後端效能
7. 專案準備
為了讓大家可以練習改進後端效能,請 Fork 這個專案:https://github.com/ihower/speedup-app,然後 Clone 回去。
Fork 後,請依序執行:
git clone [email protected]:你的帳號/speedup-app.git
cd speedup-app
bundle install
bundle exec rake db:migrate
bundle exec rake fake
在這個專案中,已經裝好了 Devise、Bootstrap、RSpec,並且建立好了以下功能:
- 用戶登入、登出
- 用戶可以瀏覽貼文列表(posts index 頁面)
- 用戶可以瀏覽貼文的留言(posts show 頁面)
執行 rails server
接著打開瀏覽器 http://localhost:3000
資料庫中已經有一個用戶:
帳號: [email protected] 密碼: 12345678
請瀏覽看看前臺的首頁(文章列表),以及文章頁面:
8. 後端效能分析
For Basecamp 3, which is the biggest version now by load, our median response time is ~30ms, mean is ~120ms, and 90th percentile is ~180ms.
— DHH (@dhh) July 13, 2017
DHH 是 Rails 的發明人,這是他分享他們產品 Basecamp 的 response time 數據
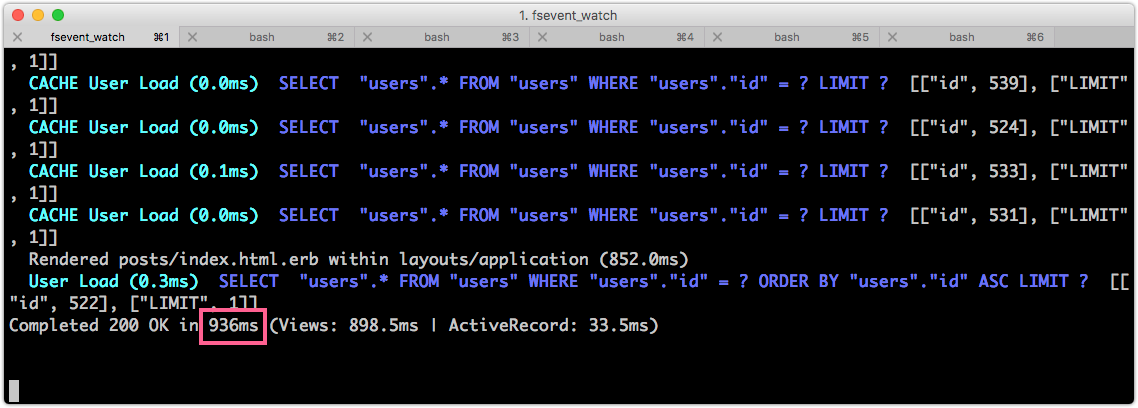
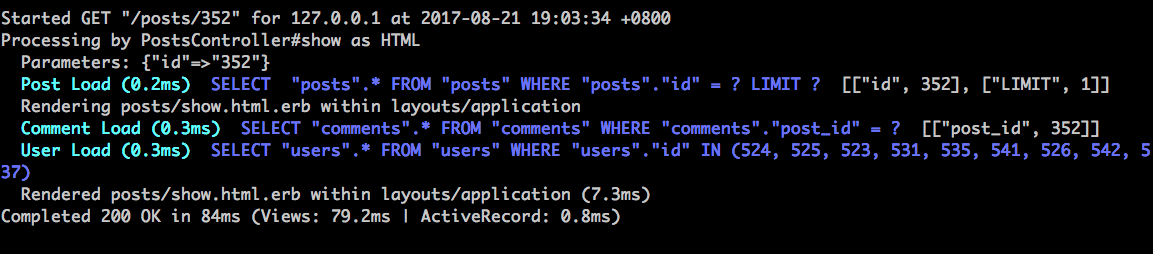
後端效能要關注的是個別 HTTP Request 的反應時間,也就是 Response Time。這個時間在 Rails log 中可以看到:
或是可以安裝 rack-mini-profiler 這個 gem,就可以在畫面上直接看到這個數據:
編輯 Gemile
+ gem 'rack-mini-profiler'
執行 bundle,重開 Rails。
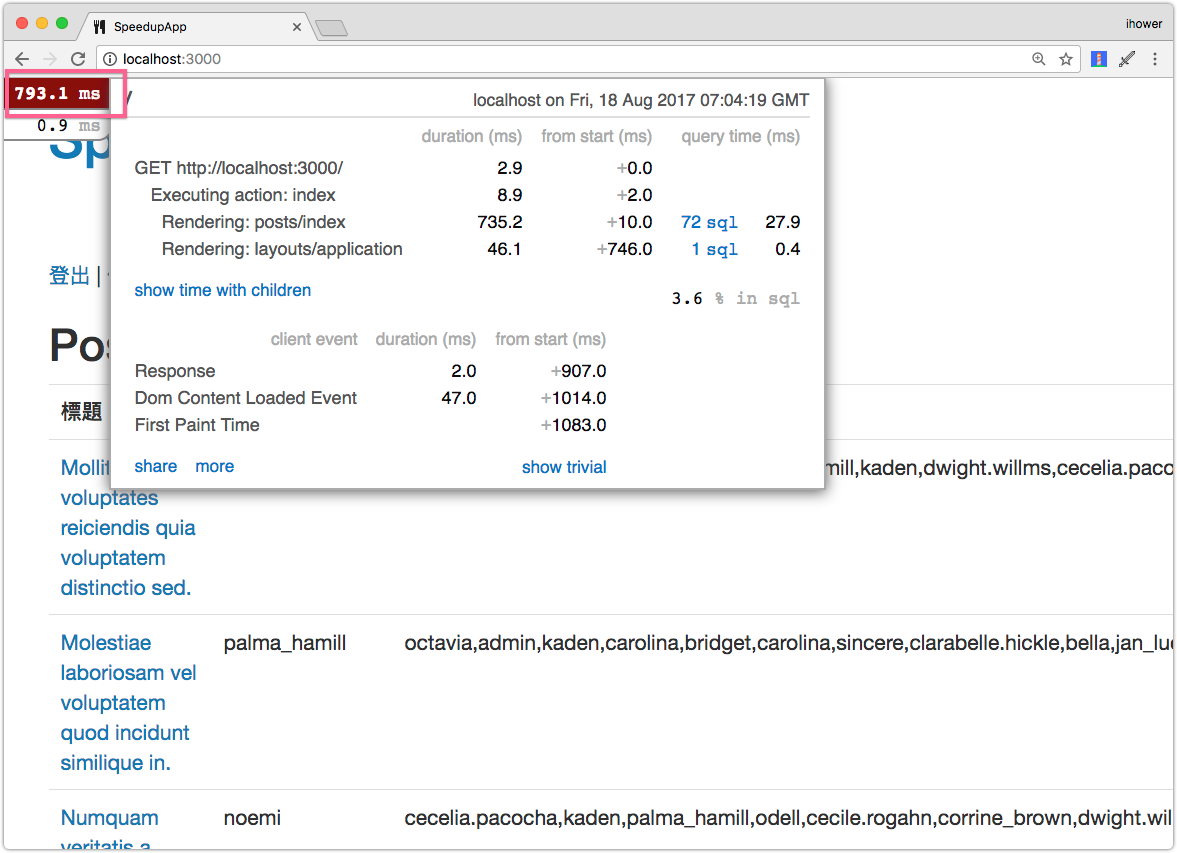
這樣網頁左上角就會出現 Response Time 的數據,點開來後還可以進到進一步的分析。
安裝第三方效能分析服務
80/20法則:會拖慢整體效能的程式,只佔全部程式的一小部分而已,所以我們只最佳化會造成問題的程式。接下來的問題就是,如何找到那一小部分的效能瓶頸,如果用猜的去找那3%造成效能問題的程式,再用感覺去比較改過之後的效能好像有比較快,這種作法一點都不科學而且浪費時間。善用分析工具找效能瓶頸,最佳化前需要測量,最佳化後也要測量比較。
透過以下的效能分析服務,可以收集網站實際營運的數據,找出哪些部分是效能不好的地方加以改善:

如果你有實際營運的網站,請挑一家註冊試用,根據它的說明會需要安裝它的 gem。
後端效能提速的方向
對後端來說,一個方向是提供 Rails 和 Ruby 代碼的效能,一個方向是提供資料庫方面的效能。
根據實務經驗,很大的機率會慢在資料庫的讀取上,這是因為 Rails 開發者很容易沉浸在 ActiveRecord 帶來的開發高效率上,而忽略了 ActiveRecord 很容易不小心就產生了效能差勁的 SQL 查詢。存取資料庫是一種相對於 CPU 運算很慢的 I/O 硬盤操作:每一條 SQL 查詢都得耗上時間、執行回傳的結果也會被轉成 ActiveRecord 物件然後放進記憶體。因此瞭解背後產生的 SQL 是其中的硬知識,我們會花比較多的篇幅在調整 ActievRecord 資料庫取數據的方式,以改善網站效能。
還沒看資料庫教程的話,建議您先完成該教程。
9. 避免 N+1 SQL 查詢
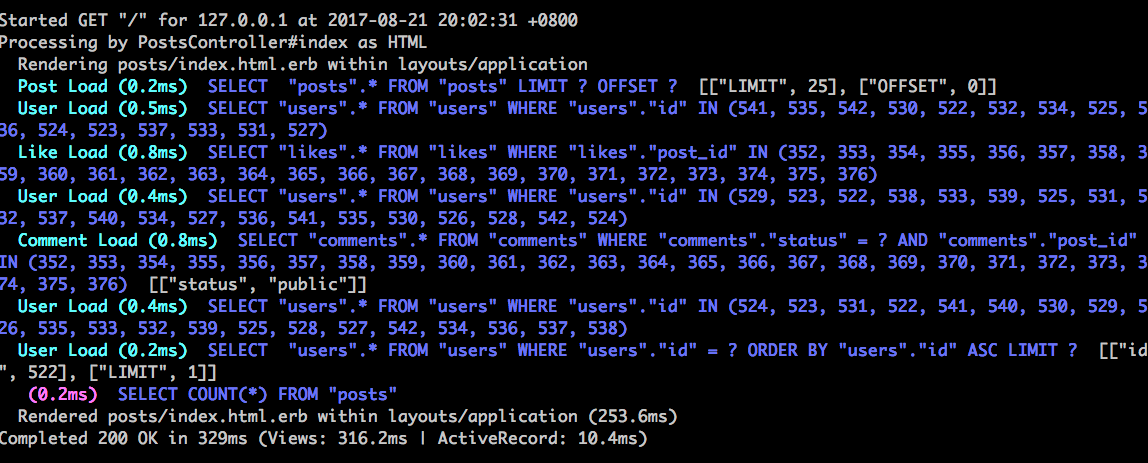
N+1 queries 是資料庫效能頭號殺手。ActiveRecord 的關聯功能功能很方便,但很容易發出過多的 SQL 查詢。在示範專案中,每篇貼文(Post) belongs_to 作者(User),請打開示範專案的首頁 http://localhost:3000,觀察一下 Rails Log:
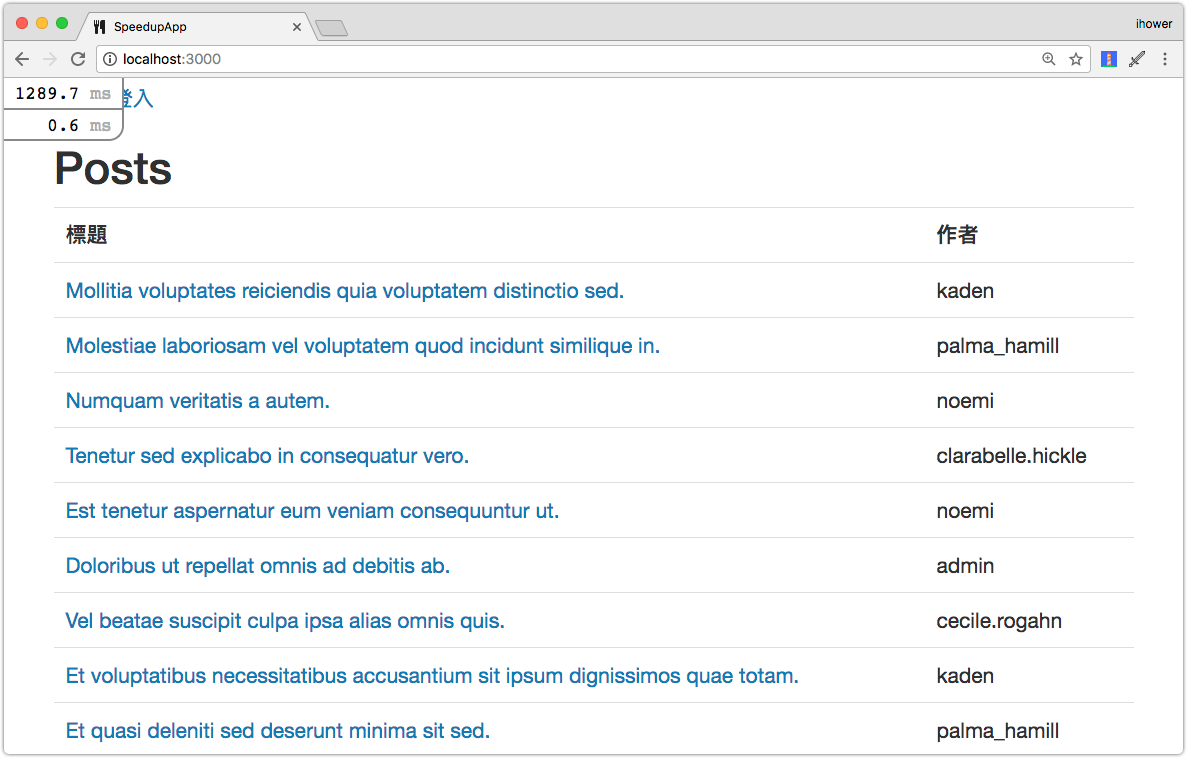
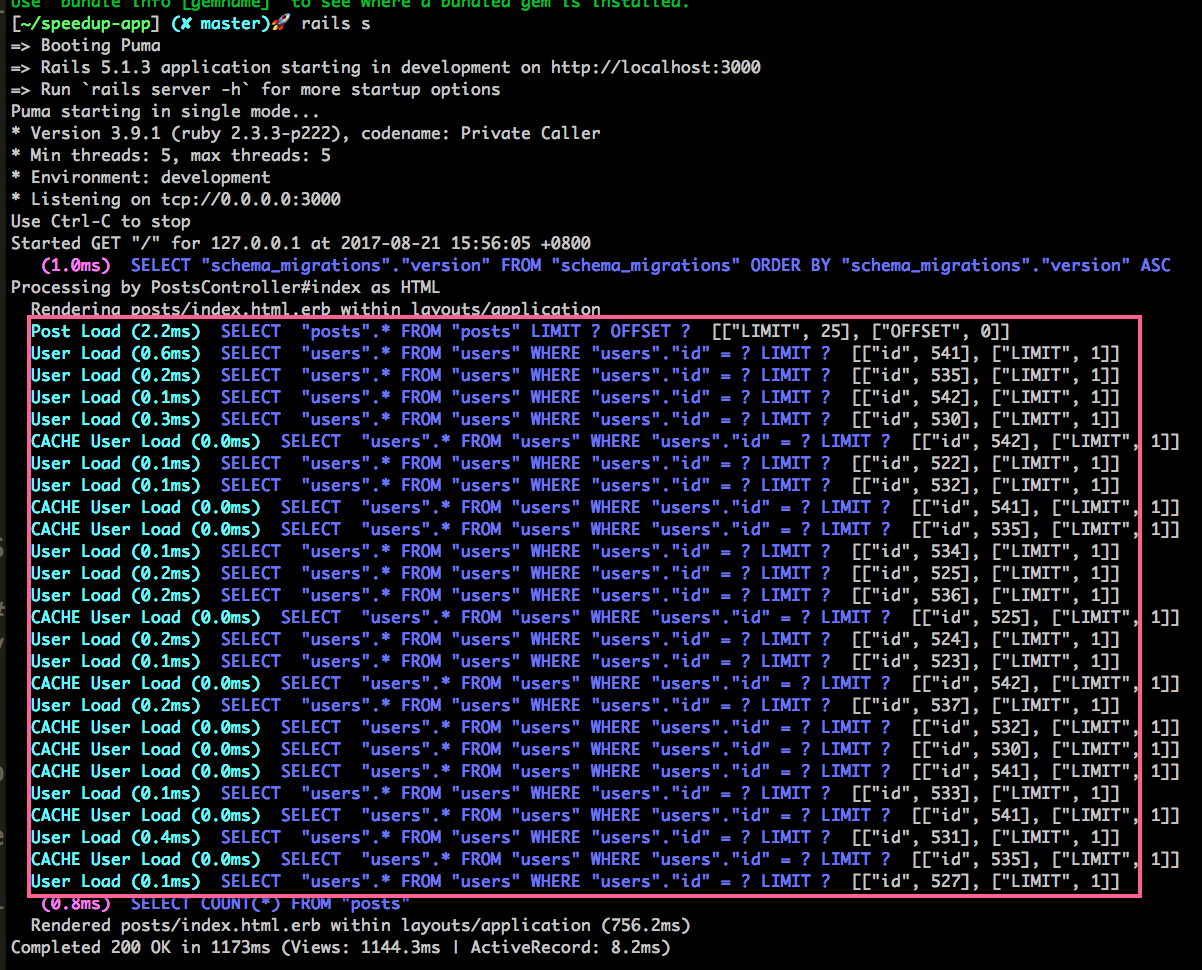
發現到很多很類似的 SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT ? [["id", XXX], ["LIMIT", 1]],而且根據 rack-mini-profiler 的數據,這一頁總共發出了 26 個 SQL 查詢,怎麽會這麽多?
關鍵在出在 app/views/posts/index.html.erb
<% @posts.each do |post| %>
<tr>
<td><%= link_to post.title, post_path(post) %></td>
<td><%= post.user.display_name %></td>
</tr>
<% end %>
這個循環中,每一次都需要讀取 post.user,造成了所謂的 N+1 問題,當一頁 Post 有 25 筆時,總共發出了 26 個 SQL 查詢,一筆是 SELECT * FROM posts,另外 25 筆是一筆一筆去 SELECT * FROM users WHERE users.id = XXX,嚴重拖慢了效能。
Rails 針對重復的 SQL 查詢有做快取,所以截圖中有的是 CACHE User Load。截圖中最後一個 SQL 查詢
SELECT COUNT(*) FROM posts是計算分頁的總頁數用到的。
解決方法也不難,我們需要在撈 posts 數據的時候,就要先告訴 ActiveRecord 我們也需要 posts 的 user 數據,這樣 ActiveRecord 就會預先撈出所有需要的 users 數據。
用到的語法是加上 includes,請修改 app/controllers/posts_controller.rb,把需要一起撈出來的關聯 model 加上去即可:
def index
- @posts = Post.page(params[:page])
+ @posts = Post.includes(:user).page(params[:page])
end
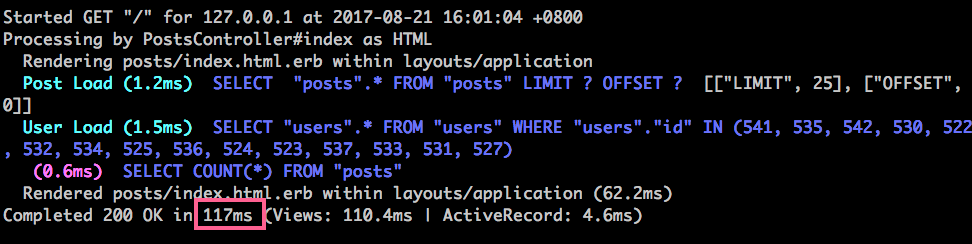
在觀察一次 Log,SQL 查詢就只剩下兩條了。一條撈 Posts,一條撈 Users。速度從 1173ms 提升到 117ms,快了十倍!
改進 posts#show 的 N+1
接下來點進任一篇文章,文章有許多留言,留言的作者也有一樣的 N+1 問題,讓我們處理一下:
def show
@post = Post.find(params[:id])
- @comments = @post.comments
+ @comments = @post.comments.includes(:user)
end
includes 多個關聯
includes 也可以一次撈多個關聯的數據,首先讓我們增加一個情境是 posts#index 頁面顯示每篇貼文的瀏覽用戶,以及按讚的用戶:
編輯 app/views/posts/index.html.erb
<table class="table">
<tr>
<th>標題</th>
<th>作者</th>
+ <th>留言用戶</th>
+ <th>按讚用戶</th>
</tr>
<% @posts.each do |post| %>
<tr>
<td><%= link_to post.title, post_path(post) %></td>
<td><%= post.user.display_name %></td>
+ <td><%= post.comments.map{ |c| c.user.display_name }.join(",") %></td>
+ <td><%= post.liked_users.map{ |u| u.display_name }.join(",") %></td>
</tr>
<% end %>
</table>
再次瀏覽 http://localhost:3000 看看 log,果然 N+1 又冒出來了,嚇死人的多:
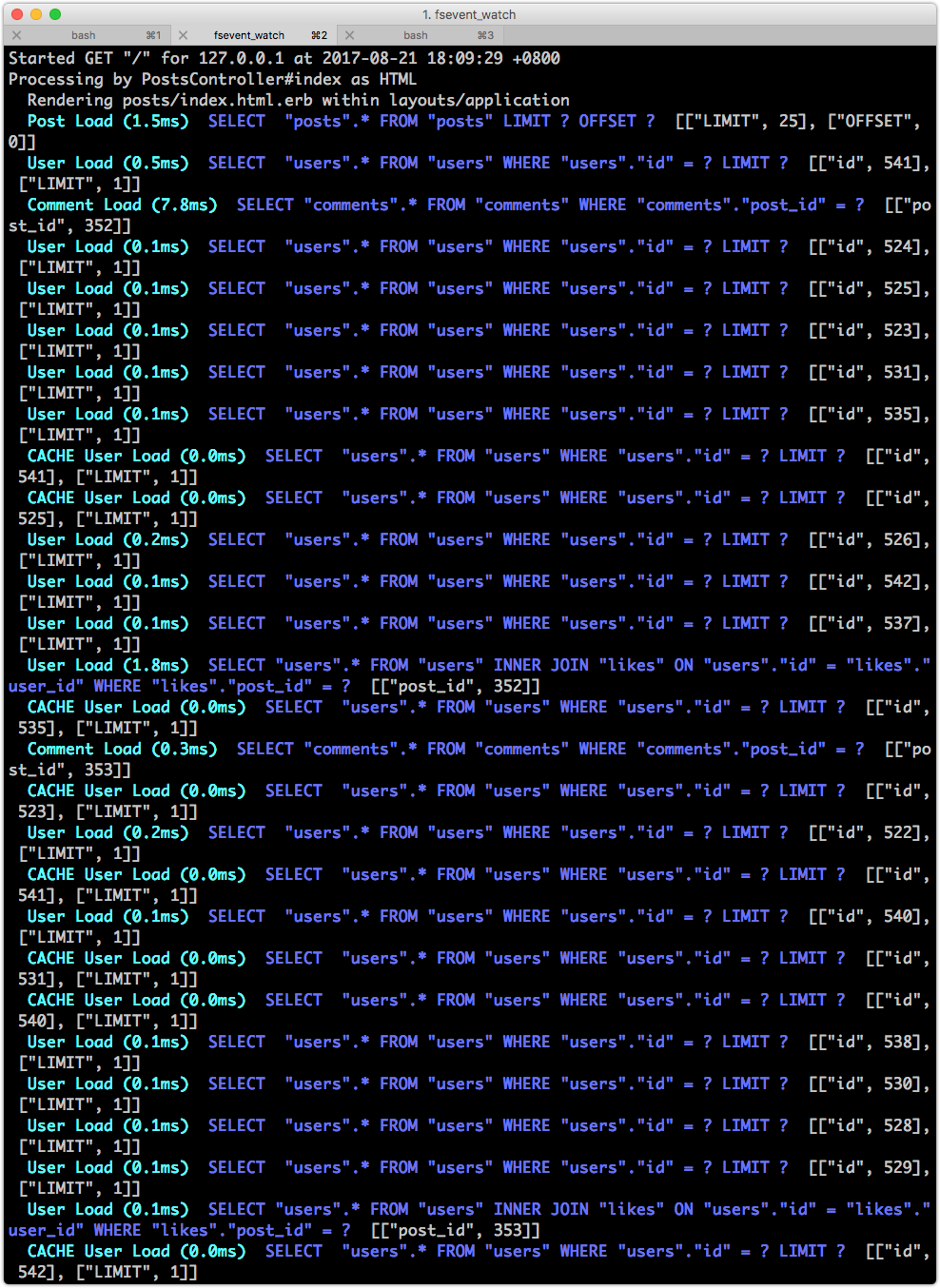
讓我們加上 includes,修改 app/controllers/posts_controller.rb:
def index
- @posts = Post.includes(:user).page(params[:page])
+ @posts = Post.includes(:user, :liked_users, { :comments => :user } ).page(params[:page])
end
其中 { :comments => :user } 這個 Hash 表示除了撈 comments 之外,還包括它的下一層 user 關聯。
includes 有條件怎麽辦?
這個範例專案的 Comment model 有一個欄位是 status 狀態,表示這個留言可以是公開(public)或私密留言(private),因此在 posts index 頁面上我們希望不要顯示狀態是私密的留言作者:
編輯 app/models/comment.rb 加上一個 scope:
class Comment < ApplicationRecord
belongs_to :user
belongs_to :post
+ scope :visible, -> { where( :status => "public") }
end
接下來你可能會直接修改 app/views/posts/index.html.erb 套用這個 scope:
- <td><%= post.comments.map{ |c| c.user.display_name }.join(",") %></td>
+ <td><%= post.comments.visible.map{ |c| c.user.display_name }.join(",") %></td>
觀察一下 rails log,很不幸的 N+1 又出現了,ActiveRecord 沒這麽聰明,它認為事先 includes 的 post.comments 跟這裡的 post.comments.visible 是不一樣的,所以發出了 N+1 Queries。
我們需要在 Post model 增加一個有條件的關聯,修改 app/models/post.rb
has_many :comments
+ has_many :visible_comments, -> { visible }, :class_name => "Comment"
然後修改 app/controllers/posts_controller.rb 改用這個新的有條件的關聯:
def index
- @posts = Post.includes(:user, :liked_users, { :comments => :user } ).page(params[:page])
+ @posts = Post.includes(:user, :liked_users, { :visible_comments => :user } ).page(params[:page])
end
最後修改 app/views/posts/index.html.erb
- <td><%= post.comments.map{ |c| c.user.display_name }.join(",") %></td>
+ <td><%= post.visible_comments.map{ |c| c.user.display_name }.join(",") %></td>
這樣就大功告成了,觀察 Rails log 可以看到 N+1 Queries 不見了。
用工具自動偵測 N+1 Queries
Bullet 這個 gem https://github.com/flyerhzm/bullet 可以在開發時協助偵測 N+1 queries 問題
10. ActiveRecord 優化技巧
除了 N+1 之外,還有一些使用 ActiveRecord 要註意的地方,其中一個最重要的觀念就是記憶體的使用:資料庫的數據放在硬盤,當我們使用 ActiveRecord 讀取數據時,會將數據從硬盤讀出,變成 Ruby 物件放在記憶體中,這是會耗費記憶體資源的,我們需要優化記憶體的使用。
避免 .all 查詢
硬盤的空間比記憶體大得多,放在資料庫的數據可能成千上萬筆。因此當你用例如 Post.all 查詢時,會將所有的 Post 數據讀進記憶體,當數據很多時就會非常慢。
解決方法我們都很熟悉了,就是使用分頁的機制,使用 will_paginate 或 kaminari來做分頁功能。
find_each 技巧
如果真的需要撈出全部的數據做處理,就需要分次撈才不會一次把記憶體吃光。Rails 針對這個情境提供了批次方法。
一個常見的情境是修理數據,假設我們想要在 Post 上新增一個欄位是 date,但是剛新增的欄位沒有數據,我們需要走訪所有的 Post 貼文去補上這個數據:
執行 rails g migration add_date_to_posts
編輯 db/migrate/2017XXXXXXXXXX_add_date_to_posts.rb
class AddDateToPosts < ActiveRecord::Migration[5.1]
def change
+ add_column :posts, :date, :date
+
+ Post.find_each do |post|
+ post.date = post.created_at.to_date
+ post.save( :validate => false )
+ end
end
end
執行 rake db:migrate 就會新增 date 欄位,然後用 Post.find_each 走訪所有貼文補上 date 數據,這個方法會每一千筆每一千筆去撈出 Posts 數據,而不是一次全部撈出來。
預加載(Preload)概念
留言有分公開(Public)和私密(Private)狀態,讓我們修改 Post show 頁面來反應這個需求:改成顯示全部公開的留言,以及我自己的私密留言。
修改 app/controllers/posts_controller.rb
def show
@post = Post.find(params[:id])
- @comments = @post.comments.includes(:user)
+ @comments = @post.comments.visible.includes(:user)
+ if current_user
+ @my_comments = @post.comments.where( :status => "private", :user_id => current_user.id ).includes(:user)
+ end
end
修改 app/views/posts/show.html.erb 加上我們私密留言
</table>
+ <% if current_user %>
+ <h2>My Comments</h2>
+
+ <table class="table">
+ <% @my_comments.each do |comment| %>
+ <tr>
+ <td><%= comment.content %></td>
+ <td><%= comment.user.display_name %></td>
+ </tr>
+ <% end %>
+ </table>
+ <% end %>
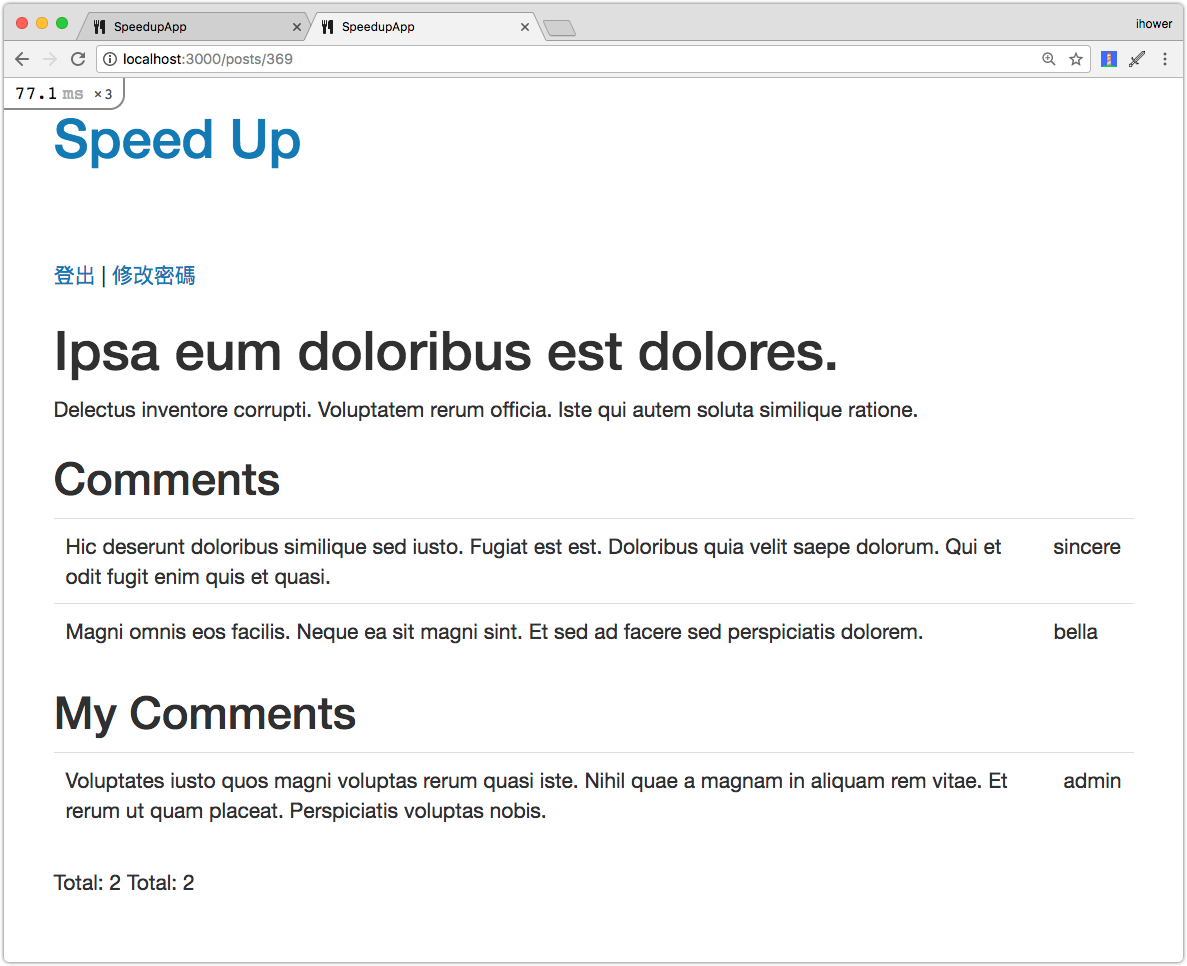
記得登入,然後不是每篇貼文都有我的留言,因為是亂數產生的,你可以試試別的貼文
看看 log 可以看到撈 comments 撈了兩次,一次是撈公開留言,一次是撈我的留言。
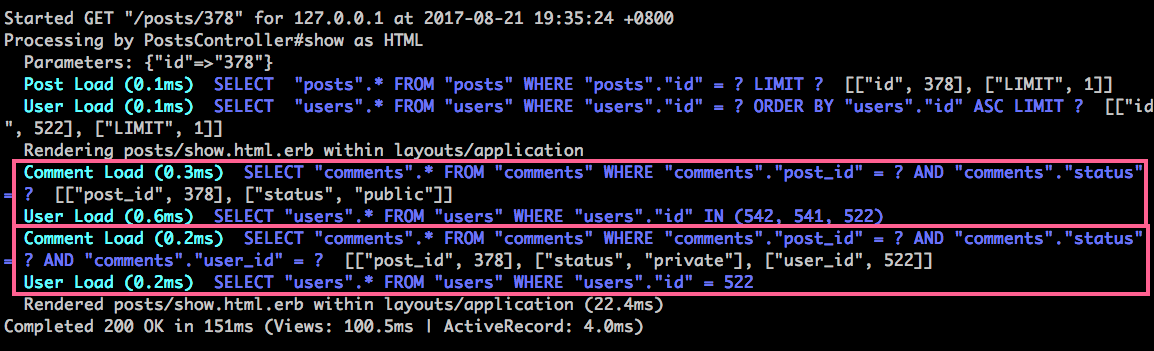
不過,如果你仔細想想,這兩個查詢根本就可以一次就撈出來,修改 app/controllers/posts_controller.rb
def show
@post = Post.find(params[:id])
- @comments = @post.comments.visible.includes(:user)
if current_user
- @my_comments = @post.comments.where( :status => "private", :user_id => current_user.id ).includes(:user)
+ all_comments = @post.comments.where("status = ? OR (status = ? AND user_id = ?)", "public", "private", current_user.id).includes(:user)
+ @comments = all_comments.select{ |x| x.status == "public" }
+ @my_comments = all_comments.select{ |x| x.status == "private" }
+ else
+ @comments = @post.comments.visible.includes(:user)
end
end
all_comments 就是我們預先撈出來的 comments,利用了 SQL 條件 "status = ? OR (status = ? AND user_id = ?)" 撈出所有公開或我的私密留言。然後 @comment 和 @my_comments 是用 select 這個陣列方法,從記憶體中再分別過濾出公開留言和我的私密留言。
這就是預先加載(Preload)概念: 我們盡可能合並 SQL 查詢一次撈出,然後再用陣列方法 select 過濾出需要的結果。
再次看一下 log,只撈了一次 comments 了。
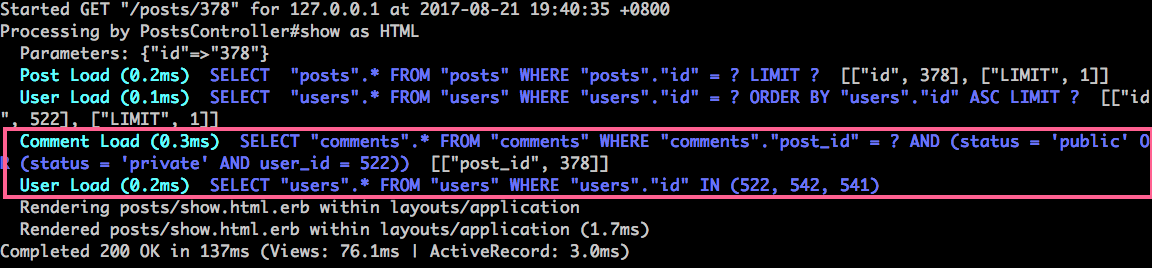
inverse_of 參數
在 ActiveRecord 設定關聯的屬性中,有一個冷門的 inverse_of 參數,這可以手動指定反向關聯的名稱是什麼。
class Post < ApplicationRecord
has_many :comments, :inverse_of => :post
end
class Comment < ApplicationRecord
belongs_to :post, :inverse_of => :comments
end
之所以比較少人知道,是因為通常我們不需要手動給:inverse_of,ActiveRecord 自己就可以根據慣例推導出來。
Rails 為什麼想要知道反向關聯呢? 這裡舉個例子,假設有個畫面是這樣的,會迭代 Post 和底下的 Comments:
<ul>
<% Post.includes(:comments).each do |post| %>
<li>
<%= post.title %>
<ul>
<% post.comments.each do |comment| %>
<li>
<%= comment.content %>
<%= comment.post.title %>
</li>
<% end %>
</ul>
</li>
由於有 includes(:comments) 的關係,所以 post.comments.each 的確不會造成 N+1 問題。值得探討的是 comment.post.title 這一行。只有在 Rails 正確知道反向關聯的前提下,這裡才不會再次去撈 Post 出來。不然 Rails 會笨笨的又 N+1 queries 去把外圈已經知道的 post 又撈出來,這是因為 Rails 不知道此 comment.post 等於外圈 post。
剛剛說 Rails 通常可以自己推導出 :inverse_of,但很可惜如果有搭配 -> { where 條件 }、:foreign_key、:through等參數時,Rails 就不會推導了。例如上述範例,只要補個 :foreign_key 且不要手動給 :inverse_of
class Post < ApplicationRecord
has_many :comments, :foreign_key => :post_id
end
或是
class Comment < ApplicationRecord
belongs_to :post, :foreign_key => :post_id
end
於是你就會看到 N+1 queries 問題冒出來了。所以,只要稍微複雜的 View 有共用一些 comment partial 樣板,在不知不覺中是很有可能會用到反向關聯的。
count 和 size 方法
count 和 size 方法都可以查詢數量,這兩個方法有什麽差異嗎?我們在 posts show 頁面上顯示一下留言的數量,請 編輯 app/views/posts/show.html.erb,在最下方加入:
Total: <%= @comments.count %>
Total: <%= @comments.count %>
這裡故意放兩行來示範效果
然後看一下 log:
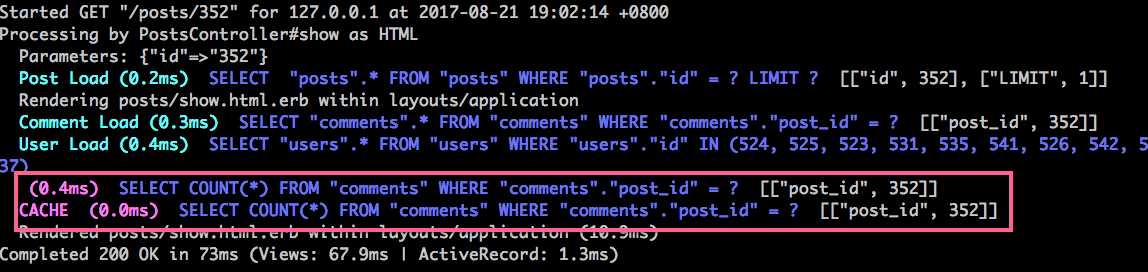
會看到有兩條 COUNT 的 SQL。讓我們改成 .size 方法看看:
- Total: <%= @comments.count %>
- Total: <%= @comments.count %>
+ Total: <%= @comments.size %>
+ Total: <%= @comments.size %>
會發現竟然沒有 COUNT SQL 了。
- 調用
count方法是對資料庫送出一次 COUNT 的 SQL 查詢 - 而
size是陣列的方法,因為@comments這個物件已經在記憶體了,調用size是去計算這個@comments裡面元素的數量,因此不需要再發出 COUNT 的 SQL 查詢。
在這個範例中,因為畫面中已經顯示了 @comments,表示這個數據已經從資料庫中撈出,所以適合用 .size 方法,而不需要用 .count 重復再問一次資料庫。
讓我們換一個情境,在 posts index 頁面上顯示留言的數量,請修改 app/views/posts/index.html.erb,加上留言數:
<table class="table">
<tr>
<th>標題</th>
<th>作者</th>
+ <th>留言數</th>
<th>留言用戶</th>
<th>按讚用戶</th>
</tr>
<% @posts.each do |post| %>
<tr>
<td>
<% if current_user && current_user.like_post?(post) %>
👍👍👍
<% end %>
<%= link_to post.title, post_path(post) %>
</td>
<td><%= post.user.display_name %></td>
+ <td><%= post.visible_comments.count %></td>
<td><%= post.visible_comments.map{ |c| c.user.display_name }.join(",") %></td>
<td><%= post.liked_users.map{ |u| u.display_name }.join(",") %></td>
</tr>
<% end %>
</table>
看一下 log,發現 N+1 又出來了:
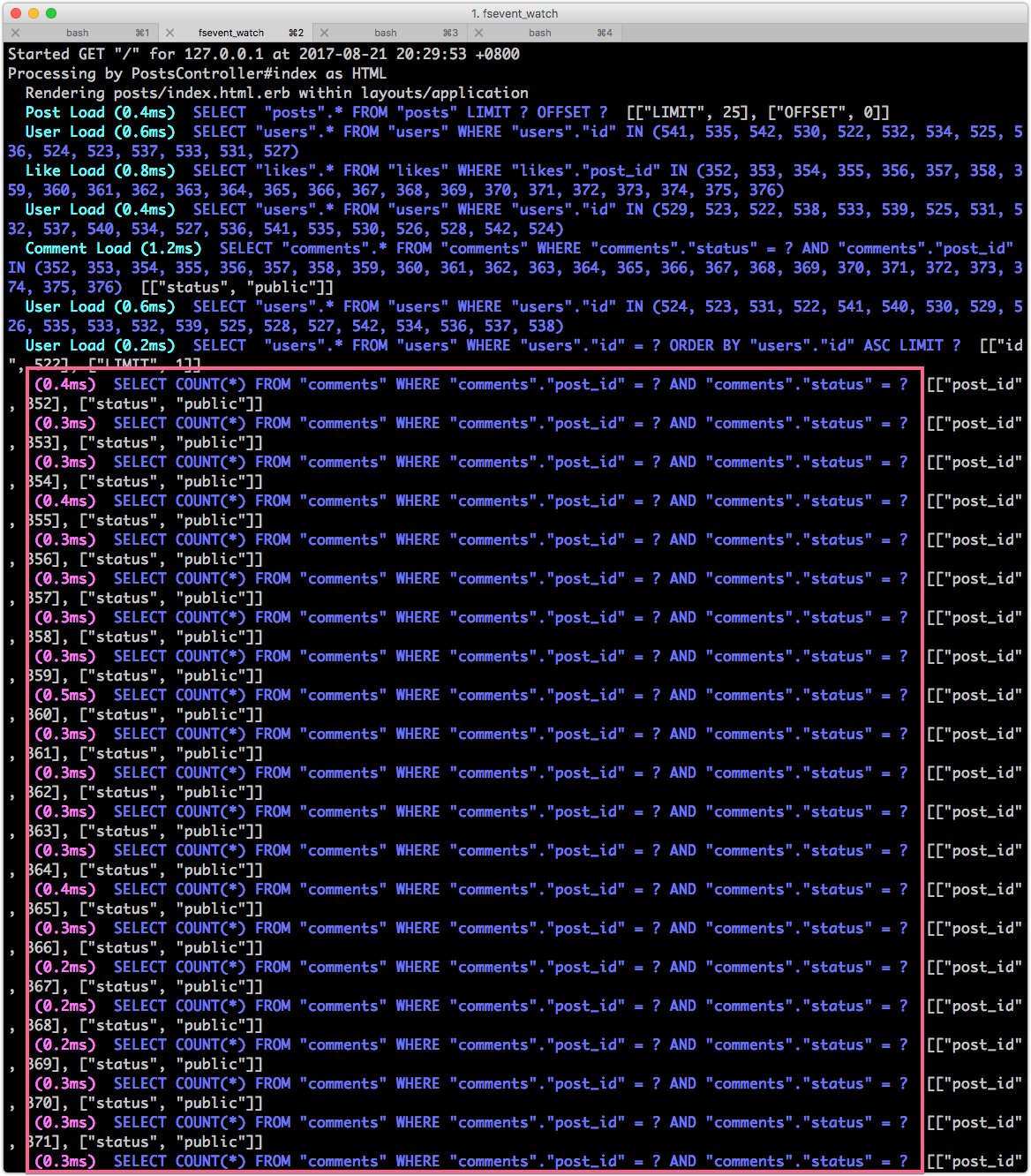
這個情境下用 count 就不對了,因為 post.visible_comments 我們其實已經撈出來了,應該用 size 方法去算即可,不需要再問一次資料庫:
- <td><%= post.visible_comments.count %></td>
- <td><%= post.visible_comments.size %></td>
再看一次 log,多的 SQL queries 現在都沒了。
避免重復 SQL 查詢
情境是我們想在 posts index 頁面上顯示我是否有按過讚:
修改 app/models/user.rb,讓我們新增一個方法判斷 User 有沒有針對一篇 Post 按過 Like:
def like_post?(post)
# 或是寫 self.likes.where( :post_id => post.id ).first.present? 也可以
self.likes.where( :post_id => post.id ).exists?
end
修改 app/views/posts/index.html.erb
- <td><%= link_to post.title, post_path(post) %></td>
+ <td>
+ <% if current_user && current_user.like_post?(post) %>
+ 👍👍👍
+ <% end %>
+ <%= link_to post.title, post_path(post) %>
+ </td>
代碼看起來很簡單,一下就寫好了,讓我看看對效能有沒有影響:
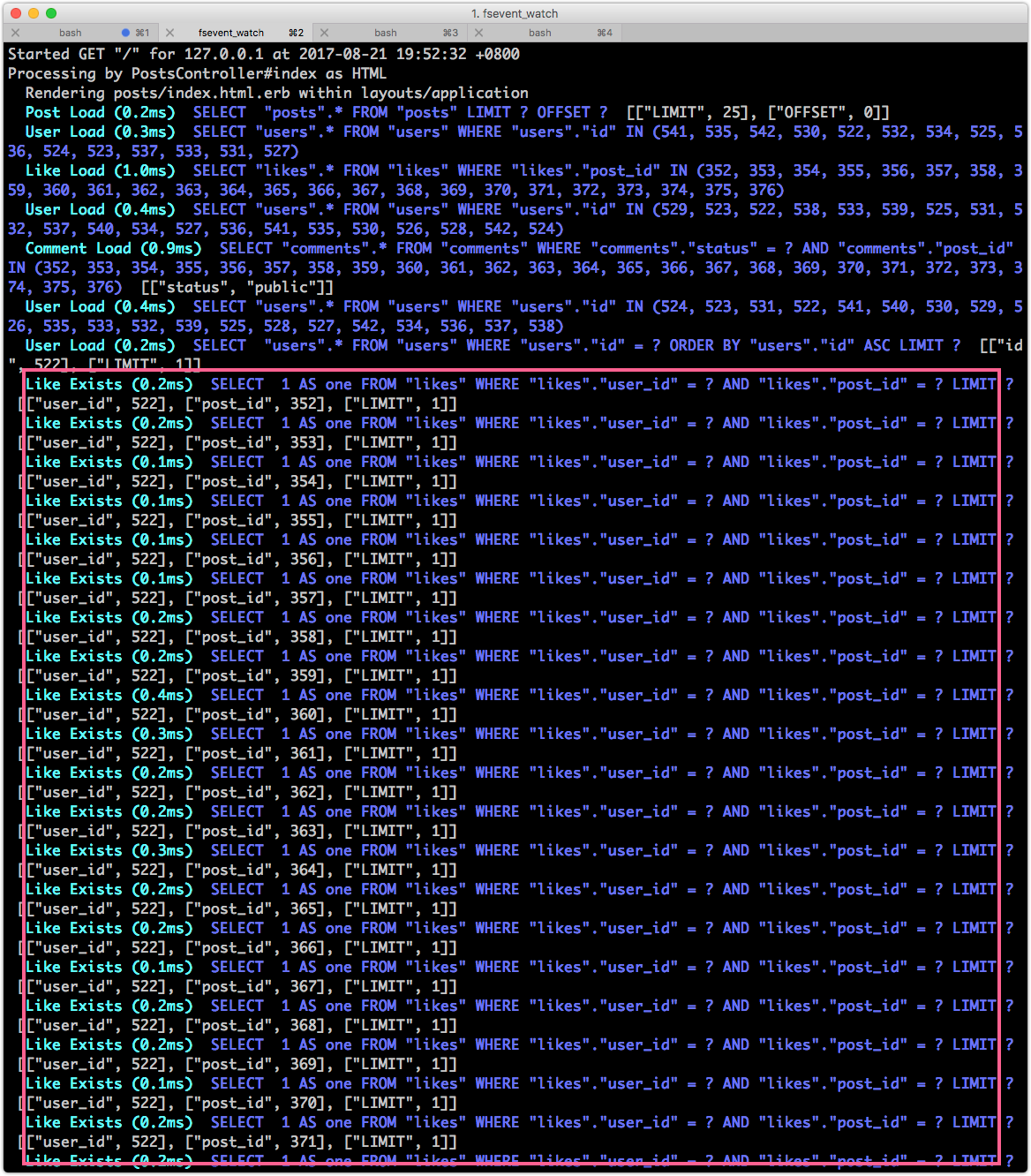
嚇死人,怎麽多出這麽多多 SELECT "likes".* FROM "likes" WHERE "likes"."user_id" = ? AND "likes"."post_id" = ? ORDER BY "likes"."id" ASC LIMIT ?,每篇貼文都去查詢一次有沒有 Like。
如果你已經有了上一節預加載(Preload)觀念,就會聯想到這個 likes 數據,我們在上一章其實已經撈出來了,也就是 liked_users,我們應該去檢查貼文的 liked_users 裡面有沒有我自己,就可以判斷我有沒有按過讚了。
修改 app/models/user.rb
def like_post?(post)
- self.likes.where( :post_id => post.id ).exists?
# post.liked_users 實際上在 controler 中已經被取出放進記憶體了,這裡用陣列的 include? 方法去檢查裡面有沒有我自己
+ post.liked_users.include?(self)
end
再次看一下 log,發現多的 SQL 都不見了 👍👍👍
不過請放心:你是很難有先見之明知道要這樣寫的,因為不同頁面會加載的數據不同,需要因地制宜的優化。
pluck 技巧
使用 ActiveRecord 從資料庫中取出數據時,會形成 ActiveRecord 物件放進記憶體,而這個 ActiveRecord 類其實有點肥大,因為它本身包含很多操作方法等等。因此在只需要取出單純數據,而不需要 ActiveRecord 任何功能的時候,可以用 pluck 方法,例如我們只想要取出所有用戶的 email 數據:
emails = User.all.map{ |u| u.email }
和
emails = User.pluck(:email)
兩者的速度差了非常多:前者需要將所有用戶撈出來變成 ActiveRecord 物件,然後再轉成 email 的陣列。後者直接就是 email 陣列。
11. 資料庫 SQL 優化
越瞭解 SQL,使用 ActiveRecord 就越得心應手。瀏覽 http://localhost:3000/posts/report 這一頁:
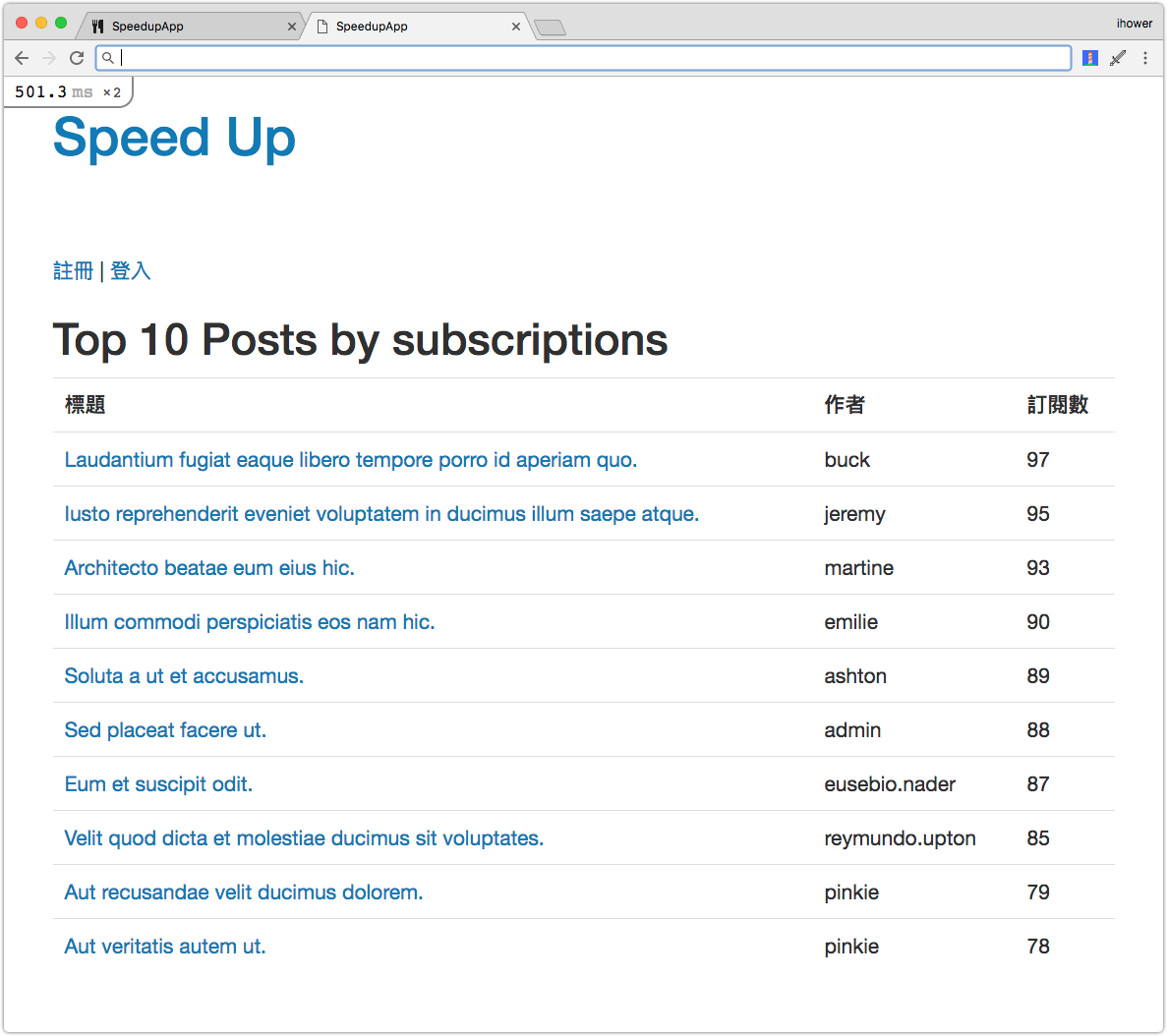
這一頁會顯示哪些 Post 的訂閱數(Subscription)最多,依照留言數排序:
看一下 log,不太妙:
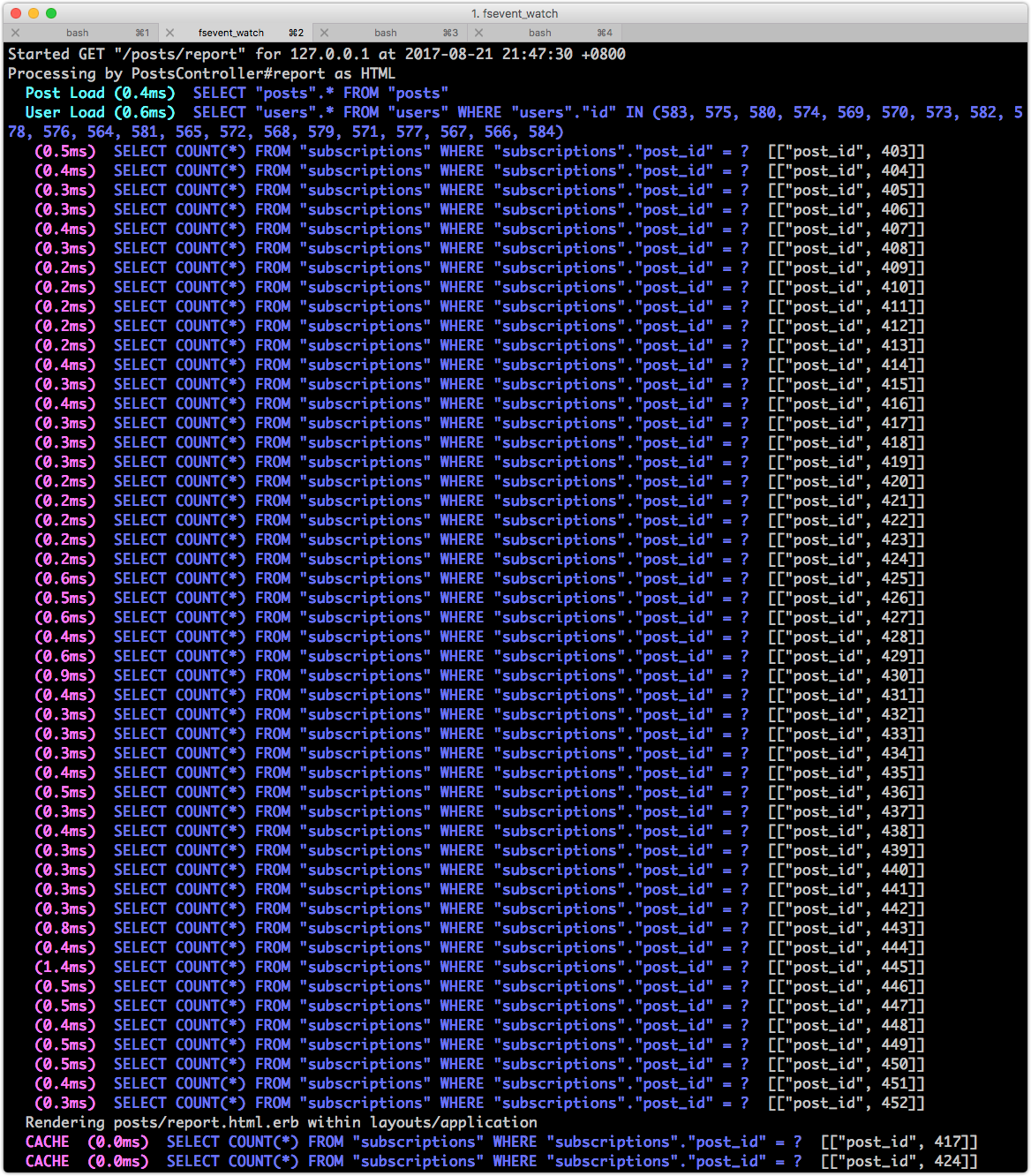
本來的實作有什麽問題呢?打開 app/controllers/posts_controller.rb 這個檔案進行優化:
def report
- @posts = Post.all.include(:user).sort_by{ |post| post.subscriptions.size }.reverse[0,10]
+ @posts = Post.includes(:user).joins(:subscriptions).group("posts.id").select("posts.*, COUNT(subscriptions.id) as subscriptions_count").order("subscriptions_count DESC").limit(10)
end
接著修改 app/views/posts/report.html.erb
- <td><%= post.subscriptions.size %></td>
+ <td><%= post.subscriptions_count %></td>
優化之後的結果:
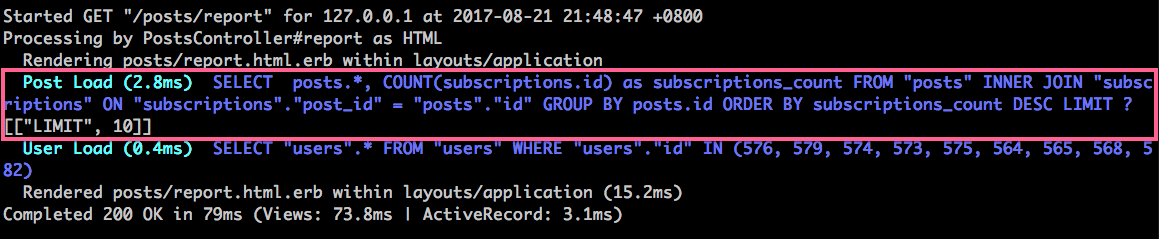
解說:因為訂閱數並不是 Post 的一個欄位,我們不能直接寫 Post.order("subscriptions_count DESC").limit(10),需要想辦法去計算訂閱數:
- 本來的做法需要撈出所有的 Post 貼文到記憶體中,每篇貼文計算訂閱數,然後陣列排序之後,取出前十名
- 新的做法是 SQL 的
group語法,交由資料庫的引擎來計算,最後剛剛好取出 10 筆數據成為 Ruby 物件放入記憶體
在購物網站中,這個其實就是購物車分析的功能:你可以分析哪些商品最常被加入購物車但是沒有結帳。
像這種計算報表類型的應用,如果你把數據從資料庫都取出用 Ruby 來計算的話,效能會非常差。你需要利用 SQL 來讓資料庫引擎來做內部運算,效能才會快。
12. 計數快取 (Counter Cache)
在資料庫教程中,我們提過逆正規化(Denormalized)的概念,這一章讓我們來實際實作看看。
想要做的情境是 posts index 頁面上,我們想要顯示訂閱數(Subscriptions)。首先編輯 app/views/posts/index.html.erb 加上訂閱數:
<th>留言數</th>
+ <th>訂閱數</th>
# 略
<td><%= post.visible_comments.size %></td>
+ <td><%= post.subscriptions.size %></td>
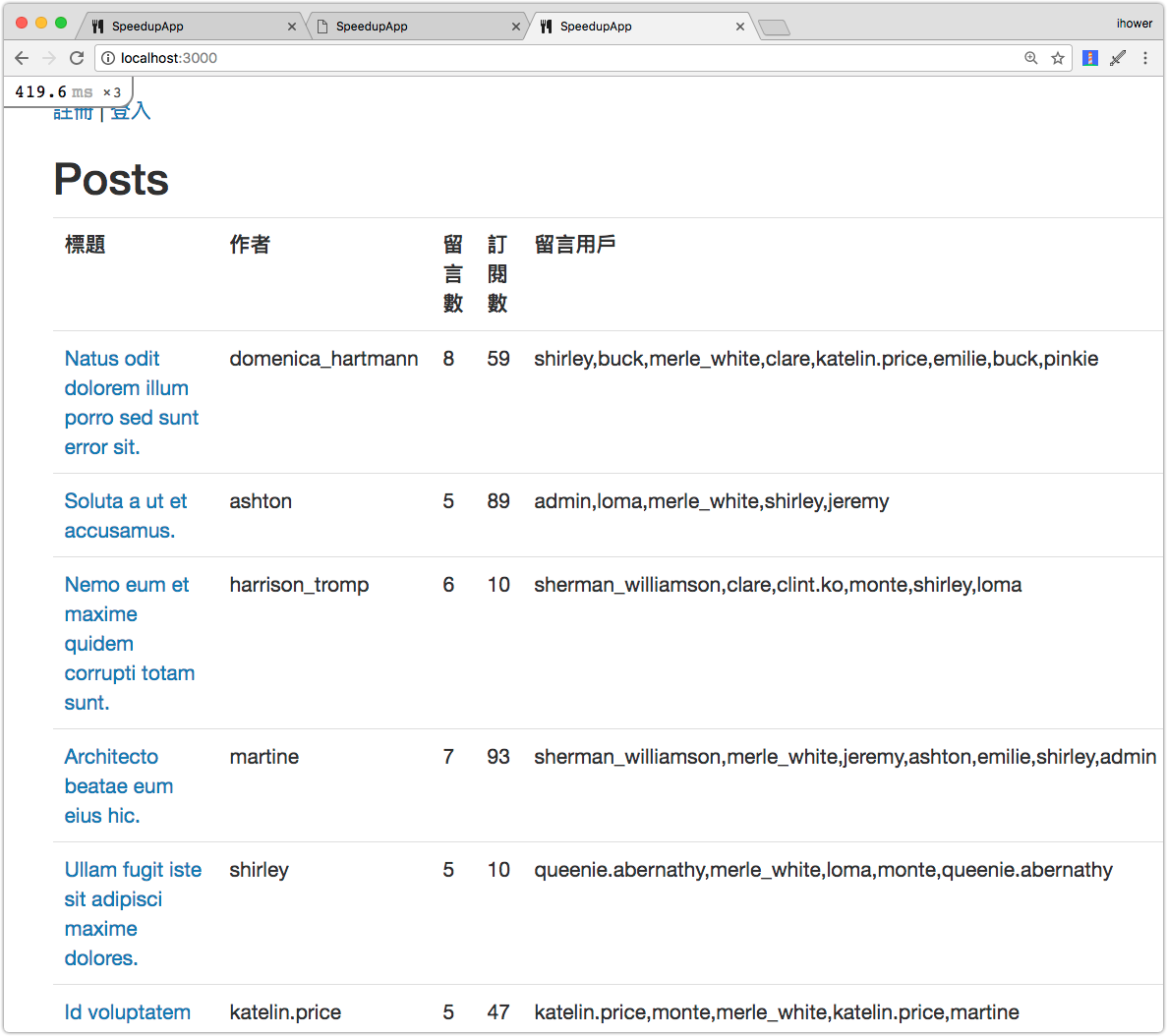
不意外的,這樣寫造成了很多 SQL 查詢:
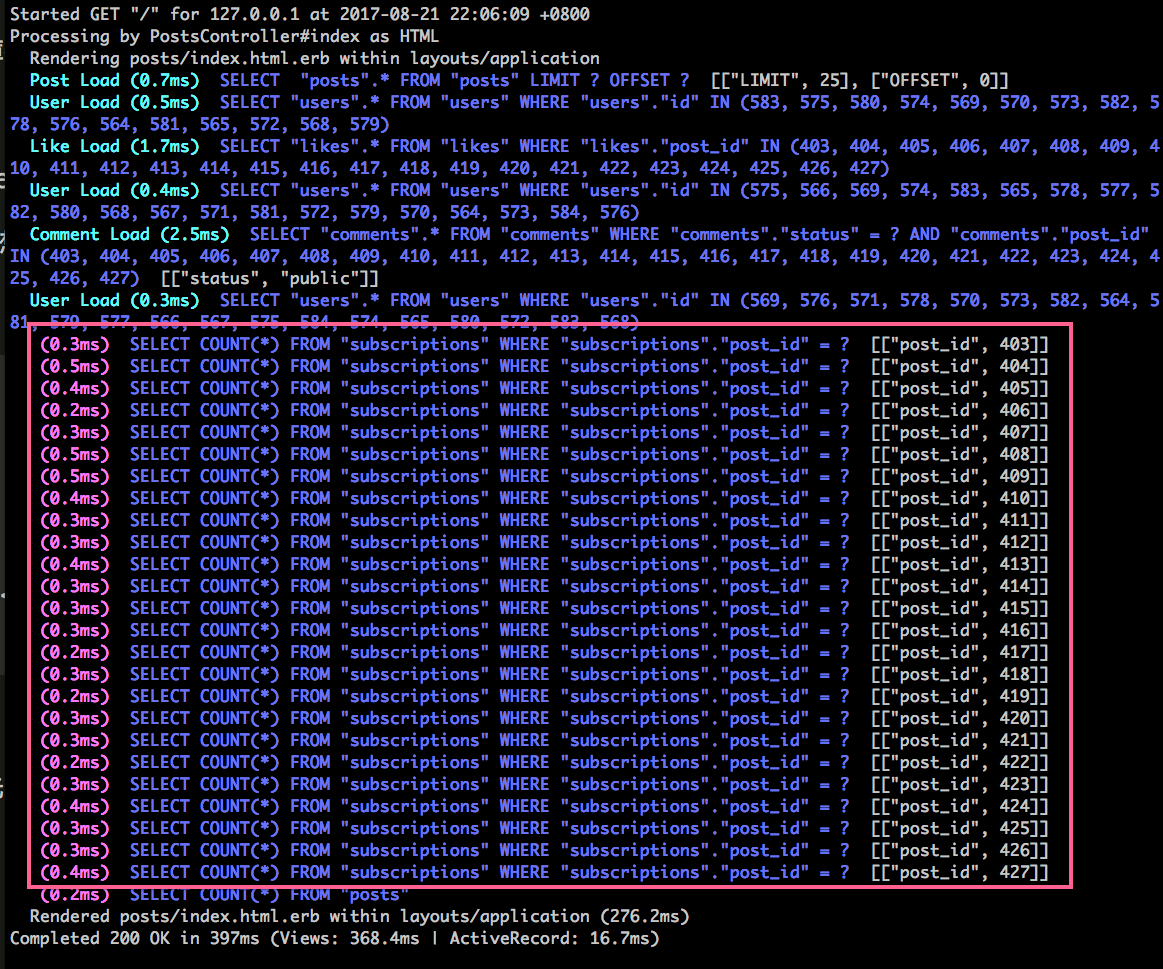
跟顯示 visible_comments 留言數不同,訂閱的數據並沒有被預先加載,所以需要一筆一筆去 COUNT。要怎麽改善呢?
如果你熟悉 SQL 的話,可以用 SQL 解決,編輯 app/controllers/posts_controller.rb:
def index
@posts = Post.includes(:user, :liked_users, { :visible_comments => :user } ).page(params[:page])
+ post_ids = @posts.map{ |p| p.id }
+ @subscriptions_count = Post.where( :id => post_ids).joins(:subscriptions).group("posts.id").count
end
編輯 app/views/posts/index.html.erb
- <td><%= post.subscriptions.size %></td>
+ <td><%= @subscriptions_count[post.id] %></td>
觀察一下 log,我們只用一條 SQL 就可以計算這一頁貼文的所有訂閱數:
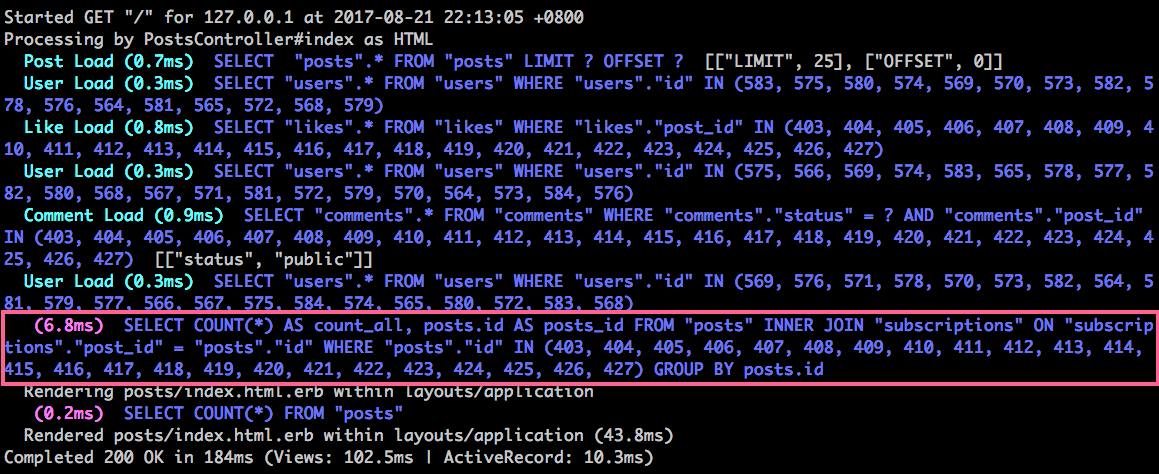
@subscriptions_count這個變數是個 Hash,鍵是 post ID,值是訂閱數,例如{403=>59, 404=>89, 405=>10, 406=>93, 407=>10, 408=>47, 409=>90, 410=>78, 411=>79, 412=>43, 413=>58, 414=>13, 415=>61, 416=>76, 417=>97, 418=>59, 419=>41, 420=>68, 421=>44, 422=>44, 423=>85, 424=>95, 425=>12, 426=>54, 427=>78}
不過,這一頁是流量最高的首頁,有沒有辦法可以更快更簡單?
計數快取 (Counter Cache)
像這種 Post has_many subscriptions 的一對多關系,如果經常要顯示有多少筆數據,與其每次都用 SQL 計算,我們可以用逆正規化的概念,直接新增一個 posts 的欄位把訂閱的數字存下來,這樣顯示的時候直接就可以顯示了,不需要再計算。然後每次新增或刪除 Subscription 時,需要記得去更新這個值即可。
Rails 內建就有計數快取 (Counter Cache) 的功能:
執行 rails g migration add_subscriptions_to_posts
編輯 db/migrate/2017XXXXXXXXXX_add_subscriptions_to_posts.rb,新增一個欄位 subscriptions_count 到 posts 上,表示這篇貼文有多少訂閱數:
class AddSubscriptionsToPosts < ActiveRecord::Migration[5.1]
def change
+ add_column :posts, :subscriptions_count, :integer, :default => 0
+ Post.pluck(:id).each do |i|
+ Post.reset_counters(i, :subscriptions) # 剛新增的欄位都是 0,需要將計數全部重算一次
+ end
end
end
編輯 app/models/subscription.rb,加上 counter_cache,這會告訴 Rails 如果有新增或刪除 Subscription 時,自動去更新 Post 的 subscriptions_count 數字:
- belongs_to :post
+ belongs_to :post, :counter_cache => true
# 或 belongs_to :post, :counter_cache => "subscriptions_count"
執行 rake db:migrate
修改 app/views/posts/index.html.erb,直接顯示這個數字:
- <td><%= @subscriptions_count[post.id] %></td>
+ <td><%= post.subscriptions_count %></td>
修改 app/controllers/posts_controller.rb,不需要再計算訂閱數了:
def index
@posts = Post.includes(:user, :liked_users, { :visible_comments => :user } ).page(params[:page])
- post_ids = @posts.map{ |p| p.id }
- @subscriptions_count = Post.where( :id => post_ids).joins(:subscriptions).group("posts.id").count
end
Rails 內建的 Counter Cache 功能比較簡單,如果你需要更多功能,請參考 https://github.com/magnusvk/counter_culture 這個 gem。
再一個逆正規化的例子
需求情境:在 posts index 頁面上,顯示每篇貼文的最後訂閱的時間
逆正規化解法:
- 在 posts table 上新增一個一個 last_subscribed_at 時間欄位
- 在有人訂閱時,例如 subscriptions controller 的 create action 中,去更新該篇 post 的 last_subscribed_at 值
- 在有人取消訂閱時,例如 subscriptions controller 的 destroy action 中,去更新該篇 post 的 last_subscribed_at 值
跟 Counter Cache 概念一樣,只是實作麻煩一點,我們需要手動在正確的時機去維護 last_subscribed_at 的值
小結論:什麽時候用逆正規化做優化?
如果不常顯示該數據,而且你會寫 SQL 做計算的話,我們可以用純 SQL 解決。 的方式來解決。但是如果需要經常顯示該數據,就可以考慮用逆正規化的方式,將數據快取下來。這樣效能可以更好。但是缺點就是需要維護該數據的正確性,要寫的 Ruby 代碼也比較多。
考量:讀取的頻率 v.s. 更新快取數據的成本
13. 改進 Render Partial 的效能
看 SQL 頭暈了嗎?這一章讓我們看一個 Rails View 的效能改善,情境是當同一個 partial 需要不斷 render 時,可以改用 collection 的寫法,效能會更好。
例如我們將 index 頁面中每一筆 post 改成用 partial 處理:
修改 app/views/posts/index.html.erb
<% @posts.each do |post| %>
- <tr>
- <td>
- <% if current_user && current_user.like_post?(post) %>
- 👍👍👍
- <% end %>
- <%= link_to post.title, post_path(post) %>
- </td>
- <td><%= post.user.display_name %></td>
- <td><%= post.visible_comments.size %></td>
- <td><%= post.subscriptions_count %></td>
- <td><%= post.visible_comments.map{ |c| c.user.display_name }.join(",") %></td>
- <td><%= post.liked_users.map{ |u| u.display_name }.join(",") %></td>
- </tr>
+ <%= render :partial => "post", :locals => { :post => post } %>
<% end %>
新增 app/views/posts/_post.html.erb
<tr>
<td>
<% if current_user && current_user.like_post?(post) %>
👍👍👍
<% end %>
<%= link_to post.title, post_path(post) %>
</td>
<td><%= post.user.display_name %></td>
<td><%= post.visible_comments.size %></td>
<td><%= post.subscriptions_count %></td>
<td><%= post.visible_comments.map{ |c| c.user.display_name }.join(",") %></td>
<td><%= post.liked_users.map{ |u| u.display_name }.join(",") %></td>
</tr>
看一下 log,其中不斷調用 Rendered posts/_post.html.erb 這個 partial 樣板:
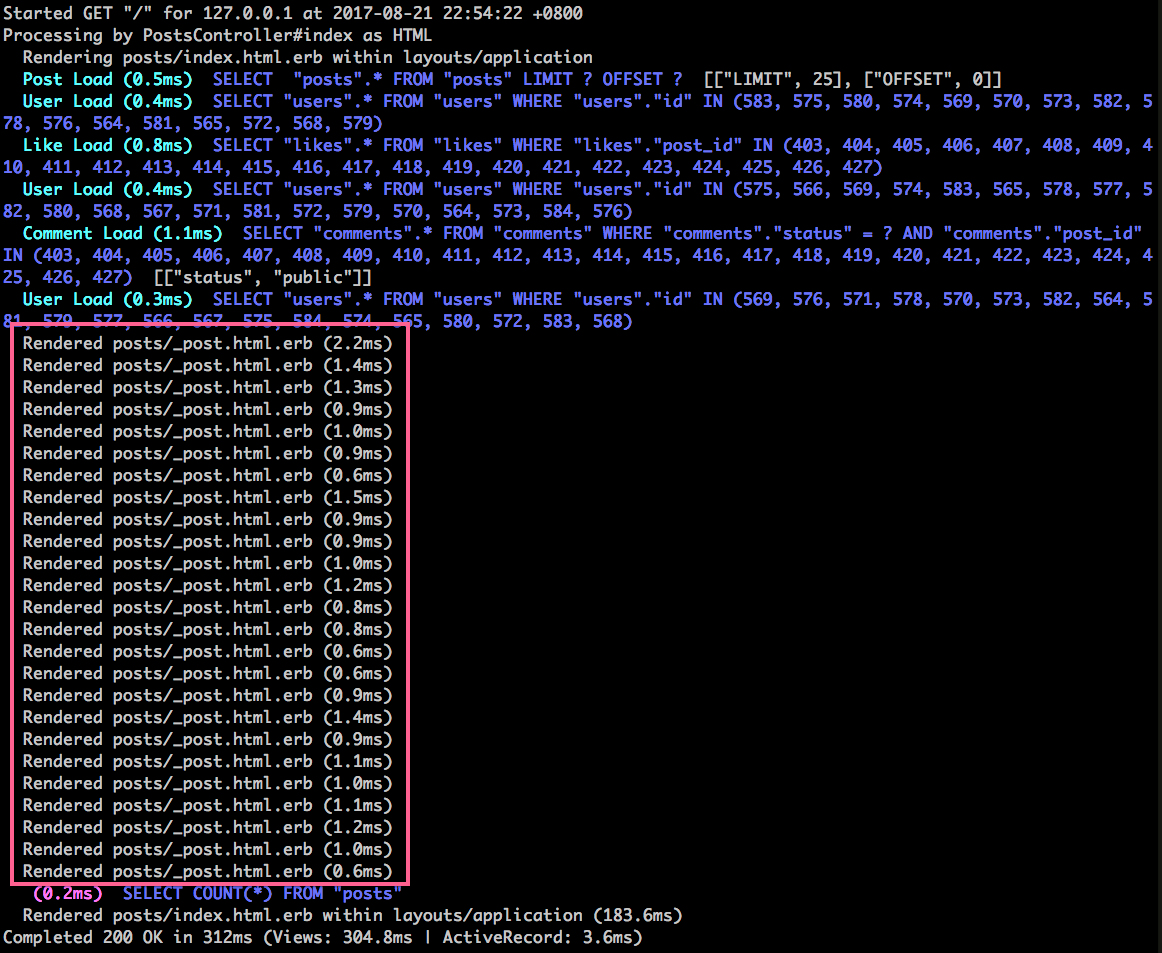
怎麽改進呢?Rails 針對這種情況,有提供一個優化的寫法,再次編輯 app/views/posts/index.html.erb:
- <% @posts.each do |post| %>
- <%= render :partial => "post", :locals => { :post => post } %>
- <% end %>
+ <%= render :partial => "post", :collection => @posts, :as =>
:post %>
整個 @posts.each 循環都拿掉了,新的 :collection 參數就會幫你做循環。
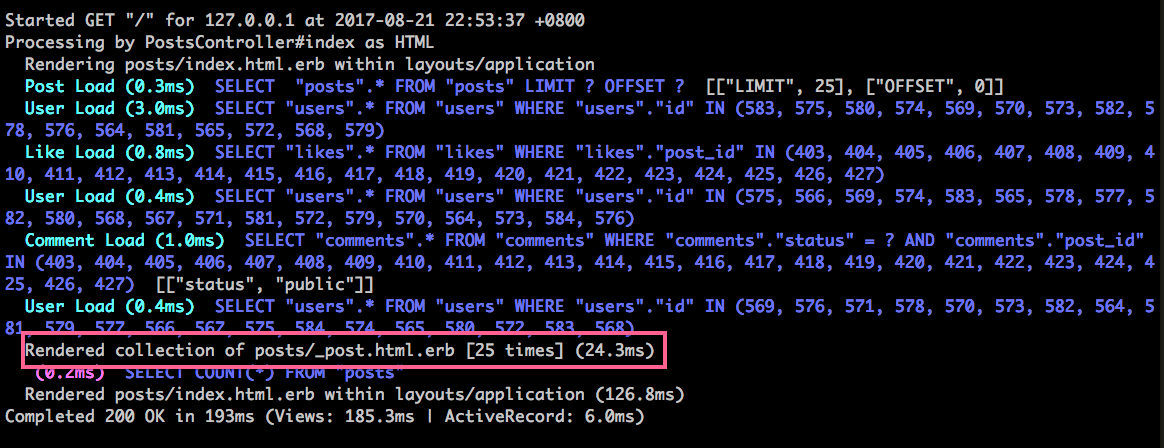
為什麽這種用法會比較快呢?本來的寫法 Rails 需要針對每個 partial 都做一次編譯處理,新的寫法 Rails 知道這些 partial 原來是同一個 partial,因此只需要編譯處理一次。
14. 資料庫索引
在資料庫教程中(在 SQL 語言: DML 這一章最後一節),我們有提到加上 Indexes 索引的重要,忘記幫資料庫加上索引也是常見的效能殺手,作為搜尋條件的欄位如果沒有加索引,SQL 查詢的時候就會一筆筆檢查資料表中的所有資料,當資料一多的時候相差的效能就十分巨大,沒索引是 O(N),有索引是 O(logN)。
一般來說,以下的欄位都必須記得加上索引:
- 外部鍵(Foreign key)
- 會被排序的欄位(被放在order方法中)
- 會被查詢的欄位(被放在where方法中)
- 會被group的欄位(被放在group方法中)
讓我們補上忘記的索引:
執行 rails g migration add_indexes
編輯 db/migrate/20170XXXXXXXXX_add_indexes.rb
class AddIndexes < ActiveRecord::Migration[5.1]
def change
+ add_index :comments, :status
+ add_index :comments, :post_id
+ add_index :likes, :post_id
+ add_index :likes, :user_id
+
+ add_index :subscriptions, :post_id
+ add_index :subscriptions, :user_id
end
end
執行 rake db:migrate
常見的效能錯誤
一個常犯的錯誤是用 created_at 來進行排序,例如想要依照新建時間排序,讓新的貼文在上面:
@posts = Post.order("created_at DESC").page(params[:page])
由於 created_at 這個欄位我們並沒有加上索引,如果你只是想要排序,應該改用 id 字串:
@posts = Post.order("id DESC").page(params[:page])
因為 id 是主鍵本身就有索引,而且它是自動遞增的數字。所以根據 id 來排序和根據 created_at 來排序結果是一樣的。
SQL explain 機制
對一個複雜的 SQL 查詢來說,有沒有索引到底有沒有派上用場?SQL 在資料庫中到底是如何運行的?需要實際用資料庫進行分析才會知道。
explain 這個方法可以調用資料庫的分析報告:
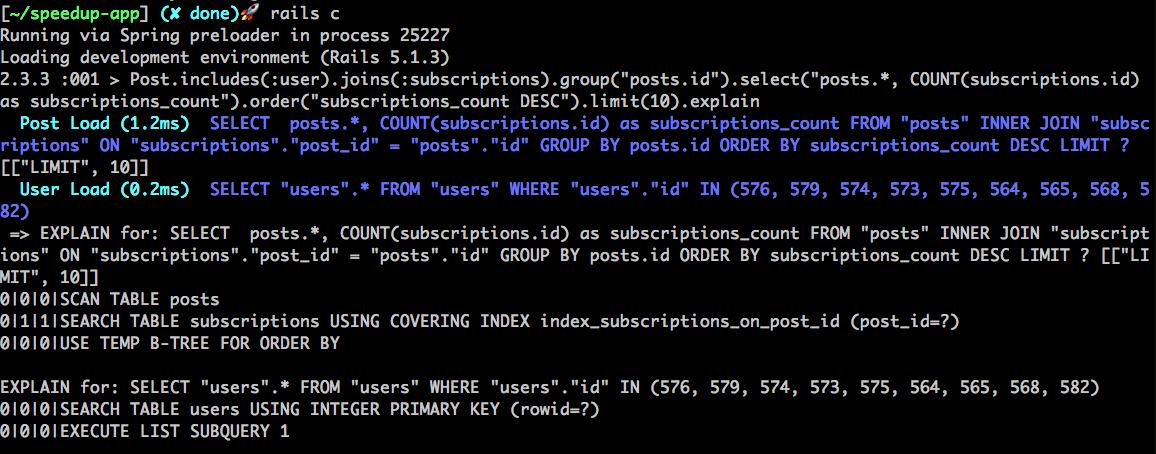
不同種的資料庫(SQLite、PostgreSQL、MySQL)的報告格式不一樣,這裡就不細說了。
15. 後端快取和延展性(Scalability)
記憶體快取
超高流量的網站會需要用到快取來進一步提升後端效能。本教程沒有提及如何做快取,有興趣的同學請直接看老師的Rails 實戰聖經。
快取是台灣術語,意思就是快取
網站延展性
另一個跟「網站效能(Performance)」常一起聽到的名詞是「網站延展性(Scalability)」。當網站的用戶越來越多,流量越來越大的時候,需要想辦法擴展網站的承載能力。
擴展的有兩種方式:
- 垂直擴展:升級伺服器,例如用更快的 CPU、用大的硬盤、用多的記憶體
- 水平擴展:增加(租用)更多伺服器
垂直擴展在初期比較簡單,因為網站代碼不需要變更,只需要原地硬體升級即可。但是硬體升級是有上限的,越高等級的伺服器越貴。CPU 再怎麽快,總不可能我們去租一臺超級電腦吧。
水平擴展則比較合乎成本,因為一百台平價的電腦,比起一臺超級電腦還便宜。但是水平擴展會需要網站架構的運維能力,對技術的要求比較高。
常見的網站架構演進,請參考 5 Common Server Setups For Your Web Application 這篇文章的圖例:

一開始只需要一臺伺服器

接下來將資料庫獨立成一臺伺服器

前面放一臺 Load Balancer 伺服器分散流量,這樣增加更多台應用伺服器(Application server,也就是我們的 Rails server)

前面再放 HTTP 快取伺服器

資料庫也需要拆分,可以分成 Master 和 Slave 資料庫,讀寫分離。
以上是還算是入門等級的架構,要繼續延展的話,就是另一門深似海的學問了。網站的延展性,就是去研究如何在合理的硬體成本下,透過水平擴展持續增加系統容量。這件事情跟 Rails 技術就比較沒有關系了。
參考資料
- https://www.schneems.com/2017/03/28/n1-queries-or-memory-problems-why-not-solve-both/
- https://code.tutsplus.com/articles/improving-the-performance-of-your-rails-app-with-eager-loading–cms-25018