
那什麽時候要用哪一種呢?比執行速度的話,「In-place」做修改(mutate) 是比「回傳新的副本」還快,因為後者需要新的記憶體空間來存儲。不過,實際寫代碼時,我們一般會偏好「回傳新的副本」的方式,因為這樣比較不容易有 bug。
這是因為一個軟體裡面的方法會調用其他方法,其他方法裡面又會調用方法,所以參數可能會傳遞到很深的方法裡面,如果有一個方法不小心直接修改了參數,對於調用者來說,可能不是預期會被修改的行為。因此用「回傳新的副本」的方式,會比較保險安全。
複製
組合數據類別的 = 指派只會複製引用,如果需要真的複製值,會改用 clone 方法:
a = [1,2,3]
b = a.clone
a[0] = 999
a
b
改了 a[0],就不會影響到 b 了。
不過,clone 不是萬能的,如果組合數據裡面又有組合數據,那麽….
a = [1,2,3]
b = [0, a]
c = b.clone
a[0] = 999
b
c
雖然 c 是 clone 出來的,但是改了 a,還是同時影響到 b,c 了。這是因為內建的 clone 是不支援 deep clone (深度複製)。這可能會有很複雜的情況,如果真的要複製,你需要自己寫方法。
看起來好像會很複雜,所幸我們不常碰到需要 clone 的情況。
9. 作用域 Variable Scope
變數作用域 Variable Scope 指的是變數可以被存取到的範圍,一般分成本地變數(Local variable)和全局變數(Global variable)
def foo
x = 1
end
x = 2
foo()
x # 仍然是 2
這段簡單的程序中,宣告在方法裡面的局部變數 x,只可以在該方法記憶體取的到,對外面來說是沒有影響的。對 Ruby 來說,一個局部變數的 scope 就是在該方法內。
至於全局變數則是不管在程式哪裡,都可以存取的到。在 Ruby 之中會用 $ 開頭,例如 $THIS_IS_GLOBAL_VERIABLE
Ruby 還有物件變數(Instance variable) Scope 和類變數(Class variable) scope,之後的物件導向教程會學到。
設計作用域 Variable Scope 的目的是避免變數名稱沖突(naming collisions)。
為什麽要避免變數名稱沖突呢?一個軟體會有很多方法,也會用到很多不是我們自己寫的庫,如果沒有作用域的話,變數名稱很可能會剛好命名成一樣,就沖突了。
同樣的原因,我們也會避免使用全域變數,就算要用,全域變數的命名也會取比較長,來避免沖突。
13. 正規表示法 Regular Expression
正規表示法 Regular Expression是一種精巧比對字串的方式。我們在實戰應用章節中,曾經用過這個技巧來驗證 URL 網址:
validates_format_of :friendly_id, :with => /\A[a-z0-9\-]+\z/
其中的 /\A[a-z0-9\-]+\z/ 就是一個正規表示法,檢查字串必須是小寫a到z,或數字0到9,或是橫線-。
更多用途舉例:
- 檢查 “Mississippi” 字串裡面有沒有出現 “ss” ?
- 找出每段文章中的第三個單字
- 將文章”開頭”中的 “Dear” 全部用 “Hi” 替換
- 將文章結尾的”.”換成”。”
- 檢查是否是合法的 Email、URL 自串
用法規則:
.符合任何單一字符\w單字字符\d數字字符\s任何空白\S非空白^行首位置*出現 0 次以上+出現 1 次以上?出現 0 或 1 次{m,n}出現 m 次到 n 次[a-z]a 到 z 範圍內的任何單一字符[^a-z]非 a-z 之外的任何單一字符
線上工具:
所幸,你不需要學習太難的表達式,大部分常用的正規表達式,用抄的就可以了,例如 知道這20個正規表示法,能讓你少寫1,000行代碼。