9. Joining
SQL 查詢厲害的地方,就是可以同時關聯(Joining)多張表來進行複雜的查詢。讓我們先準備示範用的數據。
以下是 user 一對多 events 的情境,請執行 sqlite3 demo2.db,並輸入以下 SQL 建立 tables 和數據:
CREATE TABLE events (id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, name TEXT, capacity INTEGER, user_id INTEGER);
CREATE TABLE users (id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, name TEXT);
INSERT INTO users (name) VALUES ('ihower');
INSERT INTO users (name) VALUES ('john');
INSERT INTO users (name) VALUES ('roy');
INSERT INTO events (name, capacity, user_id) VALUES ('rubyconf',100, 1);
INSERT INTO events (name, capacity, user_id) VALUES ('jsconf', 200, 1);
INSERT INTO events (name, capacity, user_id) VALUES ('cssconf', 150, 2);
INSERT INTO events (name, capacity, user_id) VALUES ('htmlconf', 300, NULL);
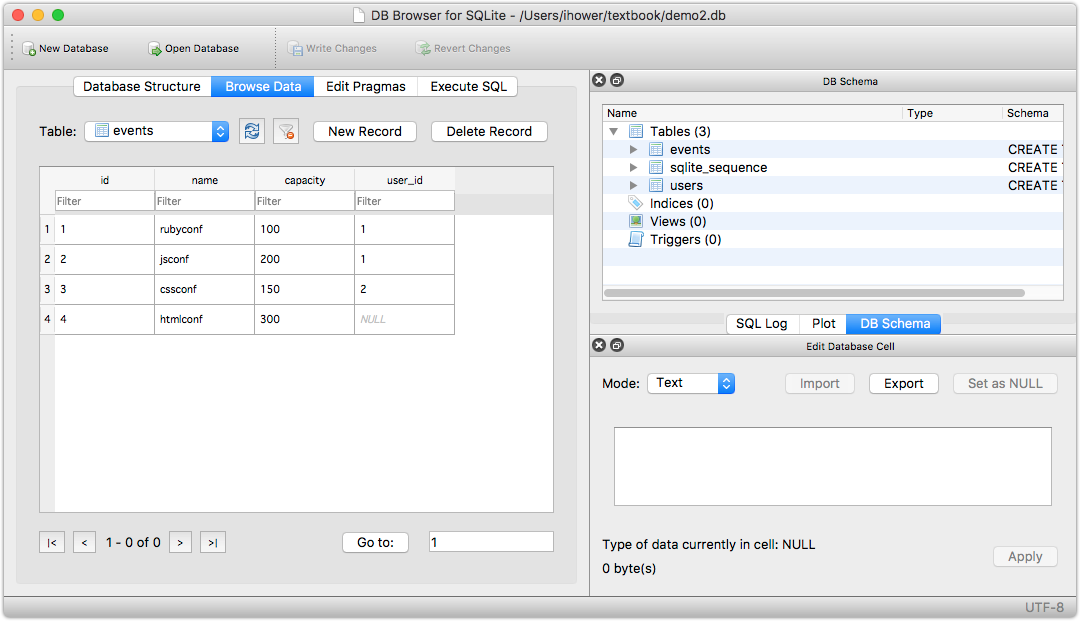
跨 Tables 進行 Joining 查詢,常用的有 Inner Joining 和 Left Outer Joining 兩種:
Inner joining 合並兩張 tables,接不起來就不要:
撈出所有活動,以及該活動的主辦人資料:
SELECT * FROM events INNER JOIN users ON events.user_id = users.id; 或 SELECT * FROM events, users WHERE events.user_id = users.id;
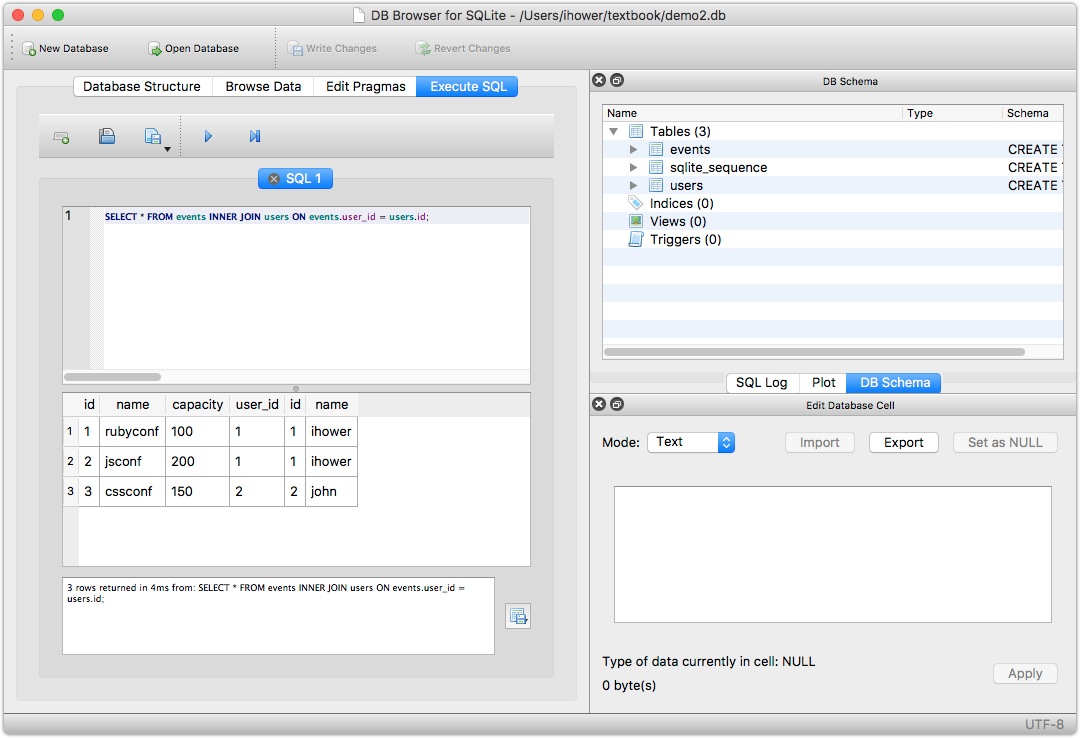
對應的 Rails 語法是
User.joins(:events)
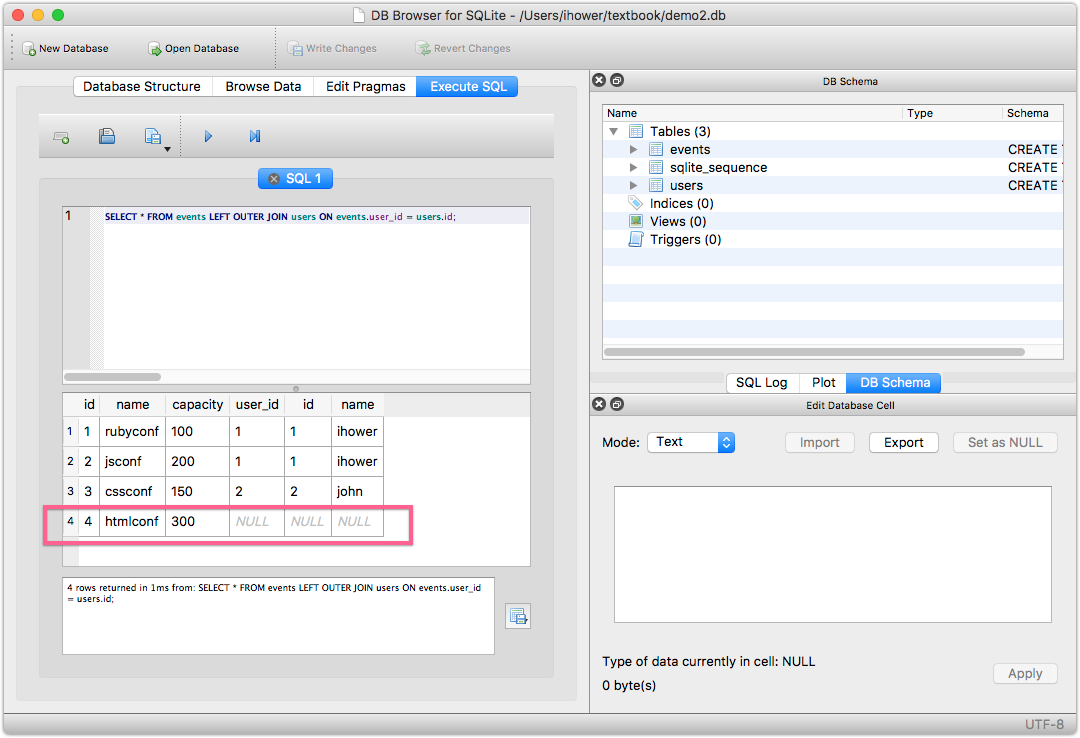
Outer joining 合並兩張 tables,接不起就填 NULL:
撈出所有活動,以及該活動的主辦人資料(包括沒有主辦人的活動):
SELECT * FROM events LEFT OUTER JOIN users ON events.user_id = users.id;
AS 語法
因為有多張 tables 在 SQL 時,column 最好必須加上 table name 當作 prefix (特別是有重復的 column name 時,在 WHERE 條件里可能會無法判斷),而且可以加上別名 AS。
例如 SELECT events.id AS event_id, events.capacity AS ec, events.name FROM events INNER JOIN users ON events.user_id = users.id WHERE ec=100;
Rails 的 includes 原理
Rails ActiveRecord 的 includes 方法(當沒有 WHERE 過濾條件時)則採用另一種 SQL 策略來作 Outer joining:
例如 Event.includes(:user) 這個 Rails 語法,實際上的 SQL 是:
SELECT * FROM events;
然後透過程式組合出所有的 user_id 成為 (1, 2, 3, 5, 9, 11, 14),然後再
SELECT * FROM users WHERE users.id IN (1, 2, 3, 5, 9, 11, 14);
不過,如果有 users 身上有 WHERE 條件的話,Rails 會變成 LEFT OUTER JOIN。
Joining 圖表
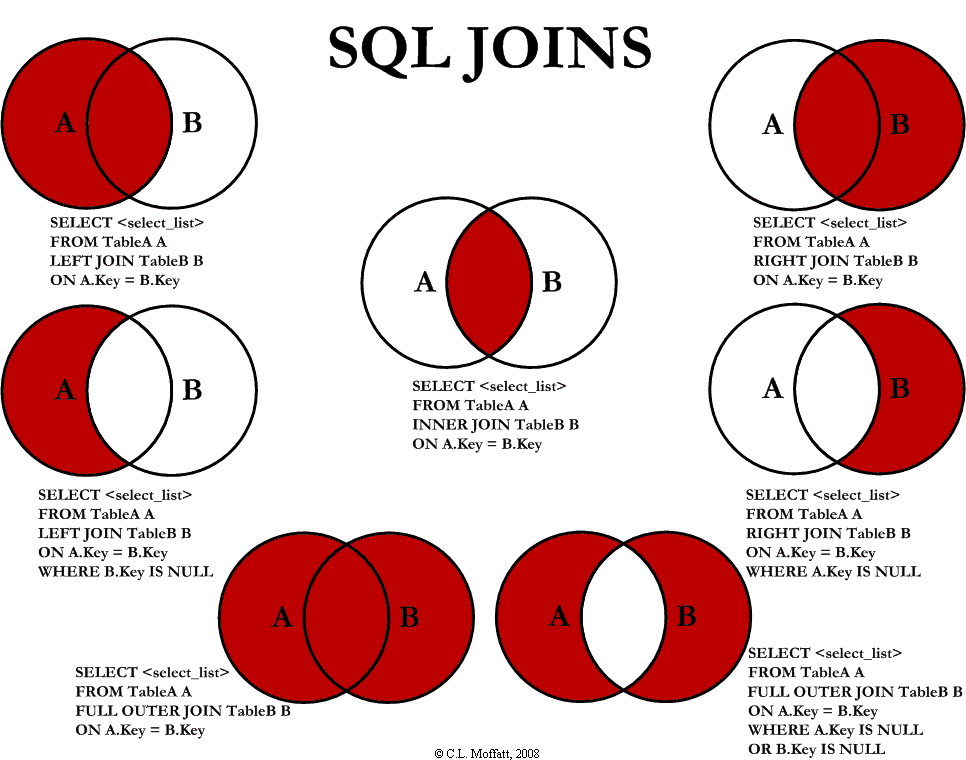
這張 google 比較常看到,出處 Visual Representation of SQL Joins
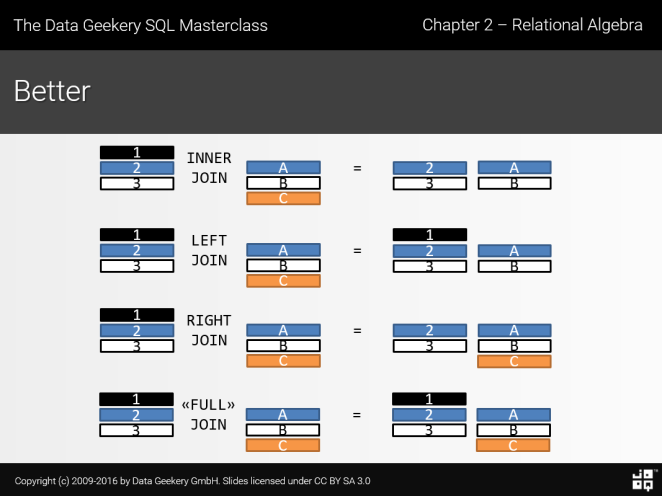
這張更清楚說明不同 Join 差別,出處SQL Joins Better
10. Functions
資料庫也有提供一些 Function 可以用在 SQL 裡面:
計算 Aggregations
數量
SELECT COUNT(*) AS event_count FROM events;
加上 AS 別名才比較好識別處理
對應的 Rails 語法是
Event.count
最小和最大值
SELECT MIN(capacity) as min_capacity FROM events; SELECT MAX(capacity) as max_capacity FROM events;
對應的 Rails 語法是
Event.minimum(:capacity)和Event.maximum(:capacity)
總和
SELECT SUM(capacity) as sum_capacity FROM events;
對應的 Rails 語法是
Event.sum(:capacity)
平均
SELECT SUM(capacity) / COUNT(capacity) as avg_capacity FROM events; 或 SELECT AVG(capacity) as avg_capacity FROM events;
對應的 Rails 語法是
Event.average(:capacity)
分類 GROUP BY
GROUP BY 分類功能主要是用來搭配上述 aggregating function 來使用的,例如請回答這個問題:計算每個 user 有多少 events?
讓我們試試看:
SELECT user_id, COUNT(*) FROM events;這樣不行,user_id 只會回傳第一筆的 user_idSELECT user_id, COUNT(*) FROM events GROUP BY user_id;還是不行,沒有 user 的名字SELECT users.name, COUNT(events.id) FROM events JOIN users ON users.id = events.user_id GROUP BY user_id;不對,結果少了 RoySELECT users.name, COUNT(events.id) FROM users LEFT JOIN events ON users.id = events.user_id GROUP BY user_id;正確答案SELECT users.name, COUNT(events.id) AS c FROM users LEFT JOIN events ON users.id = events.user_id GROUP BY user_id HAVING c > 1 ORDER BY c DESC;可再加條件和排序
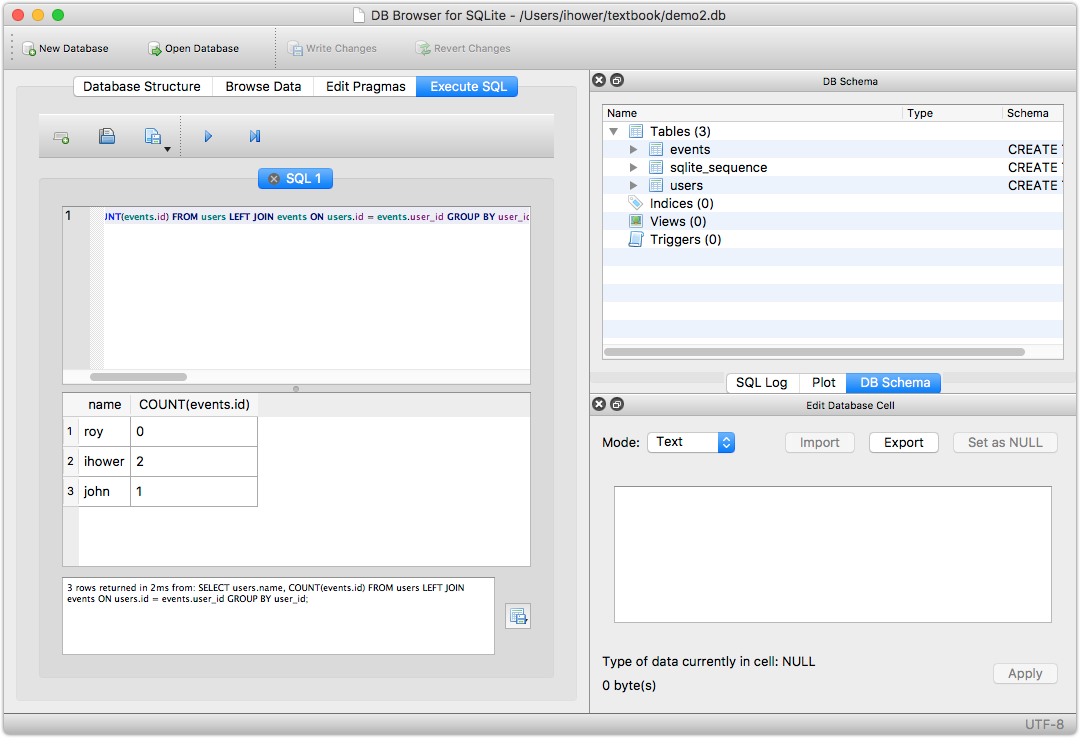
其中
WHERE是給 source tables 的條件,HAVING才是 aggregation 後的條件
DISTINCT
可以去除重復的數據
SELECT DISTINCT(user_id) FROM events;
其他函式
資料庫還有提供其他函數,例如 字串 SQLite - Useful Functions、時間 SQLite - Date And Time Functions 等等。
不過通常比較少用到,因為我們偏好撈出來數據後,交由 Ruby 處理即可。
為何要 Joining
回頭想想看為什麽需要 Joining 語法。SQL 的 Joining 語法是對新手比較困難的部分,沒辦法完全掌握是正常的。很多時候其實我們在 Rails 先將需要的數據通通撈出來,然後用 Ruby 進行過濾跟組合似乎也可以達成目標,為什麽需要用到這些看起來很複雜的 SQL Joining 語法呢?
主要的原因還是查詢速度和需要的內存空間,資料庫是一套針對 SQL 優化非常快速的軟體,因此可以用遠比 Ruby 高效的方式來取出數據。更何況如果全部的數據都拿出來用 Ruby 處理,很可能內存也不夠。例如以下的問題:請回答去年第三季所有商品的銷售額,並根據分類計算總額。去年一整年的銷售可能多達上百萬筆,如果要逐筆撈出用 Ruby 處理,效能會非常低下。這時候就必須用 SQL 精準地撈出想要的數據才是可行的方式。
11. NoSQL 簡介
世界上除了「關聯式」資料庫,還有其他另類不使用 SQL 的資料庫系統,泛稱 NoSQL。
這些 NoSQL 又可以分成幾個類型:
Key-value
Redis 可說是一種小型數據結構瑞士刀,作為搭配用的資料庫來使用。我們在實戰應用章節中用 sidekiq 實作非同步時看過它。
它的用途包括:
- 各式計數器:流量+1
- 簡易標記( 例如同一 IP 十分鐘內只算一次 pageview)
- 排行榜 zadd
- 自製 Inverted-Index Text Search
- Pub/Sub 聊天室
- Job Queue (例如 sidekiq)
主要是局部的、需要密集性寫入的功能,改用 Redis 來操作,來降低主資料庫的負擔。
Document-Oriented
MongoDB 是一種泛用型的資料庫,和 MySQL/PostgreSQL 打對台,特色是 Scheme-free 不需要定義 Schema。曾經有一陣子 Rails 社區非常流行,因為不需要用 Migration 去定義 Schema 就可以使用 Model,一開始用起來非常方便。不過後來大家發現營運久了以後,沒有 Schema 的數據會變臟,造成後續維運的成本增加。所以後來就沒這麽流行了。
Column-Oriented
關聯式資料庫的 Transaction 事務的缺點是效能。資料庫在做 Transaction 事務時,不可避免地必須鎖住一些數據,避免其他人同時修改。因此如果是一個寫入流量非常大的網站,就說是一個售票網站好了,非常多人在開票時準時搶票,這時候資料庫的效能就會非常差。
特別是當數據非常巨量的時候,需要多台資料庫伺服器時,Transaction 事務的寫入速度,就會成為擴充的瓶頸。
根據CAP 定理告訴我們: RDBMS 在多伺服器(P)架構下為了維持 C 特性,只能犧牲 A、NoSQL 讓你有 tradeoff 的空間,犧牲 C 特性以換得 A、但這不是 C 和 A 二元的選擇,而是 C 和 delay 延遲時間的取捨,你願意容忍多少延遲時間才算作不 Available。
因此這類型的 NoSQL 不講 ACID,而是講 BASE 特性 (Basically Available, Soft state, Eventual consistency),重點是 Eventual consistency。想像一個場景: Facebook 和 Twitter 貼文,當你貼文成功的時候,並不是當下馬上其他人就可以看到你的貼文,這中間其實是有延遲時間的。這個延遲對於關聯式資料庫來說是不可以接受的,但是對於這種社交應用來說,卻沒有關系。犧牲 Consistence 一致性,就可以換到更多的寫入反應效能,這就是這類型的 NoSQL 的設計目的。
- Apache HBase 分佈式、強調超大 Table: billions of rows X millions of columns (PB以上等級) (Google Big Table 的開源版本,由 Yahoo 推出)
- Apache Cassandra 分佈式、最終一致性,高寫入場景 (Amazon Dynamo 的開源版本,由 Facebook 推出)
- Amazon DynamoDB
- Google Cloud Datastore
如果你的數據量不到 1PB (=1000TB),你就不需要考慮這類型的資料庫了,用 MySQL 或 PostgreSQL 足矣。
Graph: neo4j 圖形資料庫
neo4j 用節點和邊來儲存數據
12. 其他沒有介紹到的資料庫功能
- Sub Query (Sub Select)
- Select 的結果也是 table,可以放到另一個 SQL 句子裡面
- 例如: 計算每個使用者的最大活動容量的平均
SELECT AVG(mec) FROM ( SELECT MAX(capacity) AS mec FROM events GROUP BY user_id );
- Trigger
- Views
- A view 是一個預先設定好的 select query,可以當作 table 使用
- 就像是將 sub query 抽出來成為設定好的 view 可以重複使用
- Database replication 架構
- Master-Slave
- Multi-master, Cluster
13. SQL 參考資料和更多教程
網絡上關於 SQL 的教程非常多,以下列出一些可以繼續進修學習:
- Udacity: Intro to Relational Databases (有簡中字幕),建議看 Lesson 1, 2, 4,不用看 Lesson 3: Python DB-API 和 Lesson 5: Final Project。
- LaunchSchool: Introduction to SQL
- Learn SQL
- SQL: Analyzing Business Metrics
- SQL Tutorial
- A Tiny Intro to Database Systems
- Enterprise Rails: 資料庫篇 關於 Rails 使用 RDBMS 的補充
- The SQL Tutorial for Data Analysis
- Intro to SQL: Querying and managing data
- NoSQL distilled 搞懂 NoSQL 的 15 堂課